 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIND: Knowledge Integration and Diversion in Diffusion Models
Paper and Code
Aug 14, 2024
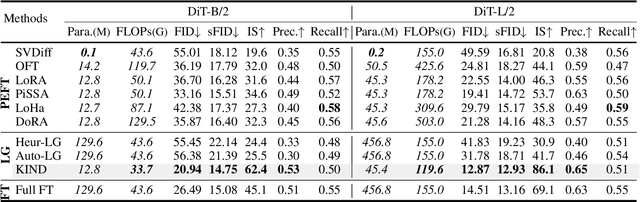
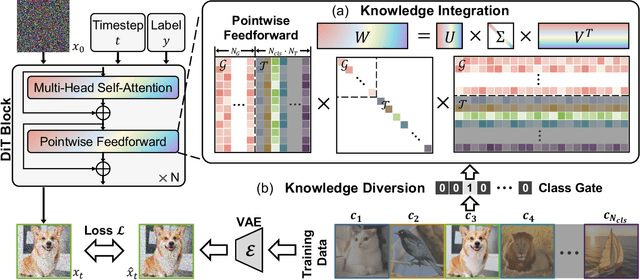
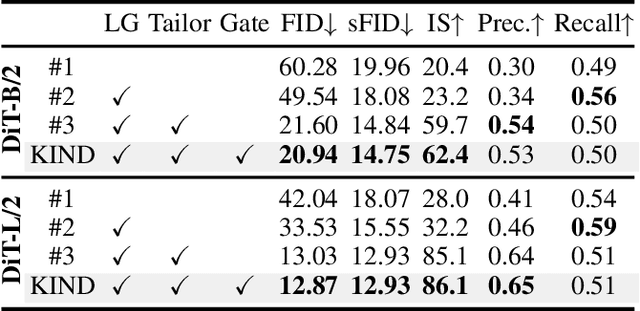
Pre-trained models have become the preferred backbone due to the expansion of model parameters, with techniques like Parameter-Efficient Fine-Tuning (PEFTs) typically fixing the parameters of these models. However, pre-trained models may not always be optimal, especially when there are discrepancies between training tasks and target tasks, potentially resulting in negative transfer. To address this, we introduce \textbf{KIND}, which performs \textbf{K}nowledge \textbf{IN}tegration and \textbf{D}iversion in diffusion models. KIND first integrates knowledge by decomposing parameter matrices of models using $U$, $\Sigma$, and $V$ matrices, formally inspired by singular value decomposition (SVD). Then it explicitly partitions the components of these matrices into \textbf{learngenes} and \textbf{tailors} to condense common and class-specific knowledge, respectively, through a class gate. In this way, KIND redefines traditional pre-training methods by adjusting training objectives from maximizing model performance on current tasks to condensing transferable common knowledge, leveraging the \textit{Learngene} framework. We conduct experiments on ImageNet-1K and compare KIND with PEFT and other learngene methods. Results indicate that KIND achieves state-of-the-art performance compared to other PEFT and learngene methods. Specifically, the images generated by KIND achieves more than 6.54 and 1.07 decrease in FID and sFID on DiT-L/2, utilizing only 45.4M trainable parameters and saving at least 35.4G FLOPs in computational cost.