 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINE: Factorizing Knowledge for Initialization of Variable-sized Diffusion Models
Paper and Code
Sep 28, 2024


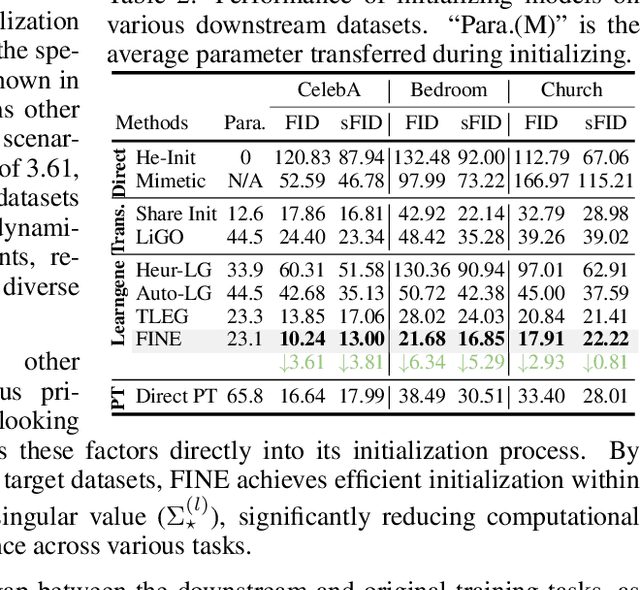
Diffusion models often face slow convergence, and existing efficient training techniques, such as Parameter-Efficient Fine-Tuning (PEFT), are primarily designed for fine-tuning pre-trained models. However, these methods are limited in adapting models to variable sizes for real-world deployment, where no corresponding pre-trained models exist. To address this, we introduce FINE, a method based on the Learngene framework, to initializing downstream networks leveraging pre-trained models, while considering both model sizes and task-specific requirements. FINE decomposes pre-trained knowledge into the product of matrices (i.e., $U$, $\Sigma$, and $V$), where $U$ and $V$ are shared across network blocks as ``learngenes'', and $\Sigma$ remains layer-specific. During initialization, FINE trains only $\Sigma$ using a small subset of data, while keeping the learngene parameters fixed, marking it the first approach to integrate both size and task considerations in initialization. We provide a comprehensive benchmark for learngene-based methods in image generation tasks, and extensive experiments demonstrate that FINE consistently outperforms direct pre-training, particularly for smaller models, achieving state-of-the-art results across variable model sizes. FINE also offers significant computational and storage savings, reducing training steps by approximately $3N\times$ and storage by $5\times$, where $N$ is the number of models. Additionally, FINE's adaptability to tasks yields an average performance improvement of 4.29 and 3.30 in FID and sFID across multiple downstream datasets, highlighting its versatility and efficiency.