 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint-based Pre-training: From Structured Constraints to Scalable Model Initialization
Apr 16, 2026The pre-training and fine-tuning paradigm has become the dominant approach for model adaptation. However, conventional pre-training typically yields models at a fixed scale, whereas practical deployment often requires models of varying sizes, exposing its limitations when target model scales differ from those used during pre-training. To address this, we propose an innovative constraint-based pre-training paradigm that imposes structured constraints during pre-training to disentangle size-agnostic knowledge into reusable weight templates, while assigning size-specific adaptation to lightweight weight scalers, thereby reformulating variable-sized model initialization as a multi-task adaptation problem. Within this paradigm, we further introduce WeiT, which employs Kronecker-based constraints to regularize the pre-training process. Specifically, model parameters are represented as compositions of weight templates via concatenation and weighted aggregation, with adaptive connections governed by lightweight weight scalers whose parameters are learned from limited data. This design enables flexible and efficient construction of model weights across diverse downstream scales. Extensive experiments demonstrate the efficiency and effectiveness of WeiT, achieving state-of-the-art performance in initializing models with varying depths and widths across a broad range of perception and embodied learning tasks, including Image Classification, Image Generation, and Embodied Control. Moreover, its effectiveness generalizes to both Transformer-based and Convolution-based architectures, consistently enabling faster convergence and improved performance even under full training.
A Creative Agent is Worth a 64-Token Template
Mar 18, 2026Text-to-image (T2I) models have substantially improved image fidelity and prompt adherence, yet their creativity remains constrained by reliance on discrete natural language prompts. When presented with fuzzy prompts such as ``a creative vinyl record-inspired skyscraper'', these models often fail to infer the underlying creative intent, leaving creative ideation and prompt design largely to human users. Recent reasoning- or agent-driven approaches iteratively augment prompts but incur high computational and monetary costs, as their instance-specific generation makes ``creativity'' costly and non-reusable, requiring repeated queries or reasoning for subsequent generations. To address this, we introduce \textbf{CAT}, a framework for \textbf{C}reative \textbf{A}gent \textbf{T}okenization that encapsulates agents' intrinsic understanding of ``creativity'' through a \textit{Creative Tokenizer}. Given the embeddings of fuzzy prompts, the tokenizer generates a reusable token template that can be directly concatenated with them to inject creative semantics into T2I models without repeated reasoning or prompt augmentation. To enable this, the tokenizer is trained via creative semantic disentanglement, leveraging relations among partially overlapping concept pairs to capture the agent's latent creative representations. Extensive experiments on \textbf{\textit{Architecture Design}}, \textbf{\textit{Furniture Design}}, and \textbf{\textit{Nature Mixture}} tasks demonstrate that CAT provides a scalable and effective paradigm for enhancing creativity in T2I generation, achieving a $3.7\times$ speedup and a $4.8\times$ reduction in computational cost, while producing images with superior human preference and text-image alignment compared to state-of-the-art T2I models and creative generation methods.
Self-Supervised Weight Templates for Scalable Vision Model Initialization
Jan 27, 2026The increasing scale and complexity of modern model parameters underscore the importance of pre-trained models. However, deployment often demands architectures of varying sizes, exposing limitations of conventional pre-training and fine-tuning. To address this, we propose SWEET, a self-supervised framework that performs constraint-based pre-training to enable scalable initialization in vision tasks. Instead of pre-training a fixed-size model, we learn a shared weight template and size-specific weight scalers under Tucker-based factorization, which promotes modularity and supports flexible adaptation to architectures with varying depths and widths. Target models are subsequently initialized by composing and reweighting the template through lightweight weight scalers, whose parameters can be efficiently learned from minimal training data. To further enhance flexibility in width expansion, we introduce width-wise stochastic scaling, which regularizes the template along width-related dimensions and encourages robust, width-invariant representations for improved cross-width generalization. Extensive experiments on \textsc{classification}, \textsc{detection}, \textsc{segmentation} and \textsc{generation} tasks demonstrate the state-of-the-art performance of SWEET for initializing variable-sized vision models.
Knowledge Diversion for Efficient Morphology Control and Policy Transfer
Dec 10, 2025Universal morphology control aims to learn a universal policy that generalizes across heterogeneous agent morphologies, with Transformer-based controllers emerging as a popular choice. However, such architectures incur substantial computational costs, resulting in high deployment overhead, and existing methods exhibit limited cross-task generalization, necessitating training from scratch for each new task. To this end, we propose \textbf{DivMorph}, a modular training paradigm that leverages knowledge diversion to learn decomposable controllers. DivMorph factorizes randomly initialized Transformer weights into factor units via SVD prior to training and employs dynamic soft gating to modulate these units based on task and morphology embeddings, separating them into shared \textit{learngenes} and morphology- and task-specific \textit{tailors}, thereby achieving knowledge disentanglement. By selectively activating relevant components, DivMorph enables scalable and efficient policy deployment while supporting effective policy transfer to novel tasks. Extensive experiments demonstrate that DivMorph achieves state-of-the-art performance, achieving a 3$\times$ improvement in sample efficiency over direct finetuning for cross-task transfer and a 17$\times$ reduction in model size for single-agent deployment.
DivControl: Knowledge Diversion for Controllable Image Generation
Jul 31, 2025Diffusion models have advanced from text-to-image (T2I) to image-to-image (I2I) generation by incorporating structured inputs such as depth maps, enabling fine-grained spatial control. However, existing methods either train separate models for each condition or rely on unified architectures with entangled representations, resulting in poor generalization and high adaptation costs for novel conditions. To this end, we propose DivControl, a decomposable pretraining framework for unified controllable generation and efficient adaptation. DivControl factorizes ControlNet via SVD into basic components-pairs of singular vectors-which are disentangled into condition-agnostic learngenes and condition-specific tailors through knowledge diversion during multi-condition training. Knowledge diversion is implemented via a dynamic gate that performs soft routing over tailors based on the semantics of condition instructions, enabling zero-shot generalization and parameter-efficient adaptation to novel conditions. To further improve condition fidelity and training efficiency, we introduce a representation alignment loss that aligns condition embeddings with early diffusion features. Extensive experiments demonstrate that DivControl achieves state-of-the-art controllability with 36.4$\times$ less training cost, while simultaneously improving average performance on basic conditions. It also delivers strong zero-shot and few-shot performance on unseen conditions, demonstrating superior scalability, modularity, and transferability.
FAD: Frequency Adaptation and Diversion for Cross-domain Few-shot Learning
May 13, 2025Cross-domain few-shot learning (CD-FSL) requires models to generalize from limited labeled samples under significant distribution shifts. While recent methods enhance adaptability through lightweight task-specific modules, they operate solely in the spatial domain and overlook frequency-specific variations that are often critical for robust transfer. We observe that spatially similar images across domains can differ substantially in their spectral representations, with low and high frequencies capturing complementary semantic information at coarse and fine levels. This indicates that uniform spatial adaptation may overlook these spectral distinctions, thus constraining generalization. To address this, we introduce Frequency Adaptation and Diversion (FAD), a frequency-aware framework that explicitly models and modulates spectral components. At its core is the Frequency Diversion Adapter, which transforms intermediate features into the frequency domain using the discrete Fourier transform (DFT), partitions them into low, mid, and high-frequency bands via radial masks, and reconstructs each band using inverse DFT (IDFT). Each frequency band is then adapted using a dedicated convolutional branch with a kernel size tailored to its spectral scale, enabling targeted and disentangled adaptation across frequencies. Extensive experiments on the Meta-Dataset benchmark demonstrate that FAD consistently outperforms state-of-the-art methods on both seen and unseen domains, validating the utility of frequency-domain representations and band-wise adaptation for improving generalization in CD-FSL.
FINE: Factorizing Knowledge for Initialization of Variable-sized Diffusion Models
Sep 28, 2024


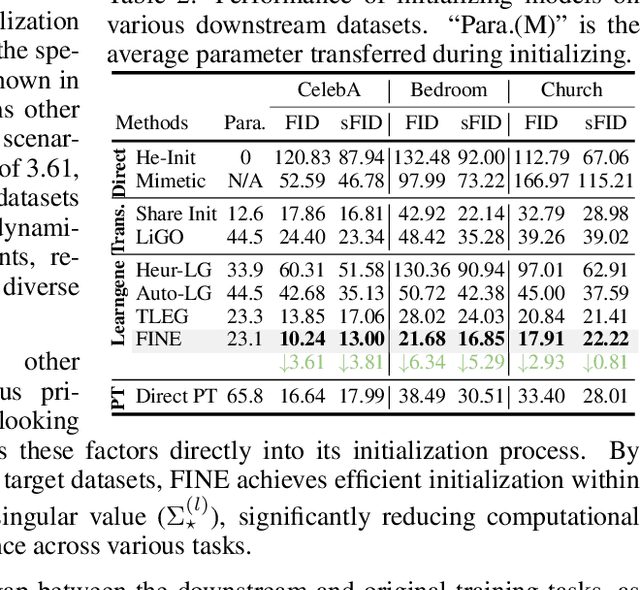
Diffusion models often face slow convergence, and existing efficient training techniques, such as Parameter-Efficient Fine-Tuning (PEFT), are primarily designed for fine-tuning pre-trained models. However, these methods are limited in adapting models to variable sizes for real-world deployment, where no corresponding pre-trained models exist. To address this, we introduce FINE, a method based on the Learngene framework, to initializing downstream networks leveraging pre-trained models, while considering both model sizes and task-specific requirements. FINE decomposes pre-trained knowledge into the product of matrices (i.e., $U$, $\Sigma$, and $V$), where $U$ and $V$ are shared across network blocks as ``learngenes'', and $\Sigma$ remains layer-specific. During initialization, FINE trains only $\Sigma$ using a small subset of data, while keeping the learngene parameters fixed, marking it the first approach to integrate both size and task considerations in initialization. We provide a comprehensive benchmark for learngene-based methods in image generation tasks, and extensive experiments demonstrate that FINE consistently outperforms direct pre-training, particularly for smaller models, achieving state-of-the-art results across variable model sizes. FINE also offers significant computational and storage savings, reducing training steps by approximately $3N\times$ and storage by $5\times$, where $N$ is the number of models. Additionally, FINE's adaptability to tasks yields an average performance improvement of 4.29 and 3.30 in FID and sFID across multiple downstream datasets, highlighting its versatility and efficiency.
Multimodal-Enhanced Objectness Learner for Corner Case Detection in Autonomous Driving
Feb 03, 2024



Previous works on object detection have achieved high accuracy in closed-set scenarios, but their performance in open-world scenarios is not satisfactory. One of the challenging open-world problems is corner case detection in autonomous driving. Existing detectors struggle with these cases, relying heavily on visual appearance and exhibiting poor generalization ability. In this paper, we propose a solution by reducing the discrepancy between known and unknown classes and introduce a multimodal-enhanced objectness notion learner. Leveraging both vision-centric and image-text modalities, our semi-supervised learning framework imparts objectness knowledge to the student model, enabling class-aware detection. Our approach, Multimodal-Enhanced Objectness Learner (MENOL) for Corner Case Detection, significantly improves recall for novel classes with lower training costs. By achieving a 76.6% mAR-corner and 79.8% mAR-agnostic on the CODA-val dataset with just 5100 labeled training images, MENOL outperforms the baseline ORE by 71.3% and 60.6%, respectively. The code will be available at https://github.com/tryhiseyyysum/MENOL.