 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning
Aug 15, 2019



Detecting scene text of arbitrary shapes has been a challenging task over the past years. In this paper, we propose a novel segmentation-based text detector, namely SAST, which employs a context attended multi-task learning framework based on a Fully Convolutional Network (FCN) to learn various geometric properties for the reconstruction of polygonal representation of text regions. Taking sequential characteristics of text into consideration, a Context Attention Block is introduced to capture long-range dependencies of pixel information to obtain a more reliable segmentation. In post-processing, a Point-to-Quad assignment method is proposed to cluster pixels into text instances by integrating both high-level object knowledge and low-level pixel information in a single shot. Moreover, the polygonal representation of arbitrarily-shaped text can be extracted with the proposed geometric properties much more effectively. Experiments on several benchmarks, including ICDAR2015, ICDAR2017-MLT, SCUT-CTW1500, and Total-Text, demonstrate that SAST achieves better or comparable performance in terms of accuracy. Furthermore, the proposed algorithm runs at 27.63 FPS on SCUT-CTW1500 with a Hmean of 81.0% on a single NVIDIA Titan Xp graphics card, surpassing most of the existing segmentation-based methods.
* 9 pages, 6 figures, 7 tables, To appear in ACM Multimedia 2019
Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes
Apr 13, 2019
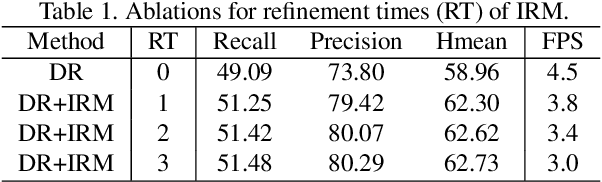
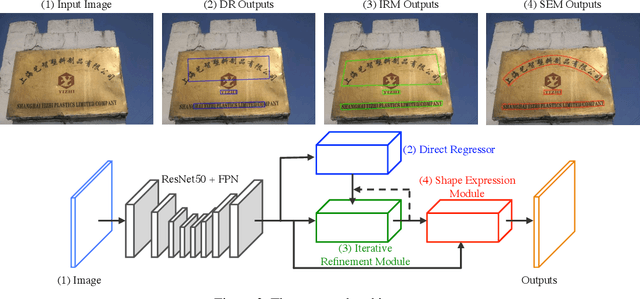

Previous scene text detection methods have progressed substantially over the past years. However, limited by the receptive field of CNNs and the simple representations like rectangle bounding box or quadrangle adopted to describe text, previous methods may fall short when dealing with more challenging text instances, such as extremely long text and arbitrarily shaped text. To address these two problems, we present a novel text detector namely LOMO, which localizes the text progressively for multiple times (or in other word, LOok More than Once). LOMO consists of a direct regressor (DR), an iterative refinement module (IRM) and a shape expression module (SEM). At first, text proposals in the form of quadrangle are generated by DR branch. Next, IRM progressively perceives the entire long text by iterative refinement based on the extracted feature blocks of preliminary proposals. Finally, a SEM is introduced to reconstruct more precise representation of irregular text by considering the geometry properties of text instance, including text region, text center line and border offsets. The state-of-the-art results on several public benchmarks including ICDAR2017-RCTW, SCUT-CTW1500, Total-Text, ICDAR2015 and ICDAR17-MLT confirm the striking robustness and effectiveness of LOMO.