 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation-Invariant Spherical Watermarking via Third-Order SO(3) Representation Coupling
May 26, 2026Reliable watermarking of panoramic imagery is fundamentally challenged by arbitrary 3D rotations. As panoramas are defined on the sphere, they naturally transform under the action of $SO(3)$, rendering conventional planar representations and augmentation-based robustness strategies inadequate and devoid of theoretical guarantees. To address this, we formulate panoramas as spherical signals and leverage $SO(3)$ representation theory to derive provably rotation-invariant descriptors. While spherical harmonic coefficients transform equivariantly under rotations, the natural invariant constructions are typically limited to zeroth-order statistics which eliminate directional information and severely constrain embedding capacity. In this work, we introduce a principled third-order invariant construction by coupling higher-order $SO(3)$ irreducible representations via tensor products and projecting onto the trivial representation. This yields a spherical invariant bispectrum that preserves phase information while remaining strictly rotation-invariant. Leveraging this property, we embed watermarks into higher-order spherical harmonic coefficients and recover them from invariant bispectral scalars, enabling reliable extraction under arbitrary 3D rotations. We provide a theoretical proof of $SO(3)$ invariance for it and demonstrate experimentally its near-perfect robustness to continuous rotations while maintaining high visual fidelity.
Rel-Zero: Harnessing Patch-Pair Invariance for Robust Zero-Watermarking Against AI Editing
Mar 18, 2026Recent advancements in diffusion-based image editing pose a significant threat to the authenticity of digital visual content. Traditional embedding-based watermarking methods often introduce perceptible perturbations to maintain robustness, inevitably compromising visual fidelity. Meanwhile, existing zero-watermarking approaches, typically relying on global image features, struggle to withstand sophisticated manipulations. In this work, we uncover a key observation: while individual image patches undergo substantial alterations during AI-based editing, the relational distance between patch pairs remains relatively invariant. Leveraging this property, we propose Relational Zero-Watermarking (Rel-Zero), a novel framework that requires no modification to the original image but derives a unique zero-watermark from these editing-invariant patch relations. By grounding the watermark in intrinsic structural consistency rather than absolute appearance, Rel-Zero provides a non-invasive yet resilient mechanism for content authentication. Extensive experiments demonstrate that Rel-Zero achieves substantially improved robustness across diverse editing models and manipulations compared to prior zero-watermarking approaches.
Backdoor Sentinel: Detecting and Detoxifying Backdoors in Diffusion Models via Temporal Noise Consistency
Feb 02, 2026Diffusion models have been widely deployed in AIGC services; however, their reliance on opaque training data and procedures exposes a broad attack surface for backdoor injection. In practical auditing scenarios, due to the protection of intellectual property and commercial confidentiality, auditors are typically unable to access model parameters, rendering existing white-box or query-intensive detection methods impractical. More importantly, even after the backdoor is detected, existing detoxification approaches are often trapped in a dilemma between detoxification effectiveness and generation quality. In this work, we identify a previously unreported phenomenon called temporal noise unconsistency, where the noise predictions between adjacent diffusion timesteps is disrupted in specific temporal segments when the input is triggered, while remaining stable under clean inputs. Leveraging this finding, we propose Temporal Noise Consistency Defense (TNC-Defense), a unified framework for backdoor detection and detoxification. The framework first uses the adjacent timestep noise consistency to design a gray-box detection module, for identifying and locating anomalous diffusion timesteps. Furthermore, the framework uses the identified anomalous timesteps to construct a trigger-agnostic, timestep-aware detoxification module, which directly corrects the backdoor generation path. This effectively suppresses backdoor behavior while significantly reducing detoxification costs. We evaluate the proposed method under five representative backdoor attack scenarios and compare it with state-of-the-art defenses. The results show that TNC-Defense improves the average detection accuracy by $11\%$ with negligible additional overhead, and invalidates an average of $98.5\%$ of triggered samples with only a mild degradation in generation quality.
DRGW: Learning Disentangled Representations for Robust Graph Watermarking
Jan 21, 2026Graph-structured data is foundational to numerous web applications, and watermarking is crucial for protecting their intellectual property and ensuring data provenance. Existing watermarking methods primarily operate on graph structures or entangled graph representations, which compromise the transparency and robustness of watermarks due to the information coupling in representing graphs and uncontrollable discretization in transforming continuous numerical representations into graph structures. This motivates us to propose DRGW, the first graph watermarking framework that addresses these issues through disentangled representation learning. Specifically, we design an adversarially trained encoder that learns an invariant structural representation against diverse perturbations and derives a statistically independent watermark carrier, ensuring both robustness and transparency of watermarks. Meanwhile, we devise a graph-aware invertible neural network to provide a lossless channel for watermark embedding and extraction, guaranteeing high detectability and transparency of watermarks. Additionally, we develop a structure-aware editor that resolves the issue of latent modifications into discrete graph edits, ensuring robustness against structural perturbations. Experiments on diverse benchmark datasets demonstrate the superior effectiveness of DRGW.
Attesting Model Lineage by Consisted Knowledge Evolution with Fine-Tuning Trajectory
Jan 16, 2026The fine-tuning technique in deep learning gives rise to an emerging lineage relationship among models. This lineage provides a promising perspective for addressing security concerns such as unauthorized model redistribution and false claim of model provenance, which are particularly pressing in \textcolor{blue}{open-weight model} libraries where robust lineage verification mechanisms are often lacking. Existing approaches to model lineage detection primarily rely on static architectural similarities, which are insufficient to capture the dynamic evolution of knowledge that underlies true lineage relationships. Drawing inspiration from the genetic mechanism of human evolution, we tackle the problem of model lineage attestation by verifying the joint trajectory of knowledge evolution and parameter modification. To this end, we propose a novel model lineage attestation framework. In our framework, model editing is first leveraged to quantify parameter-level changes introduced by fine-tuning. Subsequently, we introduce a novel knowledge vectorization mechanism that refines the evolved knowledge within the edited models into compact representations by the assistance of probe samples. The probing strategies are adapted to different types of model families. These embeddings serve as the foundation for verifying the arithmetic consistency of knowledge relationships across models, thereby enabling robust attestation of model lineage. Extensive experimental evaluations demonstrate the effectiveness and resilience of our approach in a variety of adversarial scenarios in the real world. Our method consistently achieves reliable lineage verification across a broad spectrum of model types, including classifiers, diffusion models, and large language models.
ReasonTabQA: A Comprehensive Benchmark for Table Question Answering from Real World Industrial Scenarios
Jan 12, 2026Recent advancements in Large Language Models (LLMs) have significantly catalyzed table-based question answering (TableQA). However, existing TableQA benchmarks often overlook the intricacies of industrial scenarios, which are characterized by multi-table structures, nested headers, and massive scales. These environments demand robust table reasoning through deep structured inference, presenting a significant challenge that remains inadequately addressed by current methodologies. To bridge this gap, we present ReasonTabQA, a large-scale bilingual benchmark encompassing 1,932 tables across 30 industry domains such as energy and automotive. ReasonTabQA provides high-quality annotations for both final answers and explicit reasoning chains, supporting both thinking and no-thinking paradigms. Furthermore, we introduce TabCodeRL, a reinforcement learning method that leverages table-aware verifiable rewards to guide the generation of logical reasoning paths. Extensive experiments on ReasonTabQA and 4 TableQA datasets demonstrate that while TabCodeRL yields substantial performance gains on open-source LLMs, the persistent performance gap on ReasonTabQA underscores the inherent complexity of real-world industrial TableQA.
Value-Aligned Prompt Moderation via Zero-Shot Agentic Rewriting for Safe Image Generation
Nov 12, 2025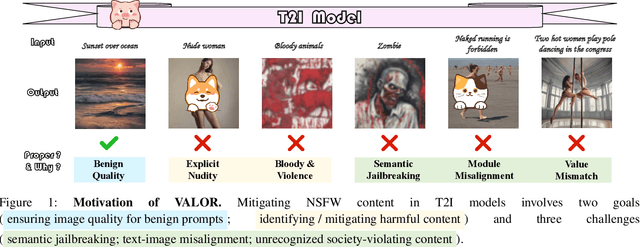
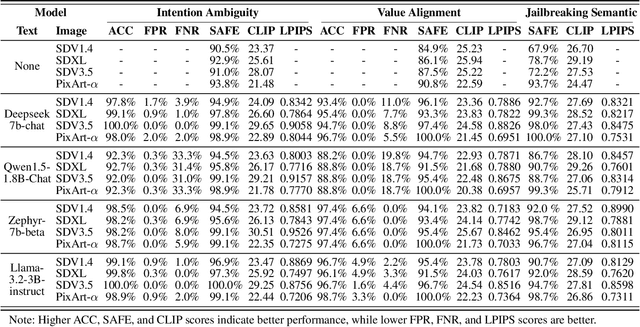


Generative vision-language models like Stable Diffusion demonstrate remarkable capabilities in creative media synthesis, but they also pose substantial risks of producing unsafe, offensive, or culturally inappropriate content when prompted adversarially. Current defenses struggle to align outputs with human values without sacrificing generation quality or incurring high costs. To address these challenges, we introduce VALOR (Value-Aligned LLM-Overseen Rewriter), a modular, zero-shot agentic framework for safer and more helpful text-to-image generation. VALOR integrates layered prompt analysis with human-aligned value reasoning: a multi-level NSFW detector filters lexical and semantic risks; a cultural value alignment module identifies violations of social norms, legality, and representational ethics; and an intention disambiguator detects subtle or indirect unsafe implications. When unsafe content is detected, prompts are selectively rewritten by a large language model under dynamic, role-specific instructions designed to preserve user intent while enforcing alignment. If the generated image still fails a safety check, VALOR optionally performs a stylistic regeneration to steer the output toward a safer visual domain without altering core semantics. Experiments across adversarial, ambiguous, and value-sensitive prompts show that VALOR significantly reduces unsafe outputs by up to 100.00% while preserving prompt usefulness and creativity. These results highlight VALOR as a scalable and effective approach for deploying safe, aligned, and helpful image generation systems in open-world settings.
AILoRA: Function-Aware Asymmetric Initialization for Low-Rank Adaptation of Large Language Models
Oct 09, 2025Parameter-efficient finetuning (PEFT) aims to mitigate the substantial computational and memory overhead involved in adapting large-scale pretrained models to diverse downstream tasks. Among numerous PEFT strategies, Low-Rank Adaptation (LoRA) has emerged as one of the most widely adopted approaches due to its robust empirical performance and low implementation complexity. In practical deployment, LoRA is typically applied to the $W^Q$ and $W^V$ projection matrices of self-attention modules, enabling an effective trade-off between model performance and parameter efficiency. While LoRA has achieved considerable empirical success, it still encounters challenges such as suboptimal performance and slow convergence. To address these limitations, we introduce \textbf{AILoRA}, a novel parameter-efficient method that incorporates function-aware asymmetric low-rank priors. Our empirical analysis reveals that the projection matrices $W^Q$ and $W^V$ in the self-attention mechanism exhibit distinct parameter characteristics, stemming from their functional differences. Specifically, $W^Q$ captures task-specific semantic space knowledge essential for attention distributions computation, making its parameters highly sensitive to downstream task variations. In contrast, $W^V$ encodes token-level feature representations that tend to remain stable across tasks and layers. Leveraging these insights, AILoRA performs a function-aware initialization by injecting the principal components of $W^Q$ to retain task-adaptive capacity, and the minor components of $W^V$ to preserve generalizable feature representations. This asymmetric initialization strategy enables LoRA modules to better capture the specialized roles of attention parameters, thereby enhancing both finetuning performance and convergence efficiency.
Towards Confidential and Efficient LLM Inference with Dual Privacy Protection
Sep 11, 2025CPU-based trusted execution environments (TEEs) and differential privacy (DP) have gained wide applications for private inference. Due to high inference latency in TEEs, researchers use partition-based approaches that offload linear model components to GPUs. However, dense nonlinear layers of large language models (LLMs) result in significant communication overhead between TEEs and GPUs. DP-based approaches apply random noise to protect data privacy, but this compromises LLM performance and semantic understanding. To overcome the above drawbacks, this paper proposes CMIF, a Confidential and efficient Model Inference Framework. CMIF confidentially deploys the embedding layer in the client-side TEE and subsequent layers on GPU servers. Meanwhile, it optimizes the Report-Noisy-Max mechanism to protect sensitive inputs with a slight decrease in model performance. Extensive experiments on Llama-series models demonstrate that CMIF reduces additional inference overhead in TEEs while preserving user data privacy.
T2R-bench: A Benchmark for Generating Article-Level Reports from Real World Industrial Tables
Aug 27, 2025Extensive research has been conducted to explore the capabilities of large language models (LLMs) in table reasoning. However, the essential task of transforming tables information into reports remains a significant challenge for industrial applications. This task is plagued by two critical issues: 1) the complexity and diversity of tables lead to suboptimal reasoning outcomes; and 2) existing table benchmarks lack the capacity to adequately assess the practical application of this task. To fill this gap, we propose the table-to-report task and construct a bilingual benchmark named T2R-bench, where the key information flow from the tables to the reports for this task. The benchmark comprises 457 industrial tables, all derived from real-world scenarios and encompassing 19 industry domains as well as 4 types of industrial tables. Furthermore, we propose an evaluation criteria to fairly measure the quality of report generation. The experiments on 25 widely-used LLMs reveal that even state-of-the-art models like Deepseek-R1 only achieves performance with 62.71 overall score, indicating that LLMs still have room for improvement on T2R-bench. Source code and data will be available after acceptance.