 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTakeAD: Preference-based Post-optimization for End-to-end Autonomous Driving with Expert Takeover Data
Dec 22, 2025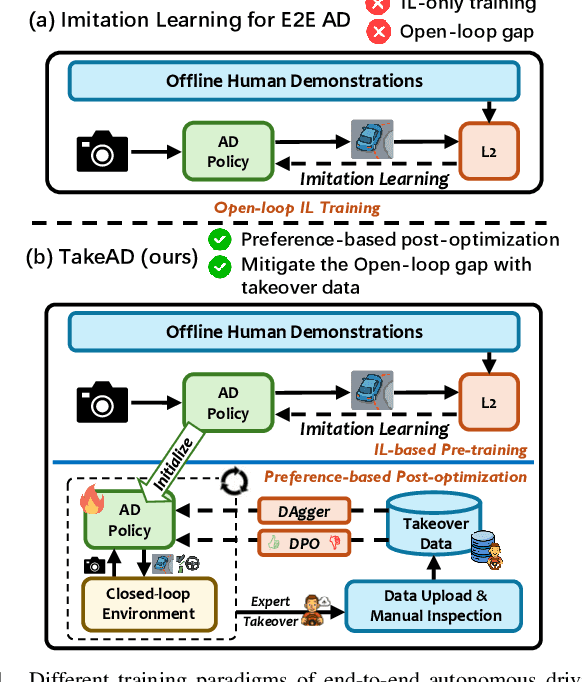
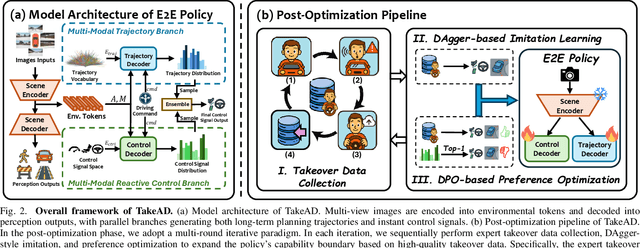
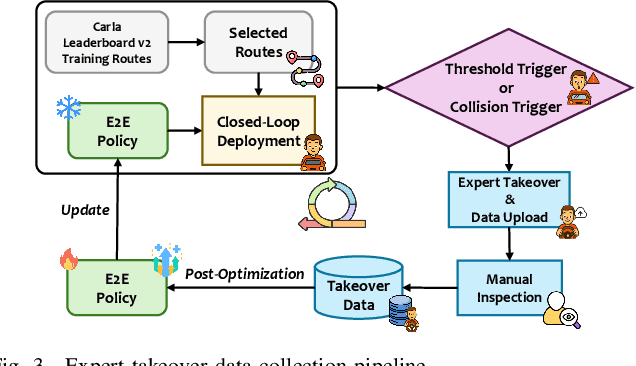
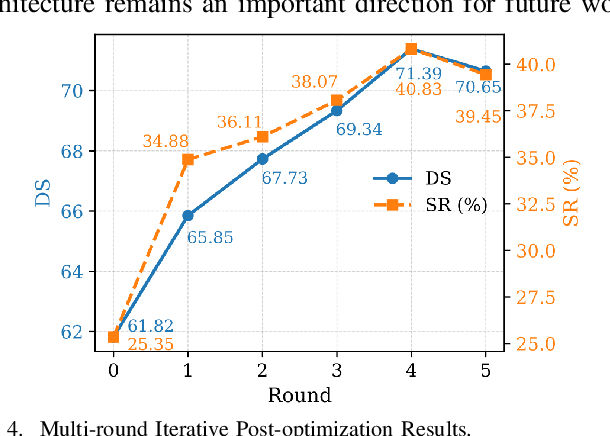
Existing end-to-end autonomous driving methods typically rely on imitation learning (IL) but face a key challenge: the misalignment between open-loop training and closed-loop deployment. This misalignment often triggers driver-initiated takeovers and system disengagements during closed-loop execution. How to leverage those expert takeover data from disengagement scenarios and effectively expand the IL policy's capability presents a valuable yet unexplored challenge. In this paper, we propose TakeAD, a novel preference-based post-optimization framework that fine-tunes the pre-trained IL policy with this disengagement data to enhance the closed-loop driving performance. First, we design an efficient expert takeover data collection pipeline inspired by human takeover mechanisms in real-world autonomous driving systems. Then, this post optimization framework integrates iterative Dataset Aggregation (DAgger) for imitation learning with Direct Preference Optimization (DPO) for preference alignment. The DAgger stage equips the policy with fundamental capabilities to handle disengagement states through direct imitation of expert interventions. Subsequently, the DPO stage refines the policy's behavior to better align with expert preferences in disengagement scenarios. Through multiple iterations, the policy progressively learns recovery strategies for disengagement states, thereby mitigating the open-loop gap. Experiments on the closed-loop Bench2Drive benchmark demonstrate our method's effectiveness compared with pure IL methods, with comprehensive ablations confirming the contribution of each component.
World knowledge-enhanced Reasoning Using Instruction-guided Interactor in Autonomous Driving
Dec 09, 2024The Multi-modal Large Language Models (MLLMs) with extensive world knowledge have revitalized autonomous driving, particularly in reasoning tasks within perceivable regions. However, when faced with perception-limited areas (dynamic or static occlusion regions), MLLMs struggle to effectively integrate perception ability with world knowledge for reasoning. These perception-limited regions can conceal crucial safety information, especially for vulnerable road users. In this paper, we propose a framework, which aims to improve autonomous driving performance under perceptionlimited conditions by enhancing the integration of perception capabilities and world knowledge. Specifically, we propose a plug-and-play instruction-guided interaction module that bridges modality gaps and significantly reduces the input sequence length, allowing it to adapt effectively to multi-view video inputs. Furthermore, to better integrate world knowledge with driving-related tasks, we have collected and refined a large-scale multi-modal dataset that includes 2 million natural language QA pairs, 1.7 million grounding task data. To evaluate the model's utilization of world knowledge, we introduce an object-level risk assessment dataset comprising 200K QA pairs, where the questions necessitate multi-step reasoning leveraging world knowledge for resolution. Extensive experiments validate the effectiveness of our proposed method.
Seeing Beyond Views: Multi-View Driving Scene Video Generation with Holistic Attention
Dec 04, 2024Generating multi-view videos for autonomous driving training has recently gained much attention, with the challenge of addressing both cross-view and cross-frame consistency. Existing methods typically apply decoupled attention mechanisms for spatial, temporal, and view dimensions. However, these approaches often struggle to maintain consistency across dimensions, particularly when handling fast-moving objects that appear at different times and viewpoints. In this paper, we present CogDriving, a novel network designed for synthesizing high-quality multi-view driving videos. CogDriving leverages a Diffusion Transformer architecture with holistic-4D attention modules, enabling simultaneous associations across the spatial, temporal, and viewpoint dimensions. We also propose a lightweight controller tailored for CogDriving, i.e., Micro-Controller, which uses only 1.1% of the parameters of the standard ControlNet, enabling precise control over Bird's-Eye-View layouts. To enhance the generation of object instances crucial for autonomous driving, we propose a re-weighted learning objective, dynamically adjusting the learning weights for object instances during training. CogDriving demonstrates strong performance on the nuScenes validation set, achieving an FVD score of 37.8, highlighting its ability to generate realistic driving videos. The project can be found at https://luhannan.github.io/CogDrivingPage/.
Decoupled Pseudo-labeling for Semi-Supervised Monocular 3D Object Detection
Mar 26, 2024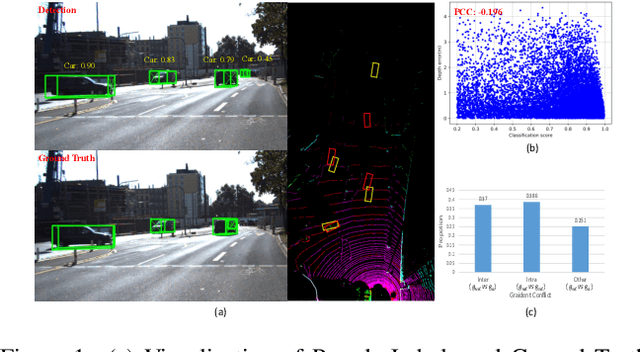
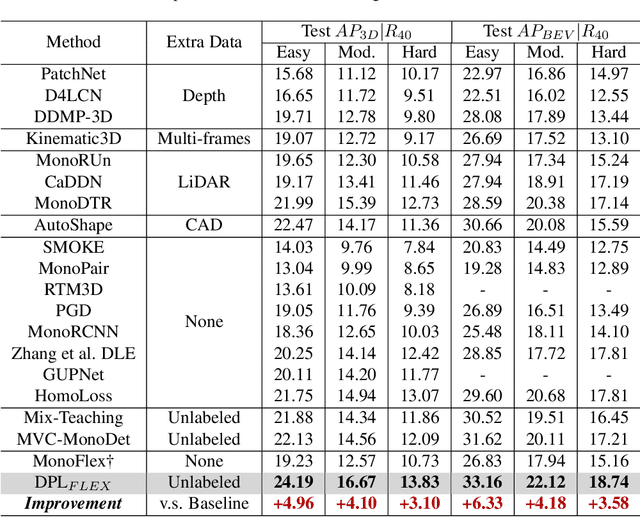
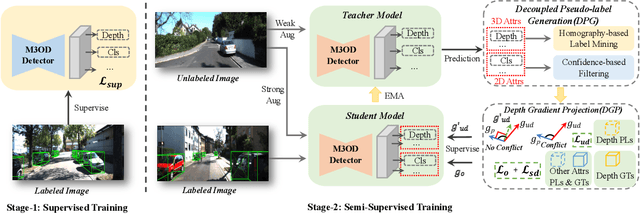

We delve into pseudo-labeling for semi-supervised monocular 3D object detection (SSM3OD) and discover two primary issues: a misalignment between the prediction quality of 3D and 2D attributes and the tendency of depth supervision derived from pseudo-labels to be noisy, leading to significant optimization conflicts with other reliable forms of supervision. We introduce a novel decoupled pseudo-labeling (DPL) approach for SSM3OD. Our approach features a Decoupled Pseudo-label Generation (DPG) module, designed to efficiently generate pseudo-labels by separately processing 2D and 3D attributes. This module incorporates a unique homography-based method for identifying dependable pseudo-labels in BEV space, specifically for 3D attributes. Additionally, we present a DepthGradient Projection (DGP) module to mitigate optimization conflicts caused by noisy depth supervision of pseudo-labels, effectively decoupling the depth gradient and removing conflicting gradients. This dual decoupling strategy-at both the pseudo-label generation and gradient levels-significantly improves the utilization of pseudo-labels in SSM3OD. Our comprehensive experiments on the KITTI benchmark demonstrate the superiority of our method over existing approaches.
Gradient-based Sampling for Class Imbalanced Semi-supervised Object Detection
Mar 22, 2024



Current semi-supervised object detection (SSOD) algorithms typically assume class balanced datasets (PASCAL VOC etc.) or slightly class imbalanced datasets (MS-COCO, etc). This assumption can be easily violated since real world datasets can be extremely class imbalanced in nature, thus making the performance of semi-supervised object detectors far from satisfactory. Besides, the research for this problem in SSOD is severely under-explored. To bridge this research gap, we comprehensively study the class imbalance problem for SSOD under more challenging scenarios, thus forming the first experimental setting for class imbalanced SSOD (CI-SSOD). Moreover, we propose a simple yet effective gradient-based sampling framework that tackles the class imbalance problem from the perspective of two types of confirmation biases. To tackle confirmation bias towards majority classes, the gradient-based reweighting and gradient-based thresholding modules leverage the gradients from each class to fully balance the influence of the majority and minority classes. To tackle the confirmation bias from incorrect pseudo labels of minority classes, the class-rebalancing sampling module resamples unlabeled data following the guidance of the gradient-based reweighting module. Experiments on three proposed sub-tasks, namely MS-COCO, MS-COCO to Object365 and LVIS, suggest that our method outperforms current class imbalanced object detectors by clear margins, serving as a baseline for future research in CI-SSOD. Code will be available at https://github.com/nightkeepers/CI-SSOD.
Layered Rendering Diffusion Model for Zero-Shot Guided Image Synthesis
Nov 30, 2023This paper introduces innovative solutions to enhance spatial controllability in diffusion models reliant on text queries. We present two key innovations: Vision Guidance and the Layered Rendering Diffusion (LRDiff) framework. Vision Guidance, a spatial layout condition, acts as a clue in the perturbed distribution, greatly narrowing down the search space, to focus on the image sampling process adhering to the spatial layout condition. The LRDiff framework constructs an image-rendering process with multiple layers, each of which applies the vision guidance to instructively estimate the denoising direction for a single object. Such a layered rendering strategy effectively prevents issues like unintended conceptual blending or mismatches, while allowing for more coherent and contextually accurate image synthesis. The proposed method provides a more efficient and accurate means of synthesising images that align with specific spatial and contextual requirements. We demonstrate through our experiments that our method provides better results than existing techniques both quantitatively and qualitatively. We apply our method to three practical applications: bounding box-to-image, semantic mask-to-image and image editing.
HAP: Structure-Aware Masked Image Modeling for Human-Centric Perception
Oct 31, 2023Model pre-training is essential in human-centric perception. In this paper, we first introduce masked image modeling (MIM) as a pre-training approach for this task. Upon revisiting the MIM training strategy, we reveal that human structure priors offer significant potential. Motivated by this insight, we further incorporate an intuitive human structure prior - human parts - into pre-training. Specifically, we employ this prior to guide the mask sampling process. Image patches, corresponding to human part regions, have high priority to be masked out. This encourages the model to concentrate more on body structure information during pre-training, yielding substantial benefits across a range of human-centric perception tasks. To further capture human characteristics, we propose a structure-invariant alignment loss that enforces different masked views, guided by the human part prior, to be closely aligned for the same image. We term the entire method as HAP. HAP simply uses a plain ViT as the encoder yet establishes new state-of-the-art performance on 11 human-centric benchmarks, and on-par result on one dataset. For example, HAP achieves 78.1% mAP on MSMT17 for person re-identification, 86.54% mA on PA-100K for pedestrian attribute recognition, 78.2% AP on MS COCO for 2D pose estimation, and 56.0 PA-MPJPE on 3DPW for 3D pose and shape estimation.
Accelerating Vision Transformers Based on Heterogeneous Attention Patterns
Oct 11, 2023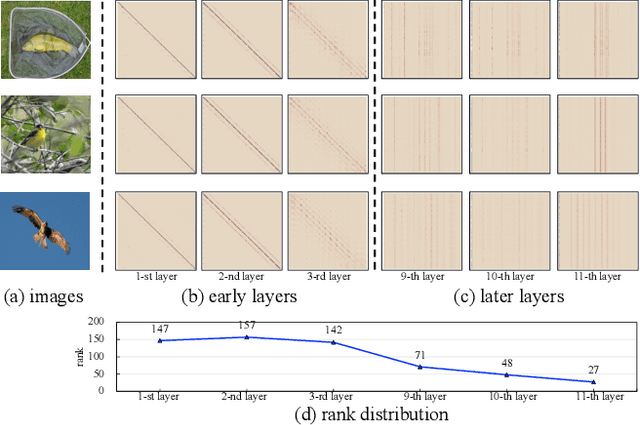
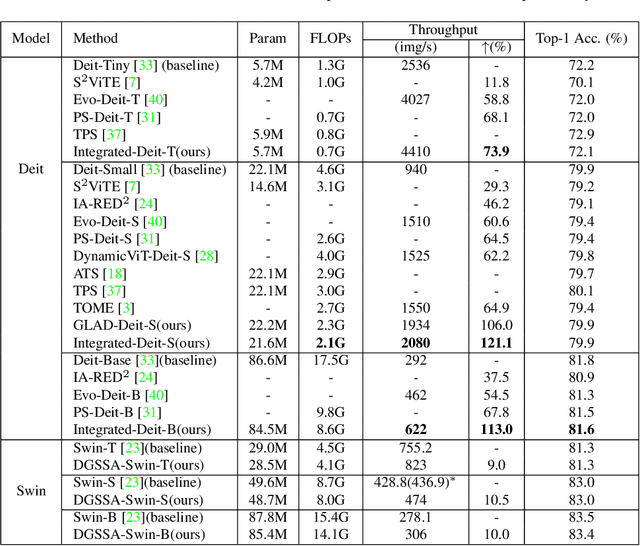
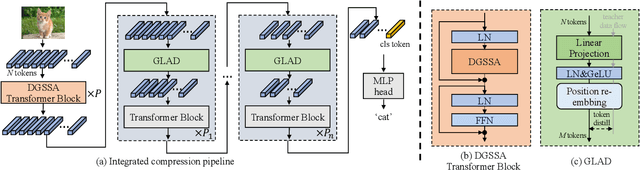
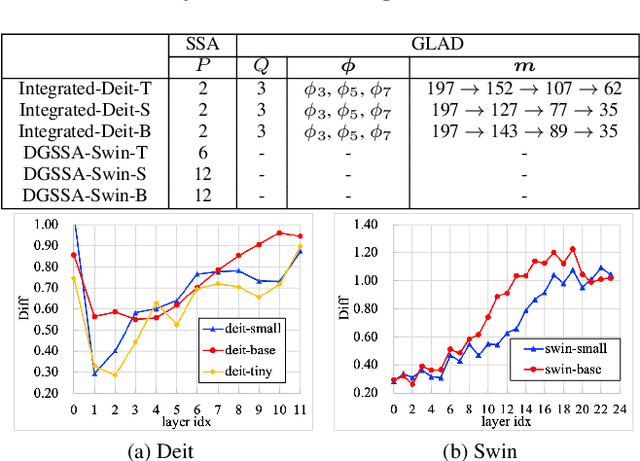
Recently, Vision Transformers (ViTs) have attracted a lot of attention in the field of computer vision. Generally, the powerful representative capacity of ViTs mainly benefits from the self-attention mechanism, which has a high computation complexity. To accelerate ViTs, we propose an integrated compression pipeline based on observed heterogeneous attention patterns across layers. On one hand, different images share more similar attention patterns in early layers than later layers, indicating that the dynamic query-by-key self-attention matrix may be replaced with a static self-attention matrix in early layers. Then, we propose a dynamic-guided static self-attention (DGSSA) method where the matrix inherits self-attention information from the replaced dynamic self-attention to effectively improve the feature representation ability of ViTs. On the other hand, the attention maps have more low-rank patterns, which reflect token redundancy, in later layers than early layers. In a view of linear dimension reduction, we further propose a method of global aggregation pyramid (GLAD) to reduce the number of tokens in later layers of ViTs, such as Deit. Experimentally, the integrated compression pipeline of DGSSA and GLAD can accelerate up to 121% run-time throughput compared with DeiT, which surpasses all SOTA approaches.
Group Pose: A Simple Baseline for End-to-End Multi-person Pose Estimation
Aug 14, 2023In this paper, we study the problem of end-to-end multi-person pose estimation. State-of-the-art solutions adopt the DETR-like framework, and mainly develop the complex decoder, e.g., regarding pose estimation as keypoint box detection and combining with human detection in ED-Pose, hierarchically predicting with pose decoder and joint (keypoint) decoder in PETR. We present a simple yet effective transformer approach, named Group Pose. We simply regard $K$-keypoint pose estimation as predicting a set of $N\times K$ keypoint positions, each from a keypoint query, as well as representing each pose with an instance query for scoring $N$ pose predictions. Motivated by the intuition that the interaction, among across-instance queries of different types, is not directly helpful, we make a simple modification to decoder self-attention. We replace single self-attention over all the $N\times(K+1)$ queries with two subsequent group self-attentions: (i) $N$ within-instance self-attention, with each over $K$ keypoint queries and one instance query, and (ii) $(K+1)$ same-type across-instance self-attention, each over $N$ queries of the same type. The resulting decoder removes the interaction among across-instance type-different queries, easing the optimization and thus improving the performance. Experimental results on MS COCO and CrowdPose show that our approach without human box supervision is superior to previous methods with complex decoders, and even is slightly better than ED-Pose that uses human box supervision. $\href{https://github.com/Michel-liu/GroupPose-Paddle}{\rm Paddle}$ and $\href{https://github.com/Michel-liu/GroupPose}{\rm PyTorch}$ code are available.
MataDoc: Margin and Text Aware Document Dewarping for Arbitrary Boundary
Jul 24, 2023Document dewarping from a distorted camera-captured image is of great value for OCR and document understanding. The document boundary plays an important role which is more evident than the inner region in document dewarping. Current learning-based methods mainly focus on complete boundary cases, leading to poor document correction performance of documents with incomplete boundaries. In contrast to these methods, this paper proposes MataDoc, the first method focusing on arbitrary boundary document dewarping with margin and text aware regularizations. Specifically, we design the margin regularization by explicitly considering background consistency to enhance boundary perception. Moreover, we introduce word position consistency to keep text lines straight in rectified document images. To produce a comprehensive evaluation of MataDoc, we propose a novel benchmark ArbDoc, mainly consisting of document images with arbitrary boundaries in four typical scenarios. Extensive experiments confirm the superiority of MataDoc with consideration for the incomplete boundary on ArbDoc and also demonstrate the effectiveness of the proposed method on DocUNet, DIR300, and WarpDoc datasets.