 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking inside the Convolution for Image Inpainting: Reconstructing Texture via Structure under Global and Local Side
Feb 03, 2026Image inpainting has earned substantial progress, owing to the encoder-and-decoder pipeline, which is benefited from the Convolutional Neural Networks (CNNs) with convolutional downsampling to inpaint the masked regions semantically from the known regions within the encoder, coupled with an upsampling process from the decoder for final inpainting output. Recent studies intuitively identify the high-frequency structure and low-frequency texture to be extracted by CNNs from the encoder, and subsequently for a desirable upsampling recovery. However, the existing arts inevitably overlook the information loss for both structure and texture feature maps during the convolutional downsampling process, hence suffer from a non-ideal upsampling output. In this paper, we systematically answer whether and how the structure and texture feature map can mutually help to alleviate the information loss during the convolutional downsampling. Given the structure and texture feature maps, we adopt the statistical normalization and denormalization strategy for the reconstruction guidance during the convolutional downsampling process. The extensive experimental results validate its advantages to the state-of-the-arts over the images from low-to-high resolutions including 256*256 and 512*512, especially holds by substituting all the encoders by ours. Our code is available at https://github.com/htyjers/ConvInpaint-TSGL
Self-Supervised Weight Templates for Scalable Vision Model Initialization
Jan 27, 2026The increasing scale and complexity of modern model parameters underscore the importance of pre-trained models. However, deployment often demands architectures of varying sizes, exposing limitations of conventional pre-training and fine-tuning. To address this, we propose SWEET, a self-supervised framework that performs constraint-based pre-training to enable scalable initialization in vision tasks. Instead of pre-training a fixed-size model, we learn a shared weight template and size-specific weight scalers under Tucker-based factorization, which promotes modularity and supports flexible adaptation to architectures with varying depths and widths. Target models are subsequently initialized by composing and reweighting the template through lightweight weight scalers, whose parameters can be efficiently learned from minimal training data. To further enhance flexibility in width expansion, we introduce width-wise stochastic scaling, which regularizes the template along width-related dimensions and encourages robust, width-invariant representations for improved cross-width generalization. Extensive experiments on \textsc{classification}, \textsc{detection}, \textsc{segmentation} and \textsc{generation} tasks demonstrate the state-of-the-art performance of SWEET for initializing variable-sized vision models.
REFINE-CONTROL: A Semi-supervised Distillation Method For Conditional Image Generation
Sep 26, 2025Conditional image generation models have achieved remarkable results by leveraging text-based control to generate customized images. However, the high resource demands of these models and the scarcity of well-annotated data have hindered their deployment on edge devices, leading to enormous costs and privacy concerns, especially when user data is sent to a third party. To overcome these challenges, we propose Refine-Control, a semi-supervised distillation framework. Specifically, we improve the performance of the student model by introducing a tri-level knowledge fusion loss to transfer different levels of knowledge. To enhance generalization and alleviate dataset scarcity, we introduce a semi-supervised distillation method utilizing both labeled and unlabeled data. Our experiments reveal that Refine-Control achieves significant reductions in computational cost and latency, while maintaining high-fidelity generation capabilities and controllability, as quantified by comparative metrics.
Enriching Knowledge Distillation with Intra-Class Contrastive Learning
Sep 26, 2025Since the advent of knowledge distillation, much research has focused on how the soft labels generated by the teacher model can be utilized effectively. Existing studies points out that the implicit knowledge within soft labels originates from the multi-view structure present in the data. Feature variations within samples of the same class allow the student model to generalize better by learning diverse representations. However, in existing distillation methods, teacher models predominantly adhere to ground-truth labels as targets, without considering the diverse representations within the same class. Therefore, we propose incorporating an intra-class contrastive loss during teacher training to enrich the intra-class information contained in soft labels. In practice, we find that intra-class loss causes instability in training and slows convergence. To mitigate these issues, margin loss is integrated into intra-class contrastive learning to improve the training stability and convergence speed. Simultaneously, we theoretically analyze the impact of this loss on the intra-class distances and inter-class distances. It has been proved that the intra-class contrastive loss can enrich the intra-class diversity. Experimental results demonstrate the effectiveness of the proposed method.
Towards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025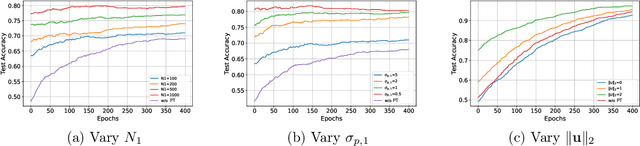
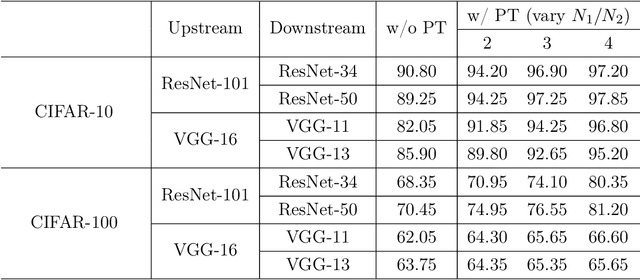
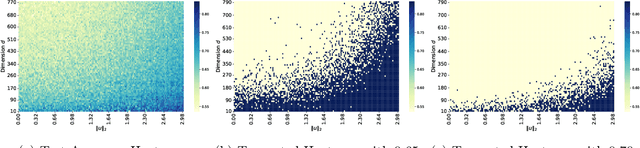
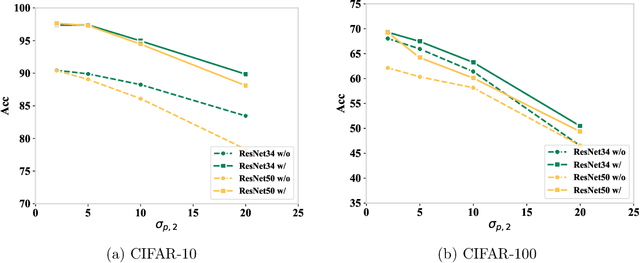
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.
DivControl: Knowledge Diversion for Controllable Image Generation
Jul 31, 2025Diffusion models have advanced from text-to-image (T2I) to image-to-image (I2I) generation by incorporating structured inputs such as depth maps, enabling fine-grained spatial control. However, existing methods either train separate models for each condition or rely on unified architectures with entangled representations, resulting in poor generalization and high adaptation costs for novel conditions. To this end, we propose DivControl, a decomposable pretraining framework for unified controllable generation and efficient adaptation. DivControl factorizes ControlNet via SVD into basic components-pairs of singular vectors-which are disentangled into condition-agnostic learngenes and condition-specific tailors through knowledge diversion during multi-condition training. Knowledge diversion is implemented via a dynamic gate that performs soft routing over tailors based on the semantics of condition instructions, enabling zero-shot generalization and parameter-efficient adaptation to novel conditions. To further improve condition fidelity and training efficiency, we introduce a representation alignment loss that aligns condition embeddings with early diffusion features. Extensive experiments demonstrate that DivControl achieves state-of-the-art controllability with 36.4$\times$ less training cost, while simultaneously improving average performance on basic conditions. It also delivers strong zero-shot and few-shot performance on unseen conditions, demonstrating superior scalability, modularity, and transferability.
LMAgent: A Large-scale Multimodal Agents Society for Multi-user Simulation
Dec 13, 2024
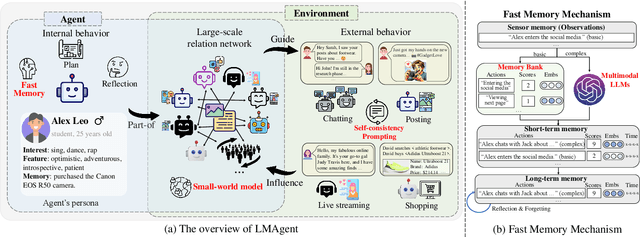
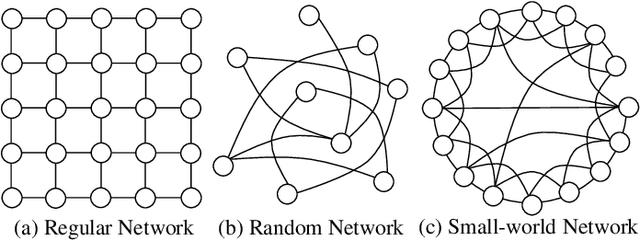
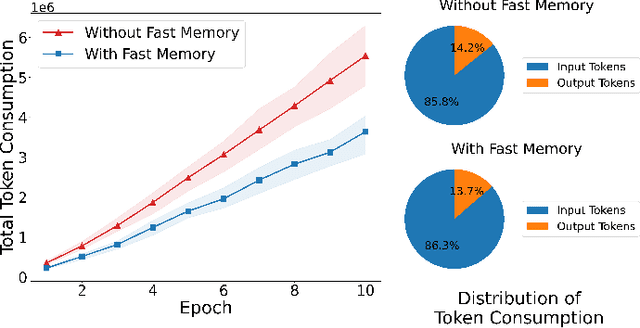
The believable simulation of multi-user behavior is crucial for understanding complex social systems. Recently, large language models (LLMs)-based AI agents have made significant progress, enabling them to achieve human-like intelligence across various tasks. However, real human societies are often dynamic and complex, involving numerous individuals engaging in multimodal interactions. In this paper, taking e-commerce scenarios as an example, we present LMAgent, a very large-scale and multimodal agents society based on multimodal LLMs. In LMAgent, besides freely chatting with friends, the agents can autonomously browse, purchase, and review products, even perform live streaming e-commerce. To simulate this complex system, we introduce a self-consistency prompting mechanism to augment agents' multimodal capabilities, resulting in significantly improved decision-making performance over the existing multi-agent system. Moreover, we propose a fast memory mechanism combined with the small-world model to enhance system efficiency, which supports more than 10,000 agent simulations in a society. Experiments on agents' behavior show that these agents achieve comparable performance to humans in behavioral indicators. Furthermore, compared with the existing LLMs-based multi-agent system, more different and valuable phenomena are exhibited, such as herd behavior, which demonstrates the potential of LMAgent in credible large-scale social behavior simulations.
KIND: Knowledge Integration and Diversion in Diffusion Models
Aug 14, 2024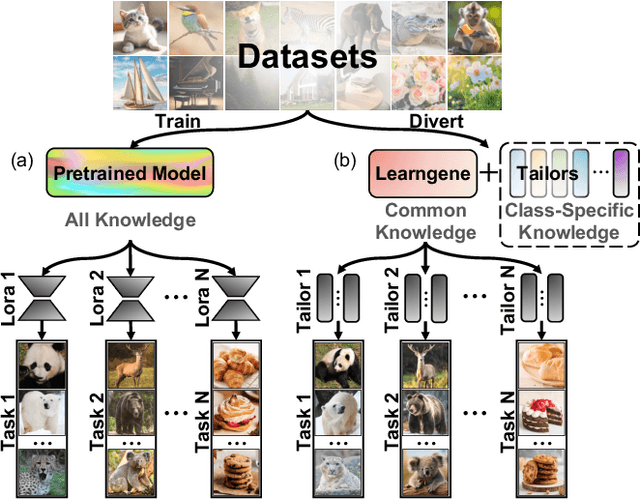
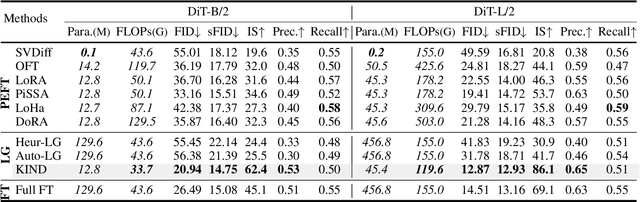
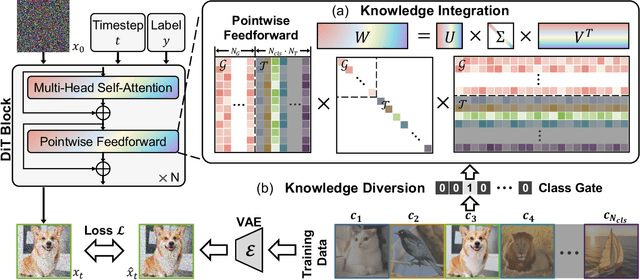
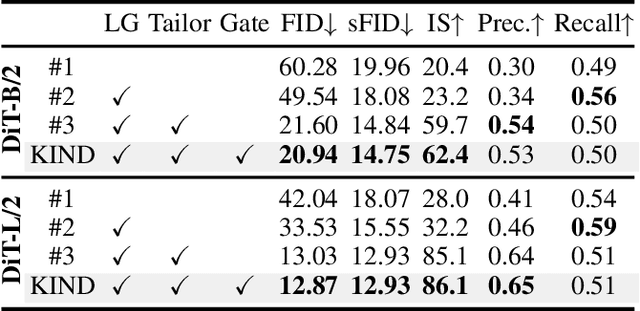
Pre-trained models have become the preferred backbone due to the expansion of model parameters, with techniques like Parameter-Efficient Fine-Tuning (PEFTs) typically fixing the parameters of these models. However, pre-trained models may not always be optimal, especially when there are discrepancies between training tasks and target tasks, potentially resulting in negative transfer. To address this, we introduce \textbf{KIND}, which performs \textbf{K}nowledge \textbf{IN}tegration and \textbf{D}iversion in diffusion models. KIND first integrates knowledge by decomposing parameter matrices of models using $U$, $\Sigma$, and $V$ matrices, formally inspired by singular value decomposition (SVD). Then it explicitly partitions the components of these matrices into \textbf{learngenes} and \textbf{tailors} to condense common and class-specific knowledge, respectively, through a class gate. In this way, KIND redefines traditional pre-training methods by adjusting training objectives from maximizing model performance on current tasks to condensing transferable common knowledge, leveraging the \textit{Learngene} framework. We conduct experiments on ImageNet-1K and compare KIND with PEFT and other learngene methods. Results indicate that KIND achieves state-of-the-art performance compared to other PEFT and learngene methods. Specifically, the images generated by KIND achieves more than 6.54 and 1.07 decrease in FID and sFID on DiT-L/2, utilizing only 45.4M trainable parameters and saving at least 35.4G FLOPs in computational cost.
Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting
Apr 01, 2024Denoising diffusion probabilistic models for image inpainting aim to add the noise to the texture of image during the forward process and recover masked regions with unmasked ones of the texture via the reverse denoising process.Despite the meaningful semantics generation,the existing arts suffer from the semantic discrepancy between masked and unmasked regions, since the semantically dense unmasked texture fails to be completely degraded while the masked regions turn to the pure noise in diffusion process,leading to the large discrepancy between them. In this paper,we aim to answer how unmasked semantics guide texture denoising process;together with how to tackle the semantic discrepancy,to facilitate the consistent and meaningful semantics generation. To this end,we propose a novel structure-guided diffusion model named StrDiffusion,to reformulate the conventional texture denoising process under structure guidance to derive a simplified denoising objective for image inpainting,while revealing:1)the semantically sparse structure is beneficial to tackle semantic discrepancy in early stage, while dense texture generates reasonable semantics in late stage;2)the semantics from unmasked regions essentially offer the time-dependent structure guidance for the texture denoising process,benefiting from the time-dependent sparsity of the structure semantics.For the denoising process,a structure-guided neural network is trained to estimate the simplified denoising objective by exploiting the consistency of the denoised structure between masked and unmasked regions.Besides,we devise an adaptive resampling strategy as a formal criterion as whether structure is competent to guide the texture denoising process,while regulate their semantic correlations.Extensive experiments validate the merits of StrDiffusion over the state-of-the-arts.Our code is available at https://github.com/htyjers/StrDiffusion.
DomainVerse: A Benchmark Towards Real-World Distribution Shifts For Tuning-Free Adaptive Domain Generalization
Mar 05, 2024Traditional cross-domain tasks, including domain adaptation and domain generalization, rely heavily on training model by source domain data. With the recent advance of vision-language models (VLMs), viewed as natural source models, the cross-domain task changes to directly adapt the pre-trained source model to arbitrary target domains equipped with prior domain knowledge, and we name this task Adaptive Domain Generalization (ADG). However, current cross-domain datasets have many limitations, such as unrealistic domains, unclear domain definitions, and the inability to fine-grained domain decomposition, which drives us to establish a novel dataset DomainVerse for ADG. Benefiting from the introduced hierarchical definition of domain shifts, DomainVerse consists of about 0.5 million images from 390 fine-grained realistic domains. With the help of the constructed DomainVerse and VLMs, we propose two methods called Domain CLIP and Domain++ CLIP for tuning-free adaptive domain generalization. Extensive and comprehensive experiments demonstrate the significance of the dataset and the effectiveness of the proposed methods.