 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflection-Based Task Adaptation for Self-Improving VLA
Oct 14, 2025Pre-trained Vision-Language-Action (VLA) models represent a major leap towards general-purpose robots, yet efficiently adapting them to novel, specific tasks in-situ remains a significant hurdle. While reinforcement learning (RL) is a promising avenue for such adaptation, the process often suffers from low efficiency, hindering rapid task mastery. We introduce Reflective Self-Adaptation, a framework for rapid, autonomous task adaptation without human intervention. Our framework establishes a self-improving loop where the agent learns from its own experience to enhance both strategy and execution. The core of our framework is a dual-pathway architecture that addresses the full adaptation lifecycle. First, a Failure-Driven Reflective RL pathway enables rapid learning by using the VLM's causal reasoning to automatically synthesize a targeted, dense reward function from failure analysis. This provides a focused learning signal that significantly accelerates policy exploration. However, optimizing such proxy rewards introduces a potential risk of "reward hacking," where the agent masters the reward function but fails the actual task. To counteract this, our second pathway, Success-Driven Quality-Guided SFT, grounds the policy in holistic success. It identifies and selectively imitates high-quality successful trajectories, ensuring the agent remains aligned with the ultimate task goal. This pathway is strengthened by a conditional curriculum mechanism to aid initial exploration. We conduct experiments in challenging manipulation tasks. The results demonstrate that our framework achieves faster convergence and higher final success rates compared to representative baselines. Our work presents a robust solution for creating self-improving agents that can efficiently and reliably adapt to new environments.
HOIGen-1M: A Large-scale Dataset for Human-Object Interaction Video Generation
Mar 31, 2025Text-to-video (T2V) generation has made tremendous progress in generating complicated scenes based on texts. However, human-object interaction (HOI) often cannot be precisely generated by current T2V models due to the lack of large-scale videos with accurate captions for HOI. To address this issue, we introduce HOIGen-1M, the first largescale dataset for HOI Generation, consisting of over one million high-quality videos collected from diverse sources. In particular, to guarantee the high quality of videos, we first design an efficient framework to automatically curate HOI videos using the powerful multimodal large language models (MLLMs), and then the videos are further cleaned by human annotators. Moreover, to obtain accurate textual captions for HOI videos, we design a novel video description method based on a Mixture-of-Multimodal-Experts (MoME) strategy that not only generates expressive captions but also eliminates the hallucination by individual MLLM. Furthermore, due to the lack of an evaluation framework for generated HOI videos, we propose two new metrics to assess the quality of generated videos in a coarse-to-fine manner. Extensive experiments reveal that current T2V models struggle to generate high-quality HOI videos and confirm that our HOIGen-1M dataset is instrumental for improving HOI video generation. Project webpage is available at https://liuqi-creat.github.io/HOIGen.github.io.
Scaling Down Text Encoders of Text-to-Image Diffusion Models
Mar 25, 2025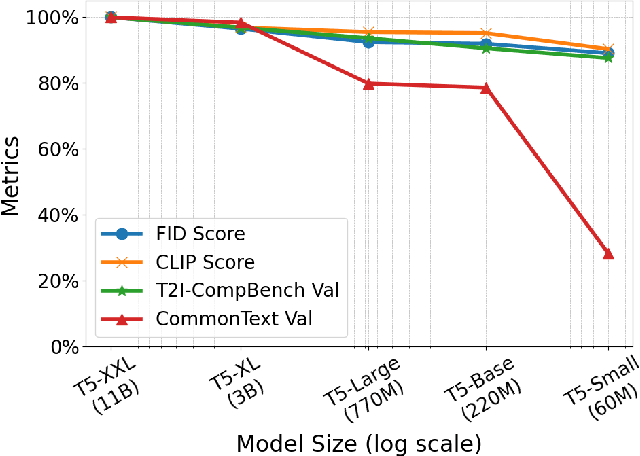
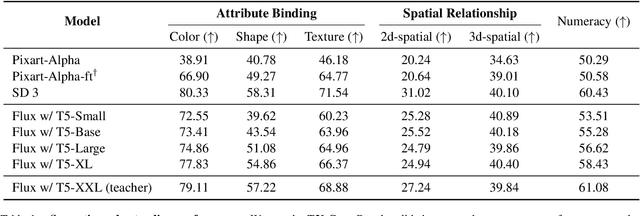
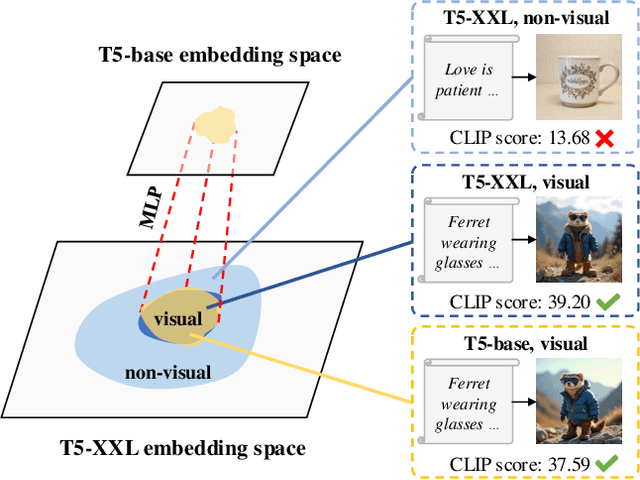
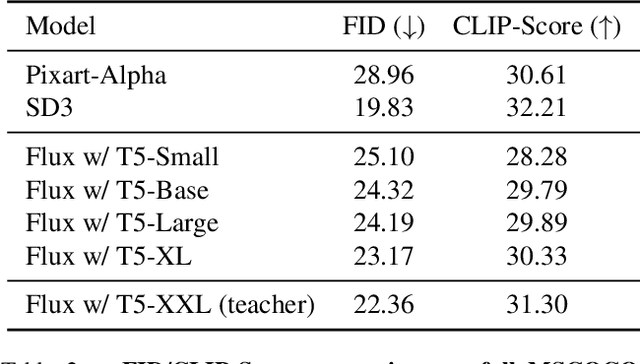
Text encoders in diffusion models have rapidly evolved, transitioning from CLIP to T5-XXL. Although this evolution has significantly enhanced the models' ability to understand complex prompts and generate text, it also leads to a substantial increase in the number of parameters. Despite T5 series encoders being trained on the C4 natural language corpus, which includes a significant amount of non-visual data, diffusion models with T5 encoder do not respond to those non-visual prompts, indicating redundancy in representational power. Therefore, it raises an important question: "Do we really need such a large text encoder?" In pursuit of an answer, we employ vision-based knowledge distillation to train a series of T5 encoder models. To fully inherit its capabilities, we constructed our dataset based on three criteria: image quality, semantic understanding, and text-rendering. Our results demonstrate the scaling down pattern that the distilled T5-base model can generate images of comparable quality to those produced by T5-XXL, while being 50 times smaller in size. This reduction in model size significantly lowers the GPU requirements for running state-of-the-art models such as FLUX and SD3, making high-quality text-to-image generation more accessible.
OmniPrism: Learning Disentangled Visual Concept for Image Generation
Dec 16, 2024



Creative visual concept generation often draws inspiration from specific concepts in a reference image to produce relevant outcomes. However, existing methods are typically constrained to single-aspect concept generation or are easily disrupted by irrelevant concepts in multi-aspect concept scenarios, leading to concept confusion and hindering creative generation. To address this, we propose OmniPrism, a visual concept disentangling approach for creative image generation. Our method learns disentangled concept representations guided by natural language and trains a diffusion model to incorporate these concepts. We utilize the rich semantic space of a multimodal extractor to achieve concept disentanglement from given images and concept guidance. To disentangle concepts with different semantics, we construct a paired concept disentangled dataset (PCD-200K), where each pair shares the same concept such as content, style, and composition. We learn disentangled concept representations through our contrastive orthogonal disentangled (COD) training pipeline, which are then injected into additional diffusion cross-attention layers for generation. A set of block embeddings is designed to adapt each block's concept domain in the diffusion models. Extensive experiments demonstrate that our method can generate high-quality, concept-disentangled results with high fidelity to text prompts and desired concepts.
It Takes Two: Accurate Gait Recognition in the Wild via Cross-granularity Alignment
Nov 16, 2024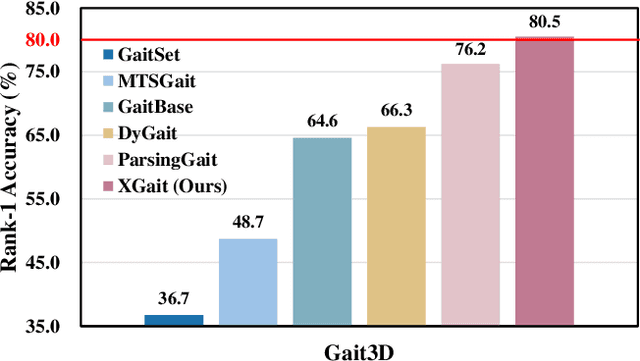
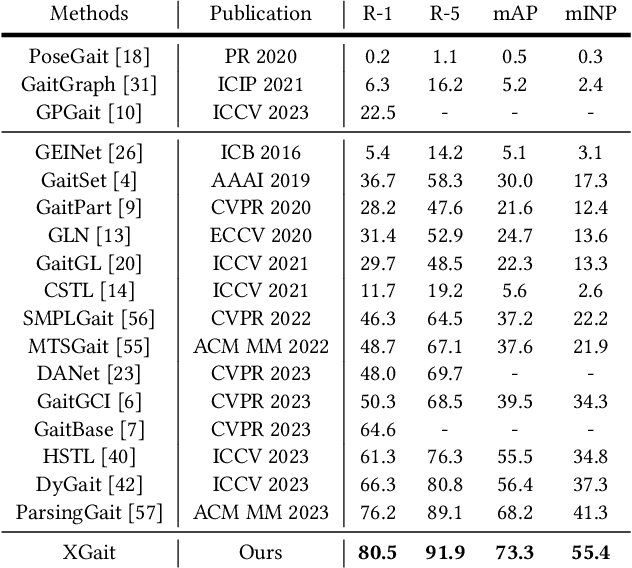
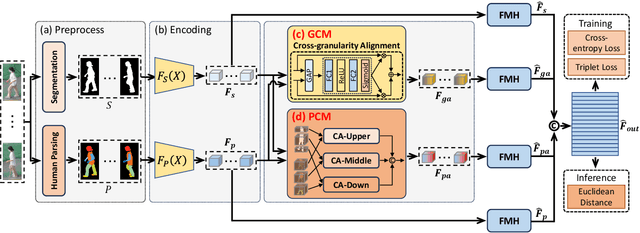
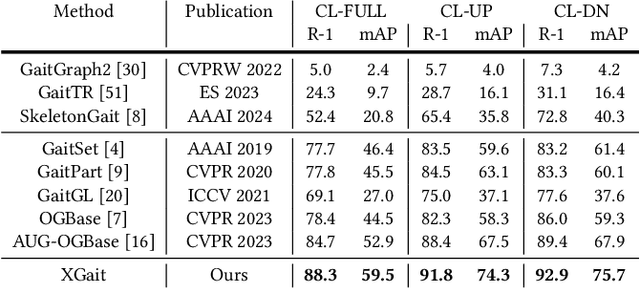
Existing studies for gait recognition primarily utilized sequences of either binary silhouette or human parsing to encode the shapes and dynamics of persons during walking. Silhouettes exhibit accurate segmentation quality and robustness to environmental variations, but their low information entropy may result in sub-optimal performance. In contrast, human parsing provides fine-grained part segmentation with higher information entropy, but the segmentation quality may deteriorate due to the complex environments. To discover the advantages of silhouette and parsing and overcome their limitations, this paper proposes a novel cross-granularity alignment gait recognition method, named XGait, to unleash the power of gait representations of different granularity. To achieve this goal, the XGait first contains two branches of backbone encoders to map the silhouette sequences and the parsing sequences into two latent spaces, respectively. Moreover, to explore the complementary knowledge across the features of two representations, we design the Global Cross-granularity Module (GCM) and the Part Cross-granularity Module (PCM) after the two encoders. In particular, the GCM aims to enhance the quality of parsing features by leveraging global features from silhouettes, while the PCM aligns the dynamics of human parts between silhouette and parsing features using the high information entropy in parsing sequences. In addition, to effectively guide the alignment of two representations with different granularity at the part level, an elaborate-designed learnable division mechanism is proposed for the parsing features. Comprehensive experiments on two large-scale gait datasets not only show the superior performance of XGait with the Rank-1 accuracy of 80.5% on Gait3D and 88.3% CCPG but also reflect the robustness of the learned features even under challenging conditions like occlusions and cloth changes.
Motion Capture from Inertial and Vision Sensors
Jul 23, 2024



Human motion capture is the foundation for many computer vision and graphics tasks. While industrial motion capture systems with complex camera arrays or expensive wearable sensors have been widely adopted in movie and game production, consumer-affordable and easy-to-use solutions for personal applications are still far from mature. To utilize a mixture of a monocular camera and very few inertial measurement units (IMUs) for accurate multi-modal human motion capture in daily life, we contribute MINIONS in this paper, a large-scale Motion capture dataset collected from INertial and visION Sensors. MINIONS has several featured properties: 1) large scale of over five million frames and 400 minutes duration; 2) multi-modality data of IMUs signals and RGB videos labeled with joint positions, joint rotations, SMPL parameters, etc.; 3) a diverse set of 146 fine-grained single and interactive actions with textual descriptions. With the proposed MINIONS, we conduct experiments on multi-modal motion capture and explore the possibilities of consumer-affordable motion capture using a monocular camera and very few IMUs. The experiment results emphasize the unique advantages of inertial and vision sensors, showcasing the promise of consumer-affordable multi-modal motion capture and providing a valuable resource for further research and development.
HumanNeRF-SE: A Simple yet Effective Approach to Animate HumanNeRF with Diverse Poses
Dec 04, 2023We present HumanNeRF-SE, which can synthesize diverse novel pose images with simple input. Previous HumanNeRF studies require large neural networks to fit the human appearance and prior knowledge. Subsequent methods build upon this approach with some improvements. Instead, we reconstruct this approach, combining explicit and implicit human representations with both general and specific mapping processes. Our key insight is that explicit shape can filter the information used to fit implicit representation, and frozen general mapping combined with point-specific mapping can effectively avoid overfitting and improve pose generalization performance. Our explicit and implicit human represent combination architecture is extremely effective. This is reflected in our model's ability to synthesize images under arbitrary poses with few-shot input and increase the speed of synthesizing images by 15 times through a reduction in computational complexity without using any existing acceleration modules. Compared to the state-of-the-art HumanNeRF studies, HumanNeRF-SE achieves better performance with fewer learnable parameters and less training time (see Figure 1).
SigFormer: Sparse Signal-Guided Transformer for Multi-Modal Human Action Segmentation
Nov 29, 2023



Multi-modal human action segmentation is a critical and challenging task with a wide range of applications. Nowadays, the majority of approaches concentrate on the fusion of dense signals (i.e., RGB, optical flow, and depth maps). However, the potential contributions of sparse IoT sensor signals, which can be crucial for achieving accurate recognition, have not been fully explored. To make up for this, we introduce a Sparse signalguided Transformer (SigFormer) to combine both dense and sparse signals. We employ mask attention to fuse localized features by constraining cross-attention within the regions where sparse signals are valid. However, since sparse signals are discrete, they lack sufficient information about the temporal action boundaries. Therefore, in SigFormer, we propose to emphasize the boundary information at two stages to alleviate this problem. In the first feature extraction stage, we introduce an intermediate bottleneck module to jointly learn both category and boundary features of each dense modality through the inner loss functions. After the fusion of dense modalities and sparse signals, we then devise a two-branch architecture that explicitly models the interrelationship between action category and temporal boundary. Experimental results demonstrate that SigFormer outperforms the state-of-the-art approaches on a multi-modal action segmentation dataset from real industrial environments, reaching an outstanding F1 score of 0.958. The codes and pre-trained models have been available at https://github.com/LIUQI-creat/SigFormer.
Parsing is All You Need for Accurate Gait Recognition in the Wild
Aug 31, 2023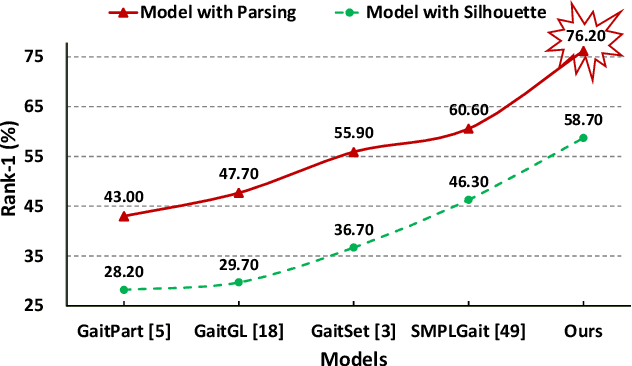
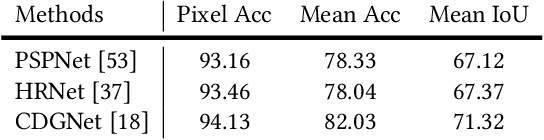
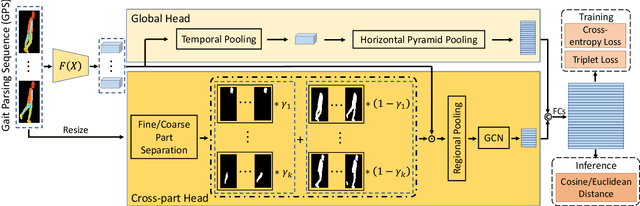
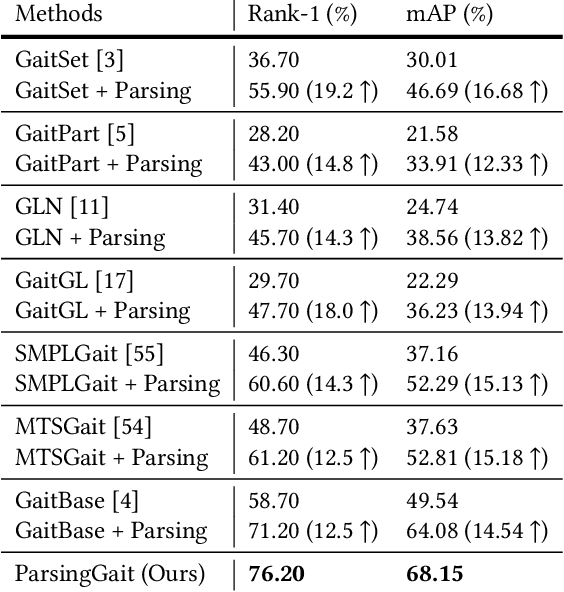
Binary silhouettes and keypoint-based skeletons have dominated human gait recognition studies for decades since they are easy to extract from video frames. Despite their success in gait recognition for in-the-lab environments, they usually fail in real-world scenarios due to their low information entropy for gait representations. To achieve accurate gait recognition in the wild, this paper presents a novel gait representation, named Gait Parsing Sequence (GPS). GPSs are sequences of fine-grained human segmentation, i.e., human parsing, extracted from video frames, so they have much higher information entropy to encode the shapes and dynamics of fine-grained human parts during walking. Moreover, to effectively explore the capability of the GPS representation, we propose a novel human parsing-based gait recognition framework, named ParsingGait. ParsingGait contains a Convolutional Neural Network (CNN)-based backbone and two light-weighted heads. The first head extracts global semantic features from GPSs, while the other one learns mutual information of part-level features through Graph Convolutional Networks to model the detailed dynamics of human walking. Furthermore, due to the lack of suitable datasets, we build the first parsing-based dataset for gait recognition in the wild, named Gait3D-Parsing, by extending the large-scale and challenging Gait3D dataset. Based on Gait3D-Parsing, we comprehensively evaluate our method and existing gait recognition methods. The experimental results show a significant improvement in accuracy brought by the GPS representation and the superiority of ParsingGait. The code and dataset are available at https://gait3d.github.io/gait3d-parsing-hp .
Gait Recognition in the Wild with Dense 3D Representations and A Benchmark
Apr 06, 2022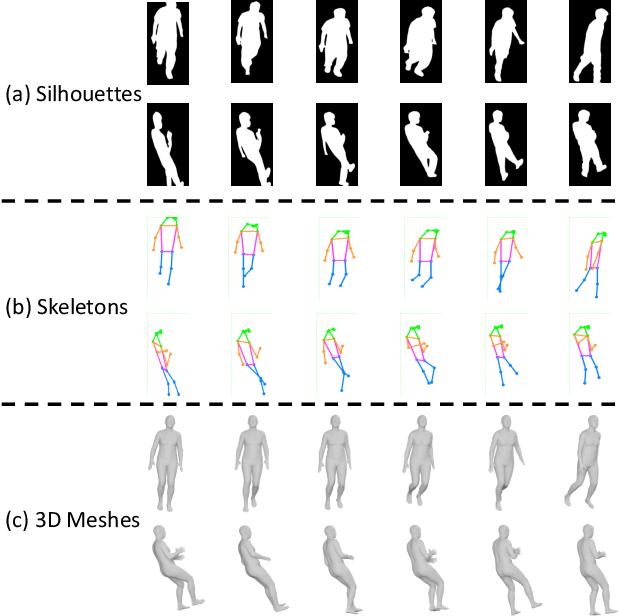
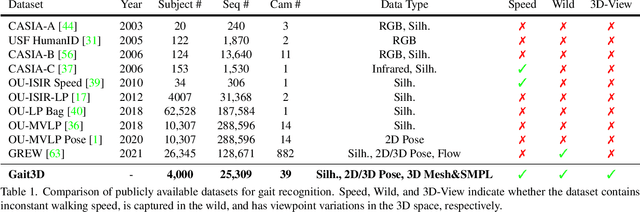
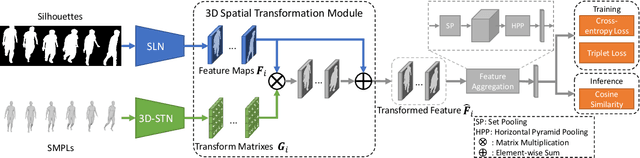
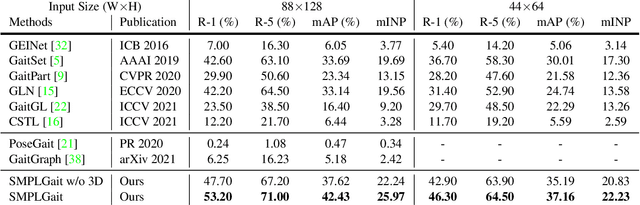
Existing studies for gait recognition are dominated by 2D representations like the silhouette or skeleton of the human body in constrained scenes. However, humans live and walk in the unconstrained 3D space, so projecting the 3D human body onto the 2D plane will discard a lot of crucial information like the viewpoint, shape, and dynamics for gait recognition. Therefore, this paper aims to explore dense 3D representations for gait recognition in the wild, which is a practical yet neglected problem. In particular, we propose a novel framework to explore the 3D Skinned Multi-Person Linear (SMPL) model of the human body for gait recognition, named SMPLGait. Our framework has two elaborately-designed branches of which one extracts appearance features from silhouettes, the other learns knowledge of 3D viewpoints and shapes from the 3D SMPL model. In addition, due to the lack of suitable datasets, we build the first large-scale 3D representation-based gait recognition dataset, named Gait3D. It contains 4,000 subjects and over 25,000 sequences extracted from 39 cameras in an unconstrained indoor scene. More importantly, it provides 3D SMPL models recovered from video frames which can provide dense 3D information of body shape, viewpoint, and dynamics. Based on Gait3D, we comprehensively compare our method with existing gait recognition approaches, which reflects the superior performance of our framework and the potential of 3D representations for gait recognition in the wild. The code and dataset are available at https://gait3d.github.io.