 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomainVerse: A Benchmark Towards Real-World Distribution Shifts For Tuning-Free Adaptive Domain Generalization
Mar 05, 2024Traditional cross-domain tasks, including domain adaptation and domain generalization, rely heavily on training model by source domain data. With the recent advance of vision-language models (VLMs), viewed as natural source models, the cross-domain task changes to directly adapt the pre-trained source model to arbitrary target domains equipped with prior domain knowledge, and we name this task Adaptive Domain Generalization (ADG). However, current cross-domain datasets have many limitations, such as unrealistic domains, unclear domain definitions, and the inability to fine-grained domain decomposition, which drives us to establish a novel dataset DomainVerse for ADG. Benefiting from the introduced hierarchical definition of domain shifts, DomainVerse consists of about 0.5 million images from 390 fine-grained realistic domains. With the help of the constructed DomainVerse and VLMs, we propose two methods called Domain CLIP and Domain++ CLIP for tuning-free adaptive domain generalization. Extensive and comprehensive experiments demonstrate the significance of the dataset and the effectiveness of the proposed methods.
PhasePerturbation: Speech Data Augmentation via Phase Perturbation for Automatic Speech Recognition
Dec 13, 2023Most of the current speech data augmentation methods operate on either the raw waveform or the amplitude spectrum of speech. In this paper, we propose a novel speech data augmentation method called PhasePerturbation that operates dynamically on the phase spectrum of speech. Instead of statically rotating a phase by a constant degree, PhasePerturbation utilizes three dynamic phase spectrum operations, i.e., a randomization operation, a frequency masking operation, and a temporal masking operation, to enhance the diversity of speech data. We conduct experiments on wav2vec2.0 pre-trained ASR models by fine-tuning them with the PhasePerturbation augmented TIMIT corpus. The experimental results demonstrate 10.9\% relative reduction in the word error rate (WER) compared with the baseline model fine-tuned without any augmentation operation. Furthermore, the proposed method achieves additional improvements (12.9\% and 15.9\%) in WER by complementing the Vocal Tract Length Perturbation (VTLP) and the SpecAug, which are both amplitude spectrum-based augmentation methods. The results highlight the capability of PhasePerturbation to improve the current amplitude spectrum-based augmentation methods.
A Novel Self-training Approach for Low-resource Speech Recognition
Aug 10, 2023In this paper, we propose a self-training approach for automatic speech recognition (ASR) for low-resource settings. While self-training approaches have been extensively developed and evaluated for high-resource languages such as English, their applications to low-resource languages like Punjabi have been limited, despite the language being spoken by millions globally. The scarcity of annotated data has hindered the development of accurate ASR systems, especially for low-resource languages (e.g., Punjabi and M\=aori languages). To address this issue, we propose an effective self-training approach that generates highly accurate pseudo-labels for unlabeled low-resource speech. Our experimental analysis demonstrates that our approach significantly improves word error rate, achieving a relative improvement of 14.94% compared to a baseline model across four real speech datasets. Further, our proposed approach reports the best results on the Common Voice Punjabi dataset.
How to Design Translation Prompts for ChatGPT: An Empirical Study
Apr 21, 2023The recently released ChatGPT has demonstrated surprising abilities in natural language understanding and natural language generation. Machine translation relies heavily on the abilities of language understanding and generation. Thus, in this paper, we explore how to assist machine translation with ChatGPT. We adopt several translation prompts on a wide range of translations. Our experimental results show that ChatGPT with designed translation prompts can achieve comparable or better performance over commercial translation systems for high-resource language translations. We further evaluate the translation quality using multiple references, and ChatGPT achieves superior performance compared to commercial systems. We also conduct experiments on domain-specific translations, the final results show that ChatGPT is able to comprehend the provided domain keyword and adjust accordingly to output proper translations. At last, we perform few-shot prompts that show consistent improvement across different base prompts. Our work provides empirical evidence that ChatGPT still has great potential in translations.
Learning to Learn Domain-invariant Parameters for Domain Generalization
Nov 04, 2022Due to domain shift, deep neural networks (DNNs) usually fail to generalize well on unknown test data in practice. Domain generalization (DG) aims to overcome this issue by capturing domain-invariant representations from source domains. Motivated by the insight that only partial parameters of DNNs are optimized to extract domain-invariant representations, we expect a general model that is capable of well perceiving and emphatically updating such domain-invariant parameters. In this paper, we propose two modules of Domain Decoupling and Combination (DDC) and Domain-invariance-guided Backpropagation (DIGB), which can encourage such general model to focus on the parameters that have a unified optimization direction between pairs of contrastive samples. Our extensive experiments on two benchmarks have demonstrated that our proposed method has achieved state-of-the-art performance with strong generalization capability.
Improved Meta Learning for Low Resource Speech Recognition
May 11, 2022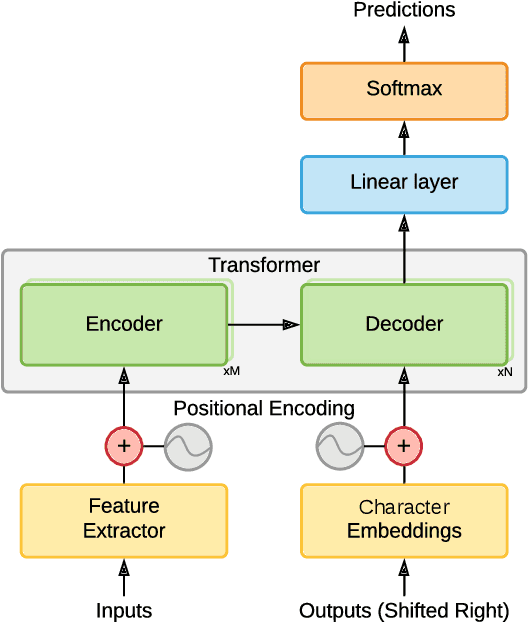
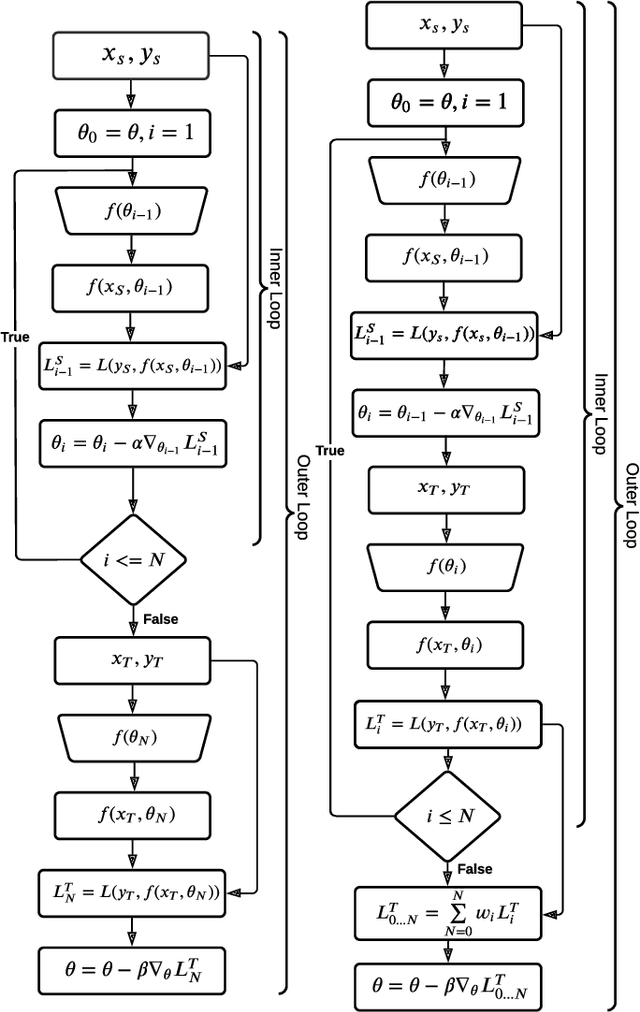

We propose a new meta learning based framework for low resource speech recognition that improves the previous model agnostic meta learning (MAML) approach. The MAML is a simple yet powerful meta learning approach. However, the MAML presents some core deficiencies such as training instabilities and slower convergence speed. To address these issues, we adopt multi-step loss (MSL). The MSL aims to calculate losses at every step of the inner loop of MAML and then combines them with a weighted importance vector. The importance vector ensures that the loss at the last step has more importance than the previous steps. Our empirical evaluation shows that MSL significantly improves the stability of the training procedure and it thus also improves the accuracy of the overall system. Our proposed system outperforms MAML based low resource ASR system on various languages in terms of character error rates and stable training behavior.
* Published in IEEE ICASSP 2022
Self-Supervised Graph Neural Network for Multi-Source Domain Adaptation
Apr 08, 2022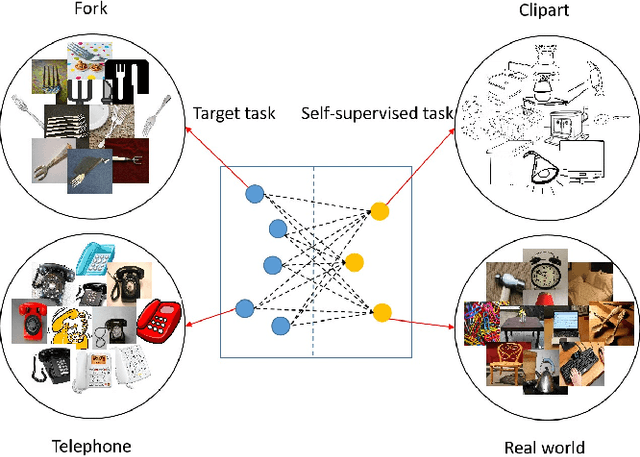
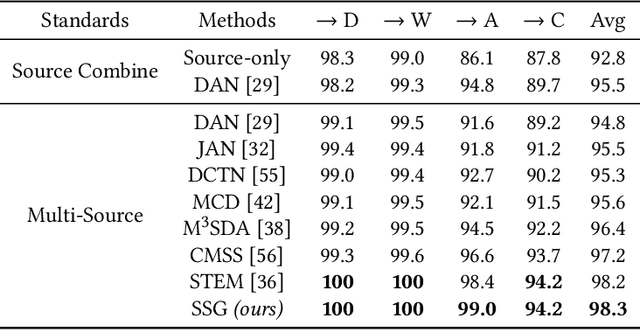
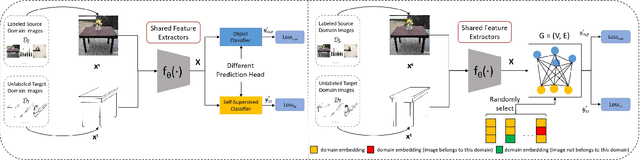
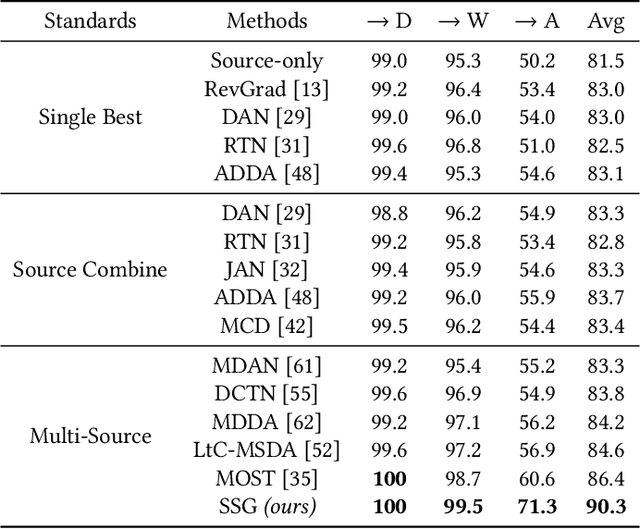
Domain adaptation (DA) tries to tackle the scenarios when the test data does not fully follow the same distribution of the training data, and multi-source domain adaptation (MSDA) is very attractive for real world applications. By learning from large-scale unlabeled samples, self-supervised learning has now become a new trend in deep learning. It is worth noting that both self-supervised learning and multi-source domain adaptation share a similar goal: they both aim to leverage unlabeled data to learn more expressive representations. Unfortunately, traditional multi-task self-supervised learning faces two challenges: (1) the pretext task may not strongly relate to the downstream task, thus it could be difficult to learn useful knowledge being shared from the pretext task to the target task; (2) when the same feature extractor is shared between the pretext task and the downstream one and only different prediction heads are used, it is ineffective to enable inter-task information exchange and knowledge sharing. To address these issues, we propose a novel \textbf{S}elf-\textbf{S}upervised \textbf{G}raph Neural Network (SSG), where a graph neural network is used as the bridge to enable more effective inter-task information exchange and knowledge sharing. More expressive representation is learned by adopting a mask token strategy to mask some domain information. Our extensive experiments have demonstrated that our proposed SSG method has achieved state-of-the-art results over four multi-source domain adaptation datasets, which have shown the effectiveness of our proposed SSG method from different aspects.
A Survey of Visual Transformers
Nov 13, 2021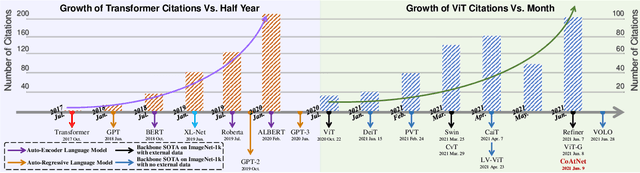
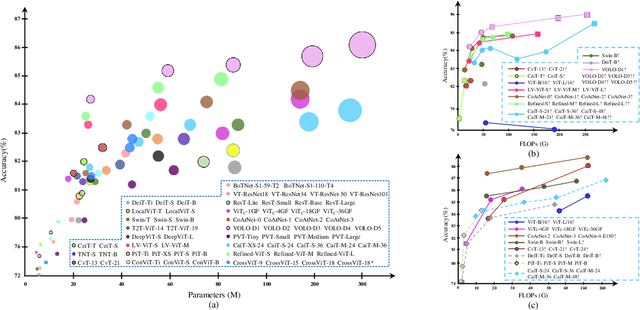
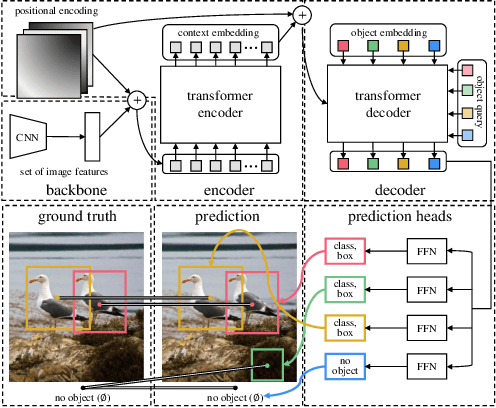
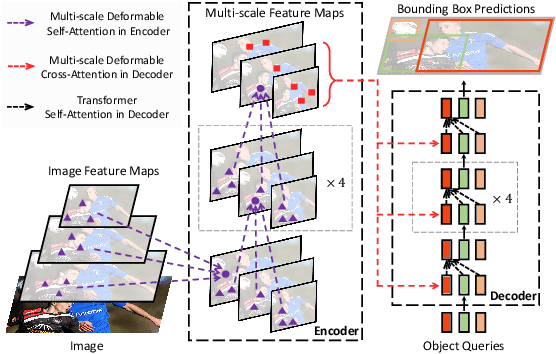
Transformer, an attention-based encoder-decoder architecture, has revolutionized the field of natural language processing. Inspired by this significant achievement, some pioneering works have recently been done on adapting Transformerliked architectures to Computer Vision (CV) fields, which have demonstrated their effectiveness on various CV tasks. Relying on competitive modeling capability, visual Transformers have achieved impressive performance on multiple benchmarks such as ImageNet, COCO, and ADE20k as compared with modern Convolution Neural Networks (CNN). In this paper, we have provided a comprehensive review of over one hundred different visual Transformers for three fundamental CV tasks (classification, detection, and segmentation), where a taxonomy is proposed to organize these methods according to their motivations, structures, and usage scenarios. Because of the differences in training settings and oriented tasks, we have also evaluated these methods on different configurations for easy and intuitive comparison instead of only various benchmarks. Furthermore, we have revealed a series of essential but unexploited aspects that may empower Transformer to stand out from numerous architectures, e.g., slack high-level semantic embeddings to bridge the gap between visual and sequential Transformers. Finally, three promising future research directions are suggested for further investment.
Improving Entity Linking through Semantic Reinforced Entity Embeddings
Jun 16, 2021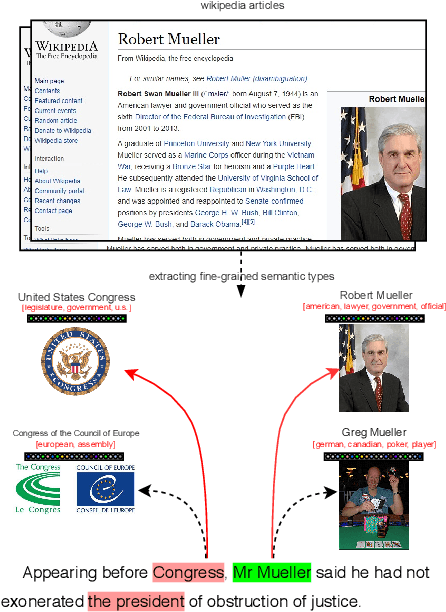

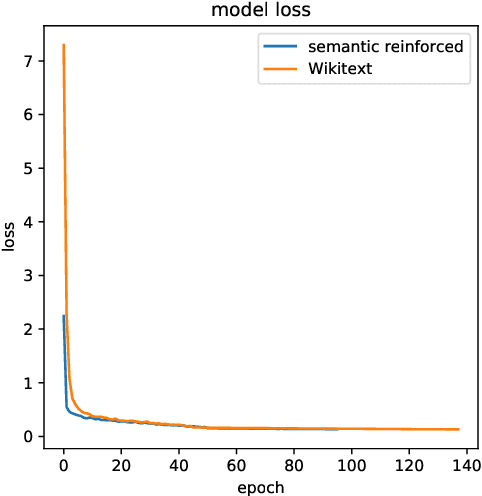
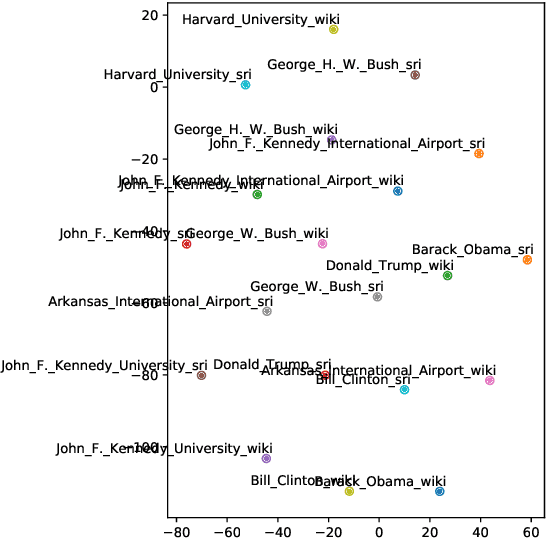
Entity embeddings, which represent different aspects of each entity with a single vector like word embeddings, are a key component of neural entity linking models. Existing entity embeddings are learned from canonical Wikipedia articles and local contexts surrounding target entities. Such entity embeddings are effective, but too distinctive for linking models to learn contextual commonality. We propose a simple yet effective method, FGS2EE, to inject fine-grained semantic information into entity embeddings to reduce the distinctiveness and facilitate the learning of contextual commonality. FGS2EE first uses the embeddings of semantic type words to generate semantic embeddings, and then combines them with existing entity embeddings through linear aggregation. Extensive experiments show the effectiveness of such embeddings. Based on our entity embeddings, we achieved new sate-of-the-art performance on entity linking.
* 6 pages, 3 figures, ACL 2020
Semi-supervised Cardiac Image Segmentation via Label Propagation and Style Transfer
Dec 29, 2020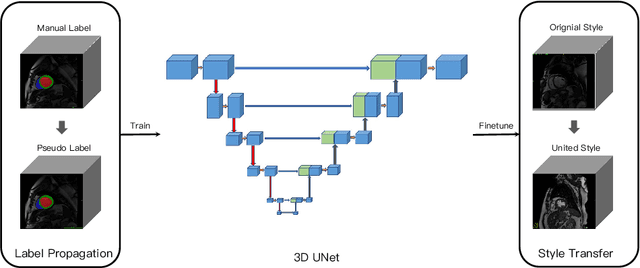
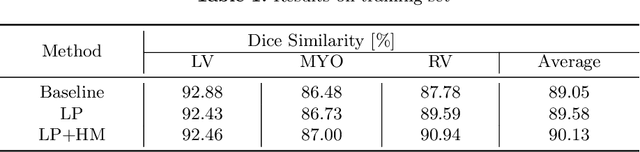
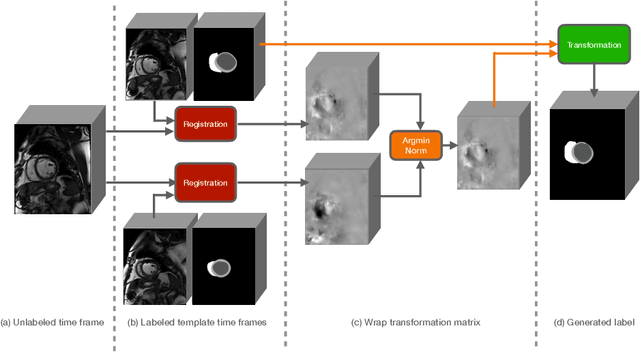

Accurate segmentation of cardiac structures can assist doctors to diagnose diseases, and to improve treatment planning, which is highly demanded in the clinical practice. However, the shortage of annotation and the variance of the data among different vendors and medical centers restrict the performance of advanced deep learning methods. In this work, we present a fully automatic method to segment cardiac structures including the left (LV) and right ventricle (RV) blood pools, as well as for the left ventricular myocardium (MYO) in MRI volumes. Specifically, we design a semi-supervised learning method to leverage unlabelled MRI sequence timeframes by label propagation. Then we exploit style transfer to reduce the variance among different centers and vendors for more robust cardiac image segmentation. We evaluate our method in the M&Ms challenge 7 , ranking 2nd place among 14 competitive teams.