 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025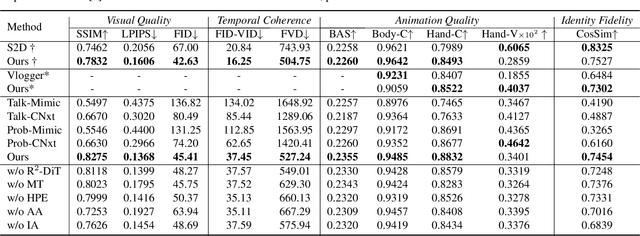
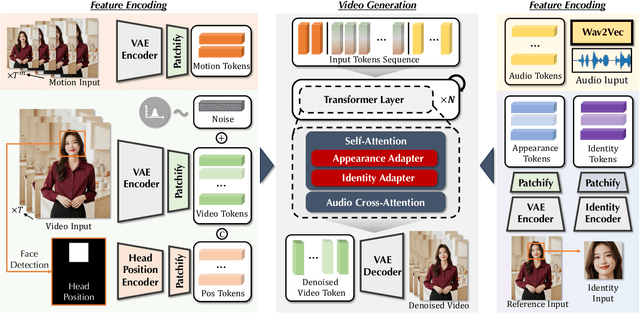
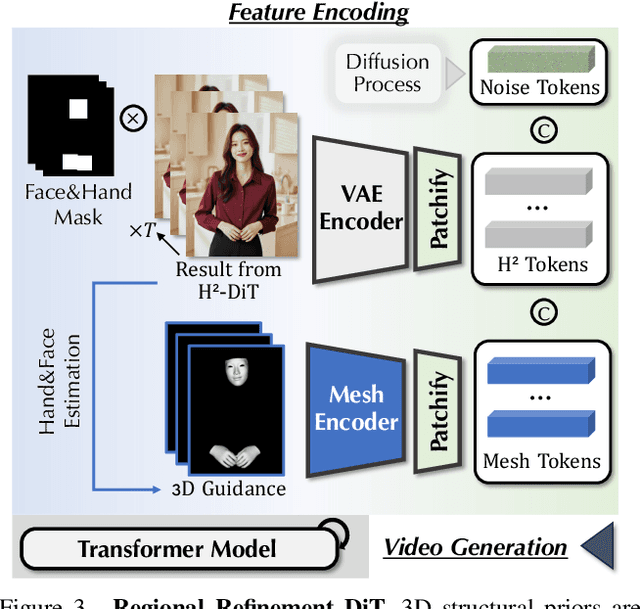

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
Cosh-DiT: Co-Speech Gesture Video Synthesis via Hybrid Audio-Visual Diffusion Transformers
Mar 13, 2025Co-speech gesture video synthesis is a challenging task that requires both probabilistic modeling of human gestures and the synthesis of realistic images that align with the rhythmic nuances of speech. To address these challenges, we propose Cosh-DiT, a Co-speech gesture video system with hybrid Diffusion Transformers that perform audio-to-motion and motion-to-video synthesis using discrete and continuous diffusion modeling, respectively. First, we introduce an audio Diffusion Transformer (Cosh-DiT-A) to synthesize expressive gesture dynamics synchronized with speech rhythms. To capture upper body, facial, and hand movement priors, we employ vector-quantized variational autoencoders (VQ-VAEs) to jointly learn their dependencies within a discrete latent space. Then, for realistic video synthesis conditioned on the generated speech-driven motion, we design a visual Diffusion Transformer (Cosh-DiT-V) that effectively integrates spatial and temporal contexts. Extensive experiments demonstrate that our framework consistently generates lifelike videos with expressive facial expressions and natural, smooth gestures that align seamlessly with speech.
ReSyncer: Rewiring Style-based Generator for Unified Audio-Visually Synced Facial Performer
Aug 06, 2024



Lip-syncing videos with given audio is the foundation for various applications including the creation of virtual presenters or performers. While recent studies explore high-fidelity lip-sync with different techniques, their task-orientated models either require long-term videos for clip-specific training or retain visible artifacts. In this paper, we propose a unified and effective framework ReSyncer, that synchronizes generalized audio-visual facial information. The key design is revisiting and rewiring the Style-based generator to efficiently adopt 3D facial dynamics predicted by a principled style-injected Transformer. By simply re-configuring the information insertion mechanisms within the noise and style space, our framework fuses motion and appearance with unified training. Extensive experiments demonstrate that ReSyncer not only produces high-fidelity lip-synced videos according to audio, but also supports multiple appealing properties that are suitable for creating virtual presenters and performers, including fast personalized fine-tuning, video-driven lip-syncing, the transfer of speaking styles, and even face swapping. Resources can be found at https://guanjz20.github.io/projects/ReSyncer.
Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes
Apr 13, 2019
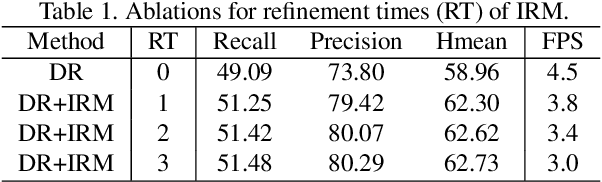
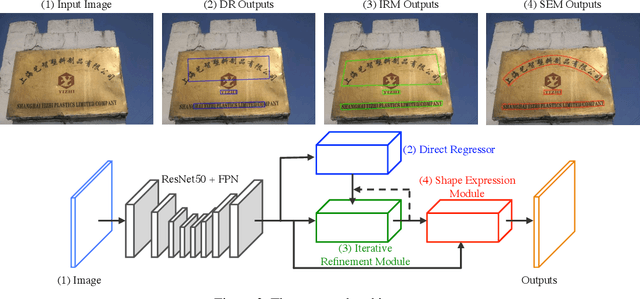

Previous scene text detection methods have progressed substantially over the past years. However, limited by the receptive field of CNNs and the simple representations like rectangle bounding box or quadrangle adopted to describe text, previous methods may fall short when dealing with more challenging text instances, such as extremely long text and arbitrarily shaped text. To address these two problems, we present a novel text detector namely LOMO, which localizes the text progressively for multiple times (or in other word, LOok More than Once). LOMO consists of a direct regressor (DR), an iterative refinement module (IRM) and a shape expression module (SEM). At first, text proposals in the form of quadrangle are generated by DR branch. Next, IRM progressively perceives the entire long text by iterative refinement based on the extracted feature blocks of preliminary proposals. Finally, a SEM is introduced to reconstruct more precise representation of irregular text by considering the geometry properties of text instance, including text region, text center line and border offsets. The state-of-the-art results on several public benchmarks including ICDAR2017-RCTW, SCUT-CTW1500, Total-Text, ICDAR2015 and ICDAR17-MLT confirm the striking robustness and effectiveness of LOMO.
Lightweight Pyramid Networks for Image Deraining
May 16, 2018


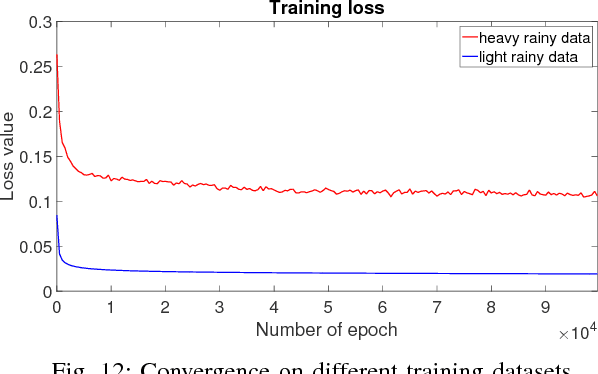
Existing deep convolutional neural networks have found major success in image deraining, but at the expense of an enormous number of parameters. This limits their potential application, for example in mobile devices. In this paper, we propose a lightweight pyramid of networks (LPNet) for single image deraining. Instead of designing a complex network structures, we use domain-specific knowledge to simplify the learning process. Specifically, we find that by introducing the mature Gaussian-Laplacian image pyramid decomposition technology to the neural network, the learning problem at each pyramid level is greatly simplified and can be handled by a relatively shallow network with few parameters. We adopt recursive and residual network structures to build the proposed LPNet, which has less than 8K parameters while still achieving state-of-the-art performance on rain removal. We also discuss the potential value of LPNet for other low- and high-level vision tasks.