 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Representation Learning via Epistemic Graph
May 31, 2023In recent years, deep models have achieved remarkable success in many vision tasks. Unfortunately, their performance largely depends on intensive training samples. In contrast, human beings typically perform hybrid learning, e.g., spontaneously integrating structured knowledge for cross-domain recognition or on a much smaller amount of data samples for few-shot learning. Thus it is very attractive to extend hybrid learning for the computer vision tasks by seamlessly integrating structured knowledge with data samples to achieve more effective representation learning. However, such a hybrid learning approach remains a great challenge due to the huge gap between the structured knowledge and the deep features (learned from data samples) on both dimensions and knowledge granularity. In this paper, a novel Epistemic Graph Layer (EGLayer) is developed to enable hybrid learning, such that the information can be exchanged more effectively between the deep features and a structured knowledge graph. Our EGLayer is composed of three major parts: (a) a local graph module to establish a local prototypical graph through the learned deep features, i.e., aligning the deep features with the structured knowledge graph at the same granularity; (b) a query aggregation model to aggregate useful information from the local graphs, and using such representations to compute their similarity with global node embeddings for final prediction; and (c) a novel correlation loss function to constrain the linear consistency between the local and global adjacency matrices.
TaxoKnow: Taxonomy as Prior Knowledge in the Loss Function of Multi-class Classification
May 24, 2023In this paper, we investigate the effectiveness of integrating a hierarchical taxonomy of labels as prior knowledge into the learning algorithm of a flat classifier. We introduce two methods to integrate the hierarchical taxonomy as an explicit regularizer into the loss function of learning algorithms. By reasoning on a hierarchical taxonomy, a neural network alleviates its output distributions over the classes, allowing conditioning on upper concepts for a minority class. We limit ourselves to the flat classification task and provide our experimental results on two industrial in-house datasets and two public benchmarks, RCV1 and Amazon product reviews. Our obtained results show the significant effect of a taxonomy in increasing the performance of a learner in semisupervised multi-class classification and the considerable results obtained in a fully supervised fashion.
Self-Supervised Graph Neural Network for Multi-Source Domain Adaptation
Apr 08, 2022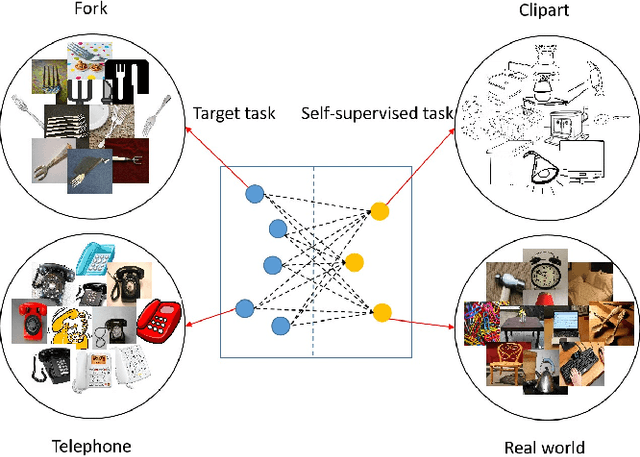
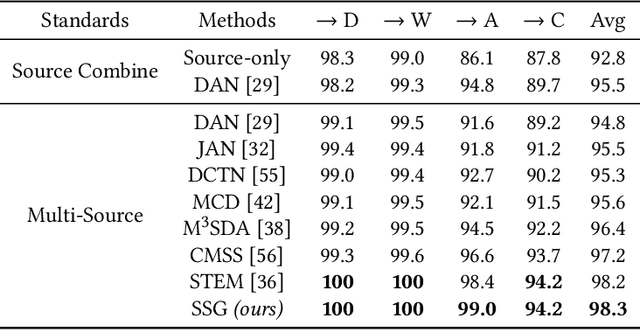
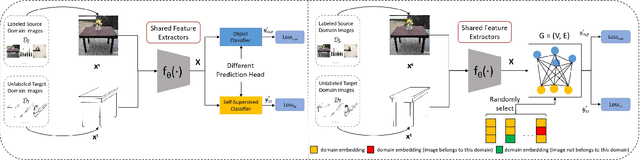
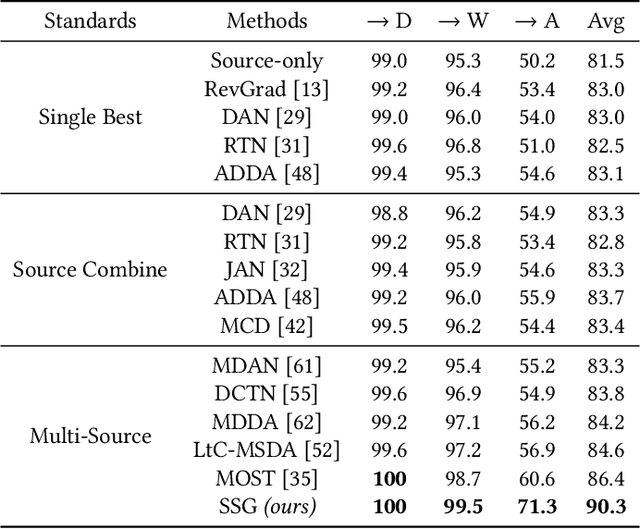
Domain adaptation (DA) tries to tackle the scenarios when the test data does not fully follow the same distribution of the training data, and multi-source domain adaptation (MSDA) is very attractive for real world applications. By learning from large-scale unlabeled samples, self-supervised learning has now become a new trend in deep learning. It is worth noting that both self-supervised learning and multi-source domain adaptation share a similar goal: they both aim to leverage unlabeled data to learn more expressive representations. Unfortunately, traditional multi-task self-supervised learning faces two challenges: (1) the pretext task may not strongly relate to the downstream task, thus it could be difficult to learn useful knowledge being shared from the pretext task to the target task; (2) when the same feature extractor is shared between the pretext task and the downstream one and only different prediction heads are used, it is ineffective to enable inter-task information exchange and knowledge sharing. To address these issues, we propose a novel \textbf{S}elf-\textbf{S}upervised \textbf{G}raph Neural Network (SSG), where a graph neural network is used as the bridge to enable more effective inter-task information exchange and knowledge sharing. More expressive representation is learned by adopting a mask token strategy to mask some domain information. Our extensive experiments have demonstrated that our proposed SSG method has achieved state-of-the-art results over four multi-source domain adaptation datasets, which have shown the effectiveness of our proposed SSG method from different aspects.
An Extension of LIME with Improvement of Interpretability and Fidelity
Apr 26, 2020
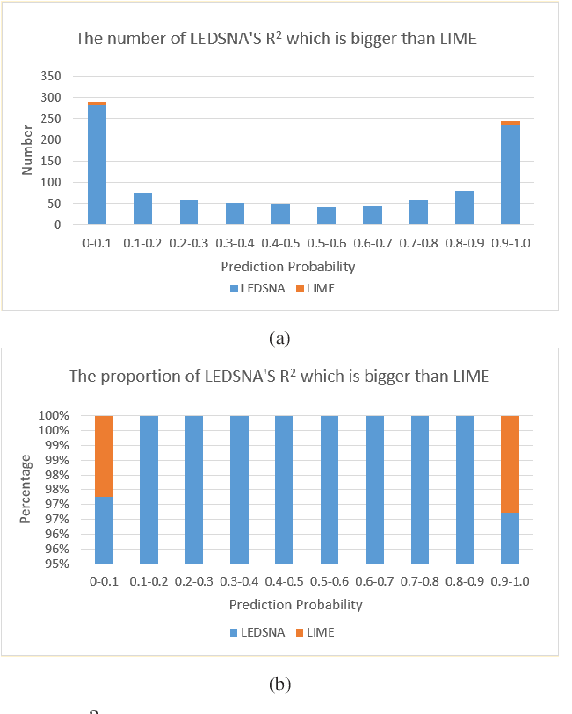
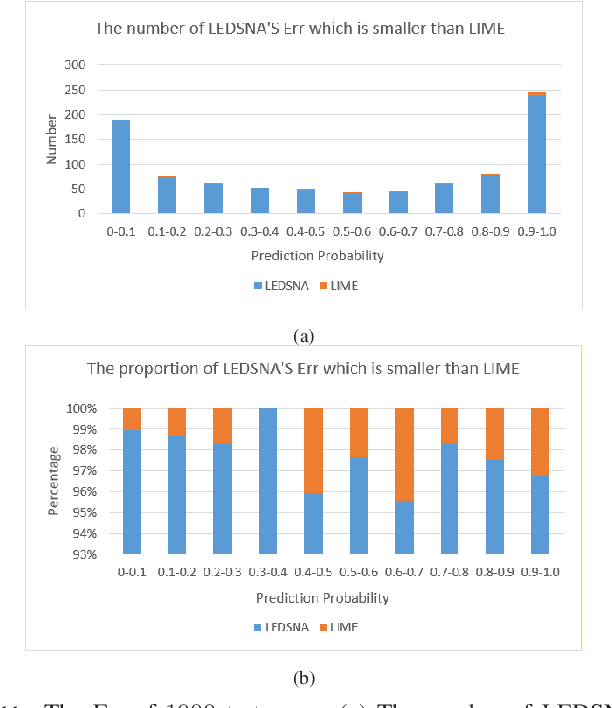
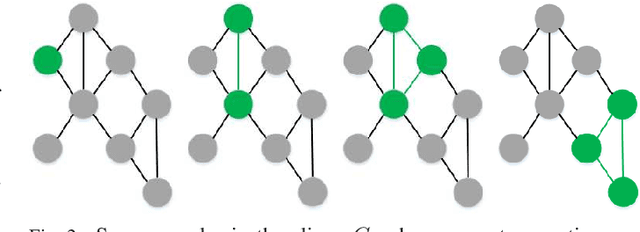
While deep learning makes significant achievements in Artificial Intelligence (AI), the lack of transparency has limited its broad application in various vertical domains. Explainability is not only a gateway between AI and real world, but also a powerful feature to detect flaw of the models and bias of the data. Local Interpretable Model-agnostic Explanation (LIME) is a widely-accepted technique that explains the prediction of any classifier faithfully by learning an interpretable model locally around the predicted instance. As an extension of LIME, this paper proposes an high-interpretability and high-fidelity local explanation method, known as Local Explanation using feature Dependency Sampling and Nonlinear Approximation (LEDSNA). Given an instance being explained, LEDSNA enhances interpretability by feature sampling with intrinsic dependency. Besides, LEDSNA improves the local explanation fidelity by approximating nonlinear boundary of local decision. We evaluate our method with classification tasks in both image domain and text domain. Experiments show that LEDSNA's explanation of the back-box model achieves much better performance than original LIME in terms of interpretability and fidelity.