 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedXIAOHE: A Comprehensive Recipe for Building Medical MLLMs
Feb 16, 2026We present MedXIAOHE, a medical vision-language foundation model designed to advance general-purpose medical understanding and reasoning in real-world clinical applications. MedXIAOHE achieves state-of-the-art performance across diverse medical benchmarks and surpasses leading closed-source multimodal systems on multiple capabilities. To achieve this, we propose an entity-aware continual pretraining framework that organizes heterogeneous medical corpora to broaden knowledge coverage and reduce long-tail gaps (e.g., rare diseases). For medical expert-level reasoning and interaction, MedXIAOHE incorporates diverse medical reasoning patterns via reinforcement learning and tool-augmented agentic training, enabling multi-step diagnostic reasoning with verifiable decision traces. To improve reliability in real-world use, MedXIAOHE integrates user-preference rubrics, evidence-grounded reasoning, and low-hallucination long-form report generation, with improved adherence to medical instructions. We release this report to document our practical design choices, scaling insights, and evaluation framework, hoping to inspire further research.
Token Transforming: A Unified and Training-Free Token Compression Framework for Vision Transformer Acceleration
Jun 06, 2025Vision transformers have been widely explored in various vision tasks. Due to heavy computational cost, much interest has aroused for compressing vision transformer dynamically in the aspect of tokens. Current methods mainly pay attention to token pruning or merging to reduce token numbers, in which tokens are compressed exclusively, causing great information loss and therefore post-training is inevitably required to recover the performance. In this paper, we rethink token reduction and unify the process as an explicit form of token matrix transformation, in which all existing methods are constructing special forms of matrices within the framework. Furthermore, we propose a many-to-many Token Transforming framework that serves as a generalization of all existing methods and reserves the most information, even enabling training-free acceleration. We conduct extensive experiments to validate our framework. Specifically, we reduce 40% FLOPs and accelerate DeiT-S by $\times$1.5 with marginal 0.1% accuracy drop. Furthermore, we extend the method to dense prediction tasks including segmentation, object detection, depth estimation, and language model generation. Results demonstrate that the proposed method consistently achieves substantial improvements, offering a better computation-performance trade-off, impressive budget reduction and inference acceleration.
Accelerating Vision Transformers Based on Heterogeneous Attention Patterns
Oct 11, 2023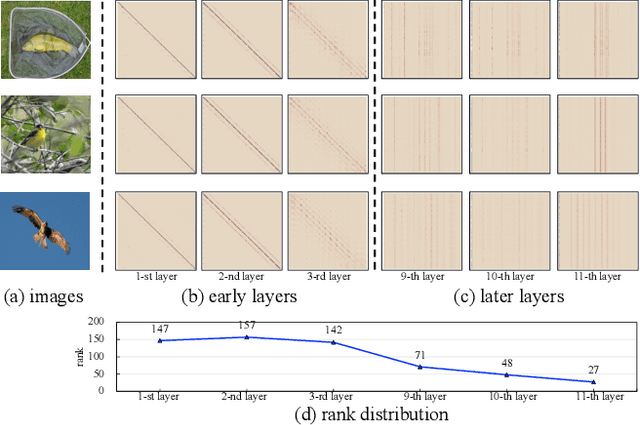
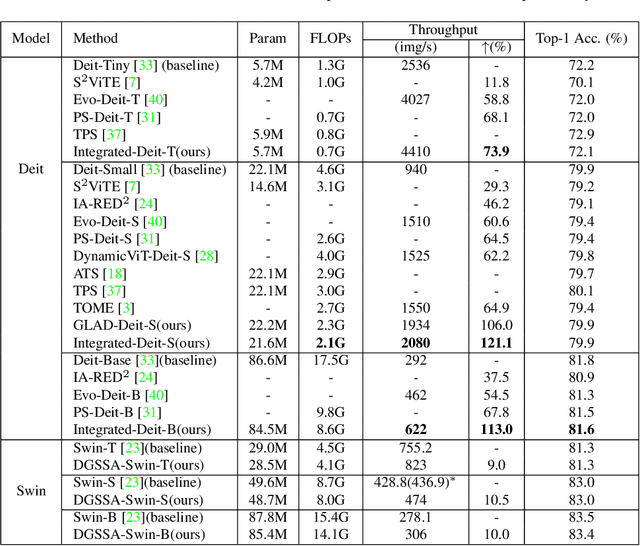
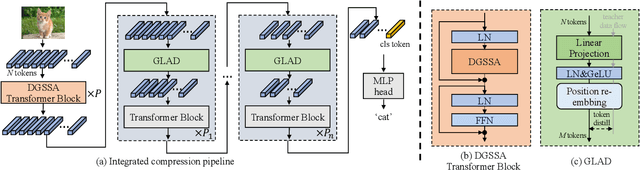
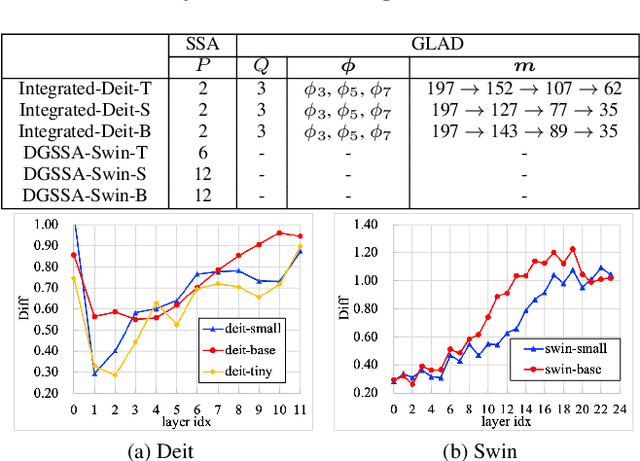
Recently, Vision Transformers (ViTs) have attracted a lot of attention in the field of computer vision. Generally, the powerful representative capacity of ViTs mainly benefits from the self-attention mechanism, which has a high computation complexity. To accelerate ViTs, we propose an integrated compression pipeline based on observed heterogeneous attention patterns across layers. On one hand, different images share more similar attention patterns in early layers than later layers, indicating that the dynamic query-by-key self-attention matrix may be replaced with a static self-attention matrix in early layers. Then, we propose a dynamic-guided static self-attention (DGSSA) method where the matrix inherits self-attention information from the replaced dynamic self-attention to effectively improve the feature representation ability of ViTs. On the other hand, the attention maps have more low-rank patterns, which reflect token redundancy, in later layers than early layers. In a view of linear dimension reduction, we further propose a method of global aggregation pyramid (GLAD) to reduce the number of tokens in later layers of ViTs, such as Deit. Experimentally, the integrated compression pipeline of DGSSA and GLAD can accelerate up to 121% run-time throughput compared with DeiT, which surpasses all SOTA approaches.
UFO: Unified Feature Optimization
Jul 21, 2022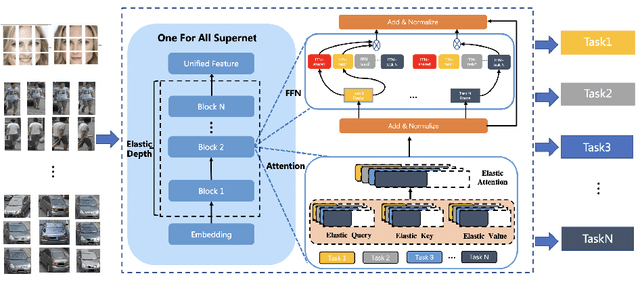
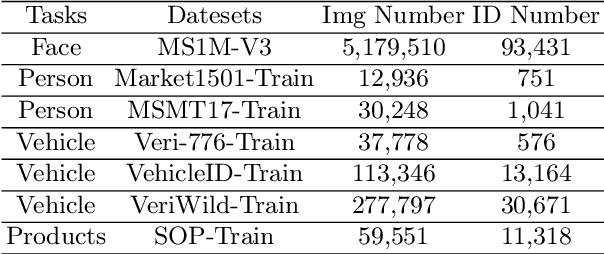
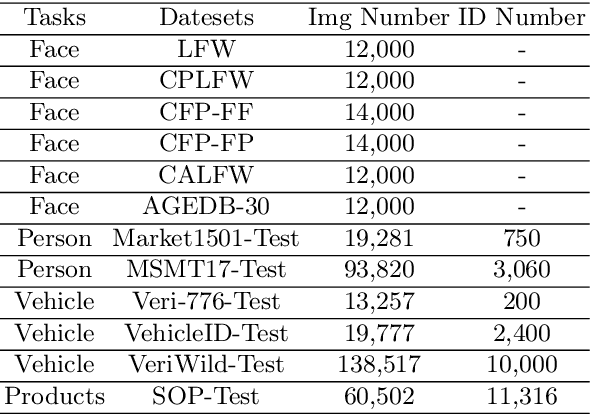
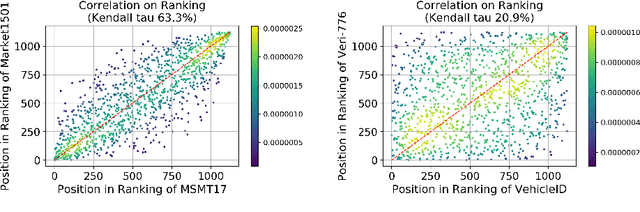
This paper proposes a novel Unified Feature Optimization (UFO) paradigm for training and deploying deep models under real-world and large-scale scenarios, which requires a collection of multiple AI functions. UFO aims to benefit each single task with a large-scale pretraining on all tasks. Compared with the well known foundation model, UFO has two different points of emphasis, i.e., relatively smaller model size and NO adaptation cost: 1) UFO squeezes a wide range of tasks into a moderate-sized unified model in a multi-task learning manner and further trims the model size when transferred to down-stream tasks. 2) UFO does not emphasize transfer to novel tasks. Instead, it aims to make the trimmed model dedicated for one or more already-seen task. With these two characteristics, UFO provides great convenience for flexible deployment, while maintaining the benefits of large-scale pretraining. A key merit of UFO is that the trimming process not only reduces the model size and inference consumption, but also even improves the accuracy on certain tasks. Specifically, UFO considers the multi-task training and brings two-fold impact on the unified model: some closely related tasks have mutual benefits, while some tasks have conflicts against each other. UFO manages to reduce the conflicts and to preserve the mutual benefits through a novel Network Architecture Search (NAS) method. Experiments on a wide range of deep representation learning tasks (i.e., face recognition, person re-identification, vehicle re-identification and product retrieval) show that the model trimmed from UFO achieves higher accuracy than its single-task-trained counterpart and yet has smaller model size, validating the concept of UFO. Besides, UFO also supported the release of 17 billion parameters computer vision (CV) foundation model which is the largest CV model in the industry.
Towards Accurate Scene Text Recognition with Semantic Reasoning Networks
Mar 27, 2020
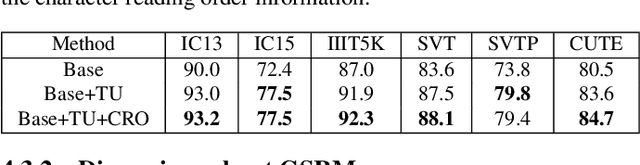
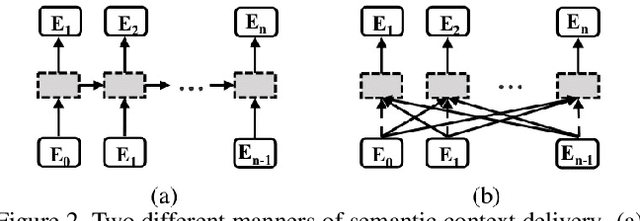
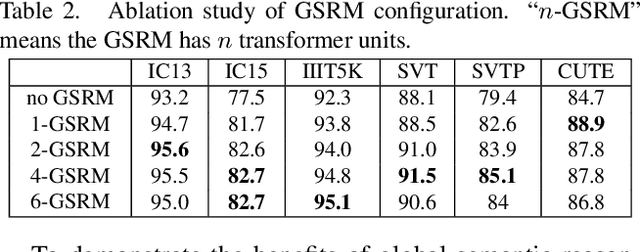
Scene text image contains two levels of contents: visual texture and semantic information. Although the previous scene text recognition methods have made great progress over the past few years, the research on mining semantic information to assist text recognition attracts less attention, only RNN-like structures are explored to implicitly model semantic information. However, we observe that RNN based methods have some obvious shortcomings, such as time-dependent decoding manner and one-way serial transmission of semantic context, which greatly limit the help of semantic information and the computation efficiency. To mitigate these limitations, we propose a novel end-to-end trainable framework named semantic reasoning network (SRN) for accurate scene text recognition, where a global semantic reasoning module (GSRM) is introduced to capture global semantic context through multi-way parallel transmission. The state-of-the-art results on 7 public benchmarks, including regular text, irregular text and non-Latin long text, verify the effectiveness and robustness of the proposed method. In addition, the speed of SRN has significant advantages over the RNN based methods, demonstrating its value in practical use.