 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Paper and Code
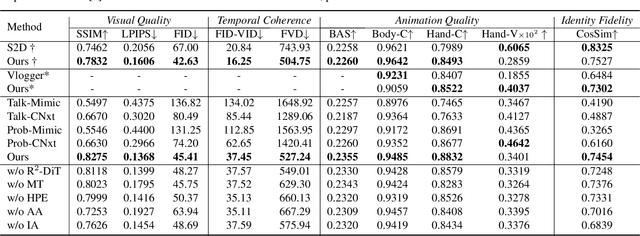
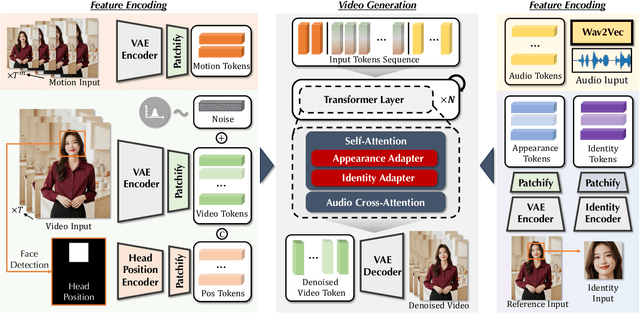
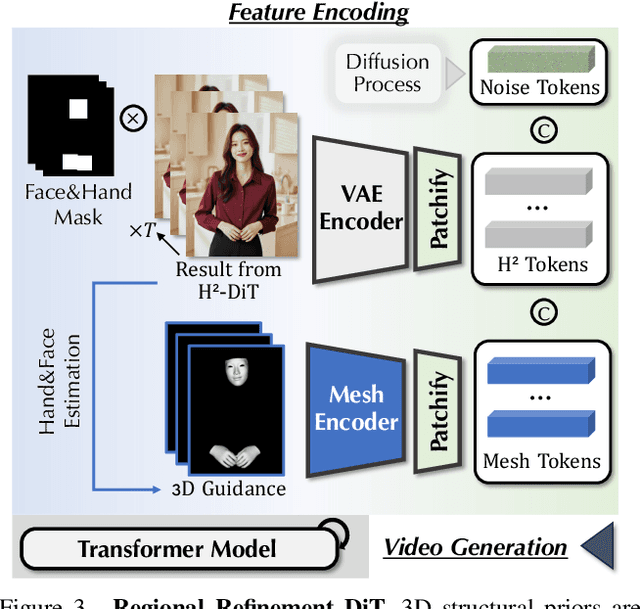

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.