 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboGPU: Accelerating GPU Collision Detection for Robotics
Mar 02, 2026Autonomous robots are increasingly prevalent in our society, emerging in medical care, transportation vehicles, and home assistance. These robots rely on motion planning and collision detection to identify a sequence of movements allowing them to navigate to an end goal without colliding with the surrounding environment. While many specialized accelerators have been proposed to meet the real-time requirements of robotics planning tasks, they often lack the flexibility to adapt to the rapidly changing landscape of robotics and support future advancements. However, GPUs are well-positioned for robotics and we find that they can also tackle collision detection algorithms with enhancements to existing ray tracing accelerator (RTA) units. Unlike intersection tests in ray tracing, collision queries in robotics require control flow mechanisms to avoid unnecessary computations in each query. In this work, we explore and compare different architectural modifications to address the gaps of existing GPU RTAs. Our proposed RoboGPU architecture introduces a RoboCore that computes collision queries 3.1$\times$ faster than RTA implementations and 14.8$\times$ faster than a CUDA baseline. RoboCore is also useful for other robotics tasks, achieving 3.6$\times$ speedup on a state-of-the-art neural motion planner and 1.1$\times$ speedup on Monte Carlo Localization compared to a baseline GPU. RoboGPU matches the performance of dedicated hardware accelerators while being able to adapt to evolving motion planning algorithms and support classical algorithms.
Layered Rendering Diffusion Model for Zero-Shot Guided Image Synthesis
Nov 30, 2023This paper introduces innovative solutions to enhance spatial controllability in diffusion models reliant on text queries. We present two key innovations: Vision Guidance and the Layered Rendering Diffusion (LRDiff) framework. Vision Guidance, a spatial layout condition, acts as a clue in the perturbed distribution, greatly narrowing down the search space, to focus on the image sampling process adhering to the spatial layout condition. The LRDiff framework constructs an image-rendering process with multiple layers, each of which applies the vision guidance to instructively estimate the denoising direction for a single object. Such a layered rendering strategy effectively prevents issues like unintended conceptual blending or mismatches, while allowing for more coherent and contextually accurate image synthesis. The proposed method provides a more efficient and accurate means of synthesising images that align with specific spatial and contextual requirements. We demonstrate through our experiments that our method provides better results than existing techniques both quantitatively and qualitatively. We apply our method to three practical applications: bounding box-to-image, semantic mask-to-image and image editing.
PatFig: Generating Short and Long Captions for Patent Figures
Sep 15, 2023


This paper introduces Qatent PatFig, a novel large-scale patent figure dataset comprising 30,000+ patent figures from over 11,000 European patent applications. For each figure, this dataset provides short and long captions, reference numerals, their corresponding terms, and the minimal claim set that describes the interactions between the components of the image. To assess the usability of the dataset, we finetune an LVLM model on Qatent PatFig to generate short and long descriptions, and we investigate the effects of incorporating various text-based cues at the prediction stage of the patent figure captioning process.
UFO: Unified Feature Optimization
Jul 21, 2022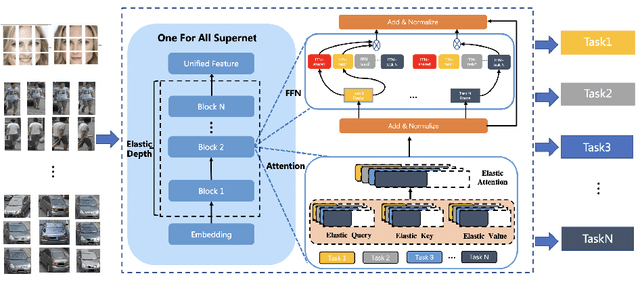
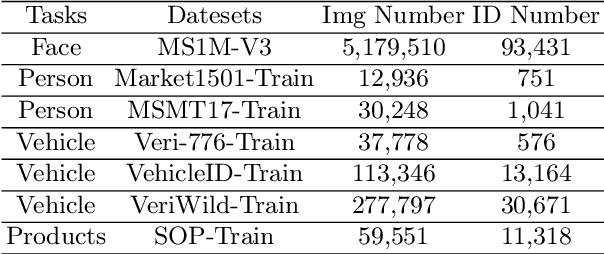
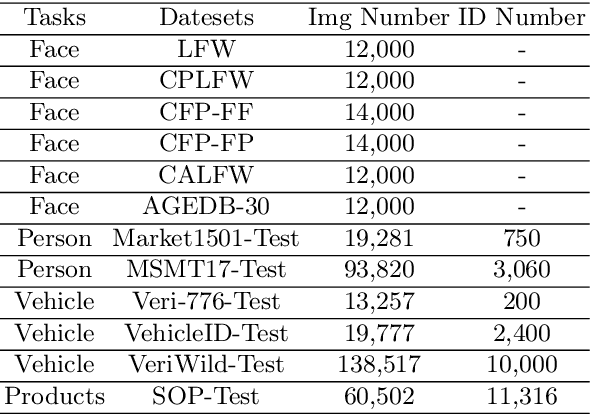
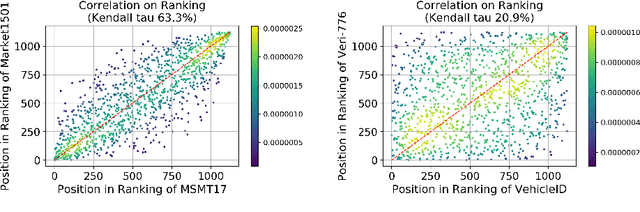
This paper proposes a novel Unified Feature Optimization (UFO) paradigm for training and deploying deep models under real-world and large-scale scenarios, which requires a collection of multiple AI functions. UFO aims to benefit each single task with a large-scale pretraining on all tasks. Compared with the well known foundation model, UFO has two different points of emphasis, i.e., relatively smaller model size and NO adaptation cost: 1) UFO squeezes a wide range of tasks into a moderate-sized unified model in a multi-task learning manner and further trims the model size when transferred to down-stream tasks. 2) UFO does not emphasize transfer to novel tasks. Instead, it aims to make the trimmed model dedicated for one or more already-seen task. With these two characteristics, UFO provides great convenience for flexible deployment, while maintaining the benefits of large-scale pretraining. A key merit of UFO is that the trimming process not only reduces the model size and inference consumption, but also even improves the accuracy on certain tasks. Specifically, UFO considers the multi-task training and brings two-fold impact on the unified model: some closely related tasks have mutual benefits, while some tasks have conflicts against each other. UFO manages to reduce the conflicts and to preserve the mutual benefits through a novel Network Architecture Search (NAS) method. Experiments on a wide range of deep representation learning tasks (i.e., face recognition, person re-identification, vehicle re-identification and product retrieval) show that the model trimmed from UFO achieves higher accuracy than its single-task-trained counterpart and yet has smaller model size, validating the concept of UFO. Besides, UFO also supported the release of 17 billion parameters computer vision (CV) foundation model which is the largest CV model in the industry.