 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Weight Templates for Scalable Vision Model Initialization
Jan 27, 2026The increasing scale and complexity of modern model parameters underscore the importance of pre-trained models. However, deployment often demands architectures of varying sizes, exposing limitations of conventional pre-training and fine-tuning. To address this, we propose SWEET, a self-supervised framework that performs constraint-based pre-training to enable scalable initialization in vision tasks. Instead of pre-training a fixed-size model, we learn a shared weight template and size-specific weight scalers under Tucker-based factorization, which promotes modularity and supports flexible adaptation to architectures with varying depths and widths. Target models are subsequently initialized by composing and reweighting the template through lightweight weight scalers, whose parameters can be efficiently learned from minimal training data. To further enhance flexibility in width expansion, we introduce width-wise stochastic scaling, which regularizes the template along width-related dimensions and encourages robust, width-invariant representations for improved cross-width generalization. Extensive experiments on \textsc{classification}, \textsc{detection}, \textsc{segmentation} and \textsc{generation} tasks demonstrate the state-of-the-art performance of SWEET for initializing variable-sized vision models.
Knowledge Diversion for Efficient Morphology Control and Policy Transfer
Dec 10, 2025Universal morphology control aims to learn a universal policy that generalizes across heterogeneous agent morphologies, with Transformer-based controllers emerging as a popular choice. However, such architectures incur substantial computational costs, resulting in high deployment overhead, and existing methods exhibit limited cross-task generalization, necessitating training from scratch for each new task. To this end, we propose \textbf{DivMorph}, a modular training paradigm that leverages knowledge diversion to learn decomposable controllers. DivMorph factorizes randomly initialized Transformer weights into factor units via SVD prior to training and employs dynamic soft gating to modulate these units based on task and morphology embeddings, separating them into shared \textit{learngenes} and morphology- and task-specific \textit{tailors}, thereby achieving knowledge disentanglement. By selectively activating relevant components, DivMorph enables scalable and efficient policy deployment while supporting effective policy transfer to novel tasks. Extensive experiments demonstrate that DivMorph achieves state-of-the-art performance, achieving a 3$\times$ improvement in sample efficiency over direct finetuning for cross-task transfer and a 17$\times$ reduction in model size for single-agent deployment.
Look, Zoom, Understand: The Robotic Eyeball for Embodied Perception
Nov 19, 2025In embodied AI perception systems, visual perception should be active: the goal is not to passively process static images, but to actively acquire more informative data within pixel and spatial budget constraints. Existing vision models and fixed RGB-D camera systems fundamentally fail to reconcile wide-area coverage with fine-grained detail acquisition, severely limiting their efficacy in open-world robotic applications. To address this issue, we propose EyeVLA, a robotic eyeball for active visual perception that can take proactive actions based on instructions, enabling clear observation of fine-grained target objects and detailed information across a wide spatial extent. EyeVLA discretizes action behaviors into action tokens and integrates them with vision-language models (VLMs) that possess strong open-world understanding capabilities, enabling joint modeling of vision, language, and actions within a single autoregressive sequence. By using the 2D bounding box coordinates to guide the reasoning chain and applying reinforcement learning to refine the viewpoint selection policy, we transfer the open-world scene understanding capability of the VLM to a vision language action (VLA) policy using only minimal real-world data. Experiments show that our system efficiently performs instructed scenes in real-world environments and actively acquires more accurate visual information through instruction-driven actions of rotation and zoom, thereby achieving strong environmental perception capabilities. EyeVLA introduces a novel robotic vision system that leverages detailed and spatially rich, large-scale embodied data, and actively acquires highly informative visual observations for downstream embodied tasks.
DivControl: Knowledge Diversion for Controllable Image Generation
Jul 31, 2025Diffusion models have advanced from text-to-image (T2I) to image-to-image (I2I) generation by incorporating structured inputs such as depth maps, enabling fine-grained spatial control. However, existing methods either train separate models for each condition or rely on unified architectures with entangled representations, resulting in poor generalization and high adaptation costs for novel conditions. To this end, we propose DivControl, a decomposable pretraining framework for unified controllable generation and efficient adaptation. DivControl factorizes ControlNet via SVD into basic components-pairs of singular vectors-which are disentangled into condition-agnostic learngenes and condition-specific tailors through knowledge diversion during multi-condition training. Knowledge diversion is implemented via a dynamic gate that performs soft routing over tailors based on the semantics of condition instructions, enabling zero-shot generalization and parameter-efficient adaptation to novel conditions. To further improve condition fidelity and training efficiency, we introduce a representation alignment loss that aligns condition embeddings with early diffusion features. Extensive experiments demonstrate that DivControl achieves state-of-the-art controllability with 36.4$\times$ less training cost, while simultaneously improving average performance on basic conditions. It also delivers strong zero-shot and few-shot performance on unseen conditions, demonstrating superior scalability, modularity, and transferability.
FAD: Frequency Adaptation and Diversion for Cross-domain Few-shot Learning
May 13, 2025Cross-domain few-shot learning (CD-FSL) requires models to generalize from limited labeled samples under significant distribution shifts. While recent methods enhance adaptability through lightweight task-specific modules, they operate solely in the spatial domain and overlook frequency-specific variations that are often critical for robust transfer. We observe that spatially similar images across domains can differ substantially in their spectral representations, with low and high frequencies capturing complementary semantic information at coarse and fine levels. This indicates that uniform spatial adaptation may overlook these spectral distinctions, thus constraining generalization. To address this, we introduce Frequency Adaptation and Diversion (FAD), a frequency-aware framework that explicitly models and modulates spectral components. At its core is the Frequency Diversion Adapter, which transforms intermediate features into the frequency domain using the discrete Fourier transform (DFT), partitions them into low, mid, and high-frequency bands via radial masks, and reconstructs each band using inverse DFT (IDFT). Each frequency band is then adapted using a dedicated convolutional branch with a kernel size tailored to its spectral scale, enabling targeted and disentangled adaptation across frequencies. Extensive experiments on the Meta-Dataset benchmark demonstrate that FAD consistently outperforms state-of-the-art methods on both seen and unseen domains, validating the utility of frequency-domain representations and band-wise adaptation for improving generalization in CD-FSL.
Distribution-Conditional Generation: From Class Distribution to Creative Generation
May 06, 2025Text-to-image (T2I) diffusion models are effective at producing semantically aligned images, but their reliance on training data distributions limits their ability to synthesize truly novel, out-of-distribution concepts. Existing methods typically enhance creativity by combining pairs of known concepts, yielding compositions that, while out-of-distribution, remain linguistically describable and bounded within the existing semantic space. Inspired by the soft probabilistic outputs of classifiers on ambiguous inputs, we propose Distribution-Conditional Generation, a novel formulation that models creativity as image synthesis conditioned on class distributions, enabling semantically unconstrained creative generation. Building on this, we propose DisTok, an encoder-decoder framework that maps class distributions into a latent space and decodes them into tokens of creative concept. DisTok maintains a dynamic concept pool and iteratively sampling and fusing concept pairs, enabling the generation of tokens aligned with increasingly complex class distributions. To enforce distributional consistency, latent vectors sampled from a Gaussian prior are decoded into tokens and rendered into images, whose class distributions-predicted by a vision-language model-supervise the alignment between input distributions and the visual semantics of generated tokens. The resulting tokens are added to the concept pool for subsequent composition. Extensive experiments demonstrate that DisTok, by unifying distribution-conditioned fusion and sampling-based synthesis, enables efficient and flexible token-level generation, achieving state-of-the-art performance with superior text-image alignment and human preference scores.
Redefining <Creative> in Dictionary: Towards a Enhanced Semantic Understanding of Creative Generation
Oct 31, 2024

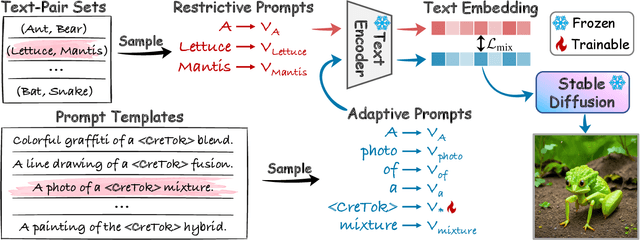

Creativity, both in human and diffusion models, remains an inherently abstract concept; thus, simply adding "creative" to a prompt does not yield reliable semantic recognition by the model. In this work, we concretize the abstract notion of "creative" through the TP2O task, which aims to merge two unrelated concepts, and introduce CreTok, redefining "creative" as the token $\texttt{<CreTok>}$. This redefinition offers a more concrete and universally adaptable representation for concept blending. This redefinition occurs continuously, involving the repeated random sampling of text pairs with different concepts and optimizing cosine similarity between target and constant prompts. This approach enables $\texttt{<CreTok>}$ to learn a method for creative concept fusion. Extensive experiments demonstrate that the creative capability enabled by $\texttt{<CreTok>}$ substantially surpasses recent SOTA diffusion models and achieves superior creative generation. CreTok exhibits greater flexibility and reduced time overhead, as $\texttt{<CreTok>}$ can function as a universal token for any concept, facilitating creative generation without retraining.
FINE: Factorizing Knowledge for Initialization of Variable-sized Diffusion Models
Sep 28, 2024


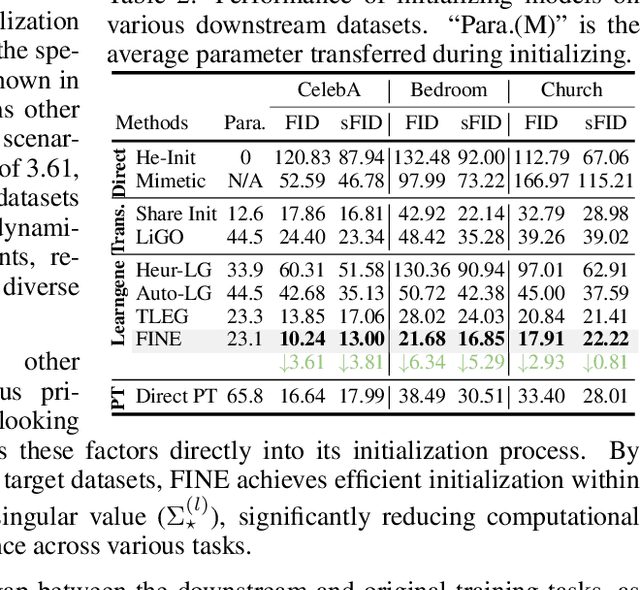
Diffusion models often face slow convergence, and existing efficient training techniques, such as Parameter-Efficient Fine-Tuning (PEFT), are primarily designed for fine-tuning pre-trained models. However, these methods are limited in adapting models to variable sizes for real-world deployment, where no corresponding pre-trained models exist. To address this, we introduce FINE, a method based on the Learngene framework, to initializing downstream networks leveraging pre-trained models, while considering both model sizes and task-specific requirements. FINE decomposes pre-trained knowledge into the product of matrices (i.e., $U$, $\Sigma$, and $V$), where $U$ and $V$ are shared across network blocks as ``learngenes'', and $\Sigma$ remains layer-specific. During initialization, FINE trains only $\Sigma$ using a small subset of data, while keeping the learngene parameters fixed, marking it the first approach to integrate both size and task considerations in initialization. We provide a comprehensive benchmark for learngene-based methods in image generation tasks, and extensive experiments demonstrate that FINE consistently outperforms direct pre-training, particularly for smaller models, achieving state-of-the-art results across variable model sizes. FINE also offers significant computational and storage savings, reducing training steps by approximately $3N\times$ and storage by $5\times$, where $N$ is the number of models. Additionally, FINE's adaptability to tasks yields an average performance improvement of 4.29 and 3.30 in FID and sFID across multiple downstream datasets, highlighting its versatility and efficiency.
KIND: Knowledge Integration and Diversion in Diffusion Models
Aug 14, 2024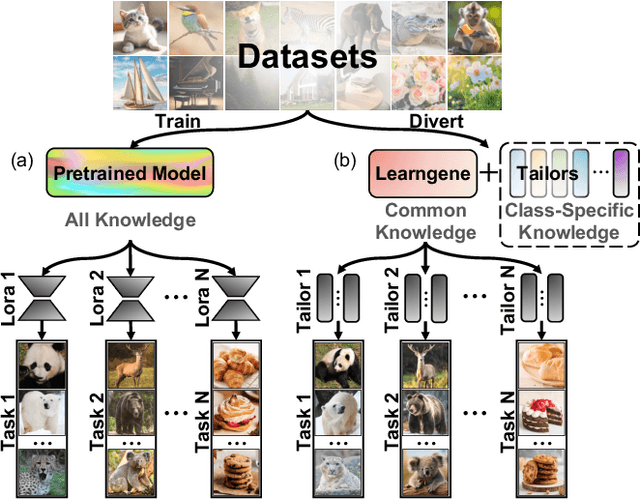
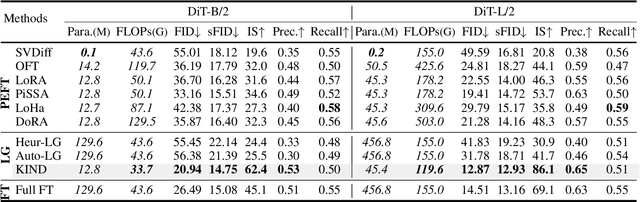
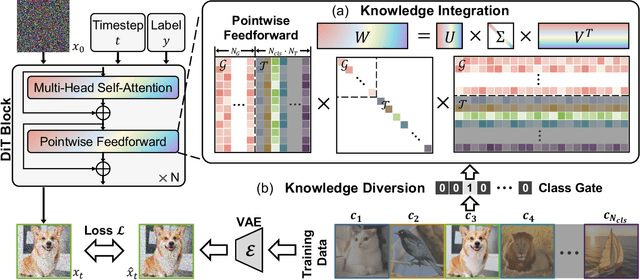
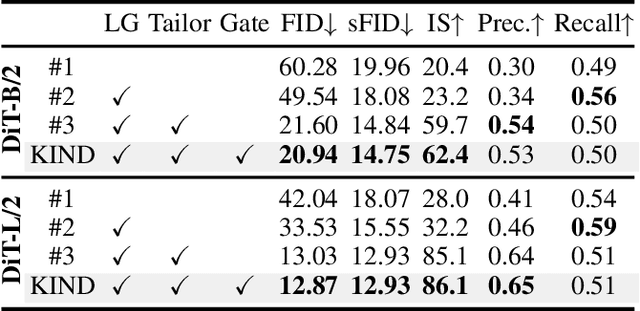
Pre-trained models have become the preferred backbone due to the expansion of model parameters, with techniques like Parameter-Efficient Fine-Tuning (PEFTs) typically fixing the parameters of these models. However, pre-trained models may not always be optimal, especially when there are discrepancies between training tasks and target tasks, potentially resulting in negative transfer. To address this, we introduce \textbf{KIND}, which performs \textbf{K}nowledge \textbf{IN}tegration and \textbf{D}iversion in diffusion models. KIND first integrates knowledge by decomposing parameter matrices of models using $U$, $\Sigma$, and $V$ matrices, formally inspired by singular value decomposition (SVD). Then it explicitly partitions the components of these matrices into \textbf{learngenes} and \textbf{tailors} to condense common and class-specific knowledge, respectively, through a class gate. In this way, KIND redefines traditional pre-training methods by adjusting training objectives from maximizing model performance on current tasks to condensing transferable common knowledge, leveraging the \textit{Learngene} framework. We conduct experiments on ImageNet-1K and compare KIND with PEFT and other learngene methods. Results indicate that KIND achieves state-of-the-art performance compared to other PEFT and learngene methods. Specifically, the images generated by KIND achieves more than 6.54 and 1.07 decrease in FID and sFID on DiT-L/2, utilizing only 45.4M trainable parameters and saving at least 35.4G FLOPs in computational cost.
WAVE: Weight Template for Adaptive Initialization of Variable-sized Models
Jun 25, 2024



The expansion of model parameters underscores the significance of pre-trained models; however, the constraints encountered during model deployment necessitate models of variable sizes. Consequently, the traditional pre-training and fine-tuning paradigm fails to address the initialization problem when target models are incompatible with pre-trained models. We tackle this issue from a multitasking perspective and introduce \textbf{WAVE}, which incorporates a set of shared \textbf{W}eight templates for \textbf{A}daptive initialization of \textbf{V}ariable-siz\textbf{E}d Models. During initialization, target models will initialize the corresponding weight scalers tailored to their model size, which are sufficient to learn the connection rules of weight templates based on the Kronecker product from a limited amount of data. For the construction of the weight templates, WAVE utilizes the \textit{Learngene} framework, which structurally condenses common knowledge from ancestry models into weight templates as the learngenes through knowledge distillation. This process allows the integration of pre-trained models' knowledge into structured knowledge according to the rules of weight templates. We provide a comprehensive benchmark for the learngenes, and extensive experiments demonstrate the efficacy of WAVE. The results show that WAVE achieves state-of-the-art performance when initializing models with various depth and width, and even outperforms the direct pre-training of $n$ entire models, particularly for smaller models, saving approximately $n\times$ and $5\times$ in computational and storage resources, respectively. WAVE simultaneously achieves the most efficient knowledge transfer across a series of datasets, specifically achieving an average improvement of 1.8\% and 1.2\% on 7 downstream datasets.