 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025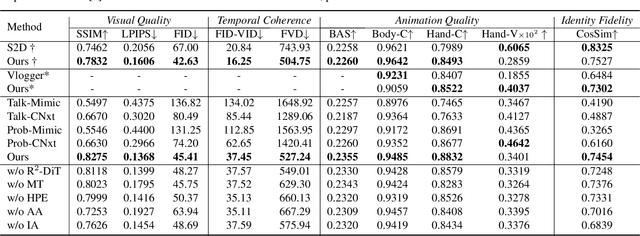
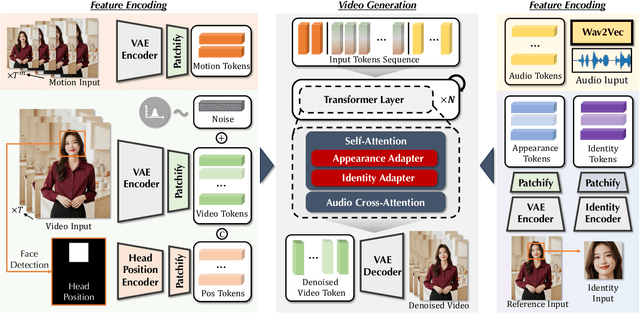
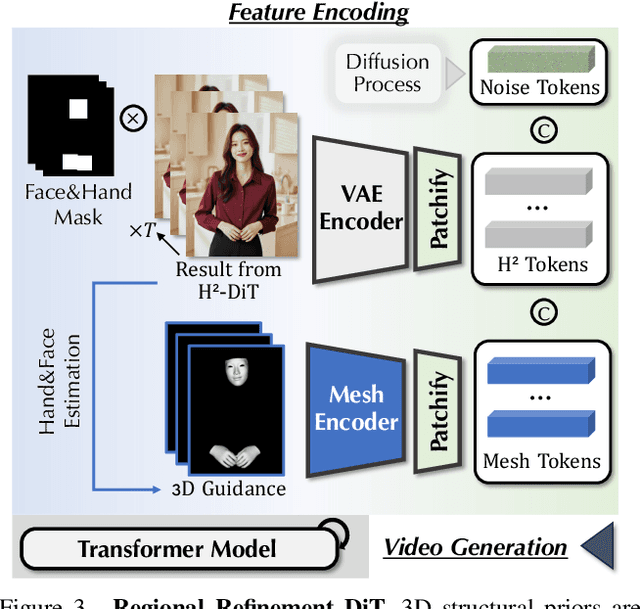

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
Cosh-DiT: Co-Speech Gesture Video Synthesis via Hybrid Audio-Visual Diffusion Transformers
Mar 13, 2025Co-speech gesture video synthesis is a challenging task that requires both probabilistic modeling of human gestures and the synthesis of realistic images that align with the rhythmic nuances of speech. To address these challenges, we propose Cosh-DiT, a Co-speech gesture video system with hybrid Diffusion Transformers that perform audio-to-motion and motion-to-video synthesis using discrete and continuous diffusion modeling, respectively. First, we introduce an audio Diffusion Transformer (Cosh-DiT-A) to synthesize expressive gesture dynamics synchronized with speech rhythms. To capture upper body, facial, and hand movement priors, we employ vector-quantized variational autoencoders (VQ-VAEs) to jointly learn their dependencies within a discrete latent space. Then, for realistic video synthesis conditioned on the generated speech-driven motion, we design a visual Diffusion Transformer (Cosh-DiT-V) that effectively integrates spatial and temporal contexts. Extensive experiments demonstrate that our framework consistently generates lifelike videos with expressive facial expressions and natural, smooth gestures that align seamlessly with speech.
TALK-Act: Enhance Textural-Awareness for 2D Speaking Avatar Reenactment with Diffusion Model
Oct 14, 2024

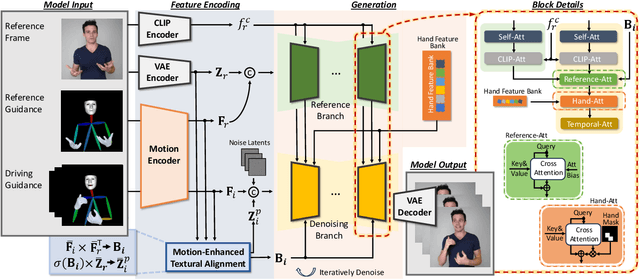

Recently, 2D speaking avatars have increasingly participated in everyday scenarios due to the fast development of facial animation techniques. However, most existing works neglect the explicit control of human bodies. In this paper, we propose to drive not only the faces but also the torso and gesture movements of a speaking figure. Inspired by recent advances in diffusion models, we propose the Motion-Enhanced Textural-Aware ModeLing for SpeaKing Avatar Reenactment (TALK-Act) framework, which enables high-fidelity avatar reenactment from only short footage of monocular video. Our key idea is to enhance the textural awareness with explicit motion guidance in diffusion modeling. Specifically, we carefully construct 2D and 3D structural information as intermediate guidance. While recent diffusion models adopt a side network for control information injection, they fail to synthesize temporally stable results even with person-specific fine-tuning. We propose a Motion-Enhanced Textural Alignment module to enhance the bond between driving and target signals. Moreover, we build a Memory-based Hand-Recovering module to help with the difficulties in hand-shape preserving. After pre-training, our model can achieve high-fidelity 2D avatar reenactment with only 30 seconds of person-specific data. Extensive experiments demonstrate the effectiveness and superiority of our proposed framework. Resources can be found at https://guanjz20.github.io/projects/TALK-Act.
Motion Capture from Inertial and Vision Sensors
Jul 23, 2024



Human motion capture is the foundation for many computer vision and graphics tasks. While industrial motion capture systems with complex camera arrays or expensive wearable sensors have been widely adopted in movie and game production, consumer-affordable and easy-to-use solutions for personal applications are still far from mature. To utilize a mixture of a monocular camera and very few inertial measurement units (IMUs) for accurate multi-modal human motion capture in daily life, we contribute MINIONS in this paper, a large-scale Motion capture dataset collected from INertial and visION Sensors. MINIONS has several featured properties: 1) large scale of over five million frames and 400 minutes duration; 2) multi-modality data of IMUs signals and RGB videos labeled with joint positions, joint rotations, SMPL parameters, etc.; 3) a diverse set of 146 fine-grained single and interactive actions with textual descriptions. With the proposed MINIONS, we conduct experiments on multi-modal motion capture and explore the possibilities of consumer-affordable motion capture using a monocular camera and very few IMUs. The experiment results emphasize the unique advantages of inertial and vision sensors, showcasing the promise of consumer-affordable multi-modal motion capture and providing a valuable resource for further research and development.