 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamicRTL: RTL Representation Learning for Dynamic Circuit Behavior
Nov 12, 2025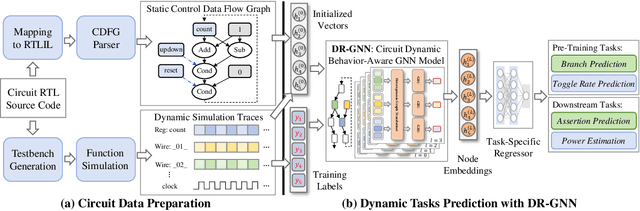

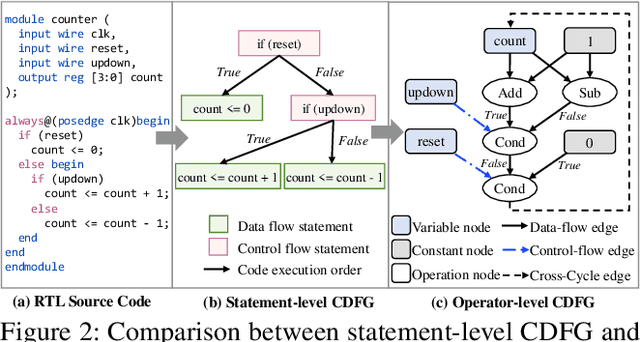

There is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of circuits, focusing primarily on their static characteristics. However, these models fail to capture circuit runtime behavior, which is crucial for tasks like circuit verification and optimization. To address this limitation, we introduce DR-GNN (DynamicRTL-GNN), a novel approach that learns RTL circuit representations by incorporating both static structures and multi-cycle execution behaviors. DR-GNN leverages an operator-level Control Data Flow Graph (CDFG) to represent Register Transfer Level (RTL) circuits, enabling the model to capture dynamic dependencies and runtime execution. To train and evaluate DR-GNN, we build the first comprehensive dynamic circuit dataset, comprising over 6,300 Verilog designs and 63,000 simulation traces. Our results demonstrate that DR-GNN outperforms existing models in branch hit prediction and toggle rate prediction. Furthermore, its learned representations transfer effectively to related dynamic circuit tasks, achieving strong performance in power estimation and assertion prediction.
Understanding and Exploiting Plasticity for Non-stationary Network Resource Adaptation
May 02, 2025



Adapting to non-stationary network conditions presents significant challenges for resource adaptation. However, current solutions primarily rely on stationary assumptions. While data-driven reinforcement learning approaches offer promising solutions for handling network dynamics, our systematic investigation reveals a critical limitation: neural networks suffer from plasticity loss, significantly impeding their ability to adapt to evolving network conditions. Through theoretical analysis of neural propagation mechanisms, we demonstrate that existing dormant neuron metrics inadequately characterize neural plasticity loss. To address this limitation, we have developed the Silent Neuron theory, which provides a more comprehensive framework for understanding plasticity degradation. Based on these theoretical insights, we propose the Reset Silent Neuron (ReSiN), which preserves neural plasticity through strategic neuron resets guided by both forward and backward propagation states. In our implementation of an adaptive video streaming system, ReSiN has shown significant improvements over existing solutions, achieving up to 168% higher bitrate and 108% better quality of experience (QoE) while maintaining comparable smoothness. Furthermore, ReSiN consistently outperforms in stationary environments, demonstrating its robust adaptability across different network conditions.
Plasticity-Aware Mixture of Experts for Learning Under QoE Shifts in Adaptive Video Streaming
Apr 14, 2025Adaptive video streaming systems are designed to optimize Quality of Experience (QoE) and, in turn, enhance user satisfaction. However, differences in user profiles and video content lead to different weights for QoE factors, resulting in user-specific QoE functions and, thus, varying optimization objectives. This variability poses significant challenges for neural networks, as they often struggle to generalize under evolving targets - a phenomenon known as plasticity loss that prevents conventional models from adapting effectively to changing optimization objectives. To address this limitation, we propose the Plasticity-Aware Mixture of Experts (PA-MoE), a novel learning framework that dynamically modulates network plasticity by balancing memory retention with selective forgetting. In particular, PA-MoE leverages noise injection to promote the selective forgetting of outdated knowledge, thereby endowing neural networks with enhanced adaptive capabilities. In addition, we present a rigorous theoretical analysis of PA-MoE by deriving a regret bound that quantifies its learning performance. Experimental evaluations demonstrate that PA-MoE achieves a 45.5% improvement in QoE over competitive baselines in dynamic streaming environments. Further analysis reveals that the model effectively mitigates plasticity loss by optimizing neuron utilization. Finally, a parameter sensitivity study is performed by injecting varying levels of noise, and the results align closely with our theoretical predictions.
DomainVerse: A Benchmark Towards Real-World Distribution Shifts For Tuning-Free Adaptive Domain Generalization
Mar 05, 2024Traditional cross-domain tasks, including domain adaptation and domain generalization, rely heavily on training model by source domain data. With the recent advance of vision-language models (VLMs), viewed as natural source models, the cross-domain task changes to directly adapt the pre-trained source model to arbitrary target domains equipped with prior domain knowledge, and we name this task Adaptive Domain Generalization (ADG). However, current cross-domain datasets have many limitations, such as unrealistic domains, unclear domain definitions, and the inability to fine-grained domain decomposition, which drives us to establish a novel dataset DomainVerse for ADG. Benefiting from the introduced hierarchical definition of domain shifts, DomainVerse consists of about 0.5 million images from 390 fine-grained realistic domains. With the help of the constructed DomainVerse and VLMs, we propose two methods called Domain CLIP and Domain++ CLIP for tuning-free adaptive domain generalization. Extensive and comprehensive experiments demonstrate the significance of the dataset and the effectiveness of the proposed methods.
Unleashing the Power of Graph Learning through LLM-based Autonomous Agents
Sep 08, 2023Graph structured data are widely existed and applied in the real-world applications, while it is a challenge to handling these diverse data and learning tasks on graph in an efficient manner. When facing the complicated graph learning tasks, experts have designed diverse Graph Neural Networks (GNNs) in recent years. They have also implemented AutoML in Graph, also known as AutoGraph, to automatically generate data-specific solutions. Despite their success, they encounter limitations in (1) managing diverse learning tasks at various levels, (2) dealing with different procedures in graph learning beyond architecture design, and (3) the huge requirements on the prior knowledge when using AutoGraph. In this paper, we propose to use Large Language Models (LLMs) as autonomous agents to simplify the learning process on diverse real-world graphs. Specifically, in response to a user request which may contain varying data and learning targets at the node, edge, or graph levels, the complex graph learning task is decomposed into three components following the agent planning, namely, detecting the learning intent, configuring solutions based on AutoGraph, and generating a response. The AutoGraph agents manage crucial procedures in automated graph learning, including data-processing, AutoML configuration, searching architectures, and hyper-parameter fine-tuning. With these agents, those components are processed by decomposing and completing step by step, thereby generating a solution for the given data automatically, regardless of the learning task on node or graph. The proposed method is dubbed Auto$^2$Graph, and the comparable performance on different datasets and learning tasks. Its effectiveness is demonstrated by its comparable performance on different datasets and learning tasks, as well as the human-like decisions made by the agents.
Search to Capture Long-range Dependency with Stacking GNNs for Graph Classification
Feb 17, 2023In recent years, Graph Neural Networks (GNNs) have been popular in the graph classification task. Currently, shallow GNNs are more common due to the well-known over-smoothing problem facing deeper GNNs. However, they are sub-optimal without utilizing the information from distant nodes, i.e., the long-range dependencies. The mainstream methods in the graph classification task can extract the long-range dependencies either by designing the pooling operations or incorporating the higher-order neighbors, while they have evident drawbacks by modifying the original graph structure, which may result in information loss in graph structure learning. In this paper, by justifying the smaller influence of the over-smoothing problem in the graph classification task, we evoke the importance of stacking-based GNNs and then employ them to capture the long-range dependencies without modifying the original graph structure. To achieve this, two design needs are given for stacking-based GNNs, i.e., sufficient model depth and adaptive skip-connection schemes. By transforming the two design needs into designing data-specific inter-layer connections, we propose a novel approach with the help of neural architecture search (NAS), which is dubbed LRGNN (Long-Range Graph Neural Networks). Extensive experiments on five datasets show that the proposed LRGNN can achieve the best performance, and obtained data-specific GNNs with different depth and skip-connection schemes, which can better capture the long-range dependencies.
Enhancing Intra-class Information Extraction for Heterophilous Graphs: One Neural Architecture Search Approach
Nov 20, 2022



In recent years, Graph Neural Networks (GNNs) have been popular in graph representation learning which assumes the homophily property, i.e., the connected nodes have the same label or have similar features. However, they may fail to generalize into the heterophilous graphs which in the low/medium level of homophily. Existing methods tend to address this problem by enhancing the intra-class information extraction, i.e., either by designing better GNNs to improve the model effectiveness, or re-designing the graph structures to incorporate more potential intra-class nodes from distant hops. Despite the success, we observe two aspects that can be further improved: (a) enhancing the ego feature information extraction from node itself which is more reliable in extracting the intra-class information; (b) designing node-wise GNNs can better adapt to the nodes with different homophily ratios. In this paper, we propose a novel method IIE-GNN (Intra-class Information Enhanced Graph Neural Networks) to achieve two improvements. A unified framework is proposed based on the literature, in which the intra-class information from the node itself and neighbors can be extracted based on seven carefully designed blocks. With the help of neural architecture search (NAS), we propose a novel search space based on the framework, and then provide an architecture predictor to design GNNs for each node. We further conduct experiments to show that IIE-GNN can improve the model performance by designing node-wise GNNs to enhance intra-class information extraction.
Learning to Learn Domain-invariant Parameters for Domain Generalization
Nov 04, 2022Due to domain shift, deep neural networks (DNNs) usually fail to generalize well on unknown test data in practice. Domain generalization (DG) aims to overcome this issue by capturing domain-invariant representations from source domains. Motivated by the insight that only partial parameters of DNNs are optimized to extract domain-invariant representations, we expect a general model that is capable of well perceiving and emphatically updating such domain-invariant parameters. In this paper, we propose two modules of Domain Decoupling and Combination (DDC) and Domain-invariance-guided Backpropagation (DIGB), which can encourage such general model to focus on the parameters that have a unified optimization direction between pairs of contrastive samples. Our extensive experiments on two benchmarks have demonstrated that our proposed method has achieved state-of-the-art performance with strong generalization capability.
SAP-DETR: Bridging the Gap Between Salient Points and Queries-Based Transformer Detector for Fast Model Convergency
Nov 03, 2022Recently, the dominant DETR-based approaches apply central-concept spatial prior to accelerate Transformer detector convergency. These methods gradually refine the reference points to the center of target objects and imbue object queries with the updated central reference information for spatially conditional attention. However, centralizing reference points may severely deteriorate queries' saliency and confuse detectors due to the indiscriminative spatial prior. To bridge the gap between the reference points of salient queries and Transformer detectors, we propose SAlient Point-based DETR (SAP-DETR) by treating object detection as a transformation from salient points to instance objects. In SAP-DETR, we explicitly initialize a query-specific reference point for each object query, gradually aggregate them into an instance object, and then predict the distance from each side of the bounding box to these points. By rapidly attending to query-specific reference region and other conditional extreme regions from the image features, SAP-DETR can effectively bridge the gap between the salient point and the query-based Transformer detector with a significant convergency speed. Our extensive experiments have demonstrated that SAP-DETR achieves 1.4 times convergency speed with competitive performance. Under the standard training scheme, SAP-DETR stably promotes the SOTA approaches by 1.0 AP. Based on ResNet-DC-101, SAP-DETR achieves 46.9 AP.
Deep Learning-based Occluded Person Re-identification: A Survey
Jul 29, 2022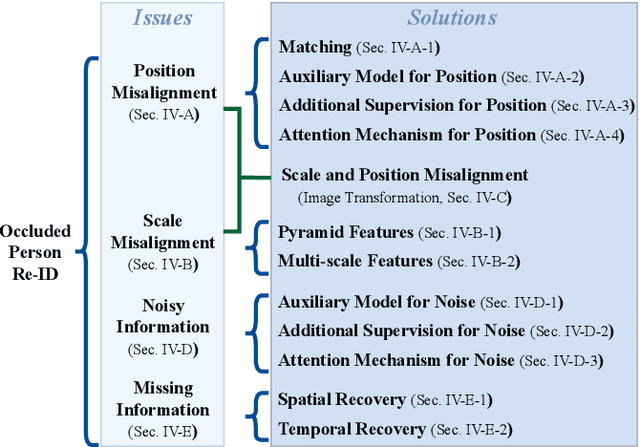
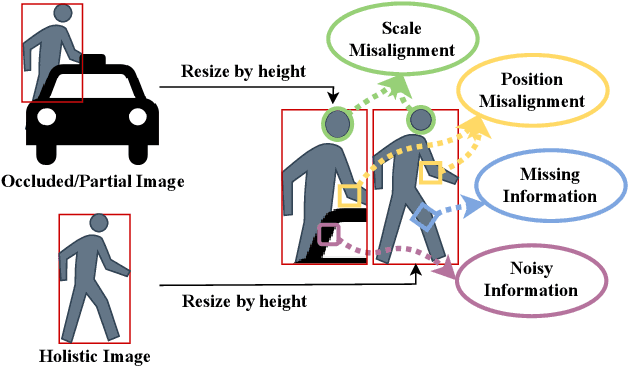

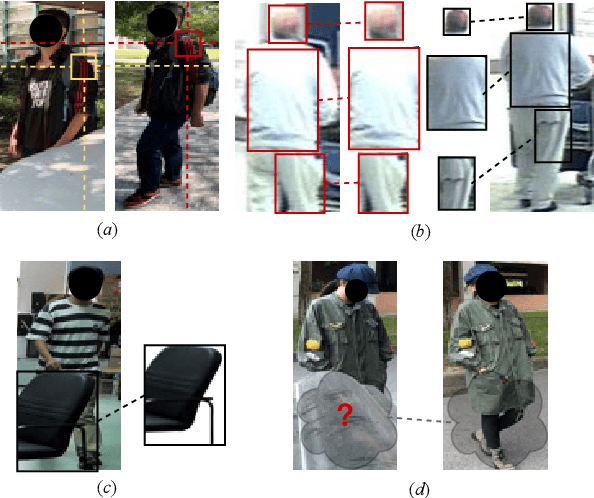
Occluded person re-identification (Re-ID) aims at addressing the occlusion problem when retrieving the person of interest across multiple cameras. With the promotion of deep learning technology and the increasing demand for intelligent video surveillance, the frequent occlusion in real-world applications has made occluded person Re-ID draw considerable interest from researchers. A large number of occluded person Re-ID methods have been proposed while there are few surveys that focus on occlusion. To fill this gap and help boost future research, this paper provides a systematic survey of occluded person Re-ID. Through an in-depth analysis of the occlusion in person Re-ID, most existing methods are found to only consider part of the problems brought by occlusion. Therefore, we review occlusion-related person Re-ID methods from the perspective of issues and solutions. We summarize four issues caused by occlusion in person Re-ID, i.e., position misalignment, scale misalignment, noisy information, and missing information. The occlusion-related methods addressing different issues are then categorized and introduced accordingly. After that, we summarize and compare the performance of recent occluded person Re-ID methods on four popular datasets: Partial-ReID, Partial-iLIDS, Occluded-ReID, and Occluded-DukeMTMC. Finally, we provide insights on promising future research directions.