 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO: Unified Feature Optimization
Jul 21, 2022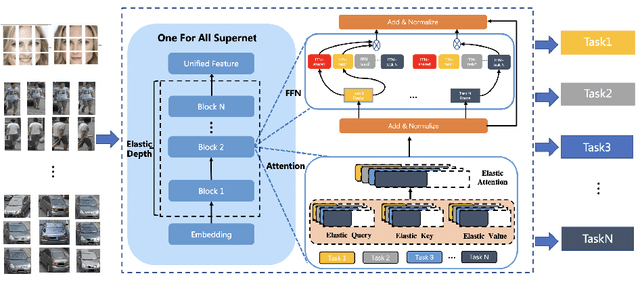
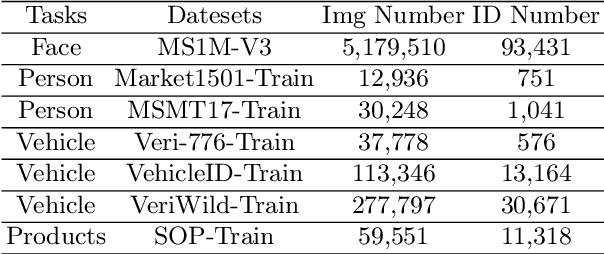
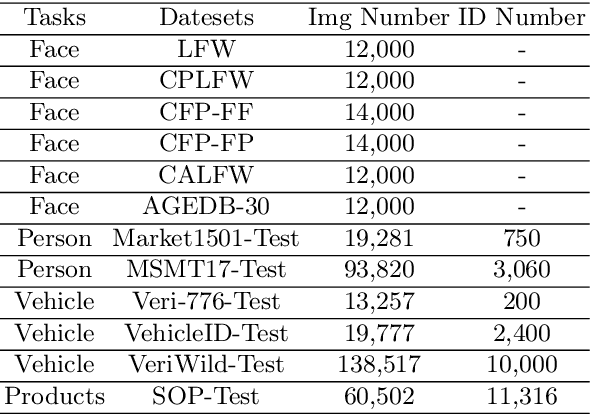
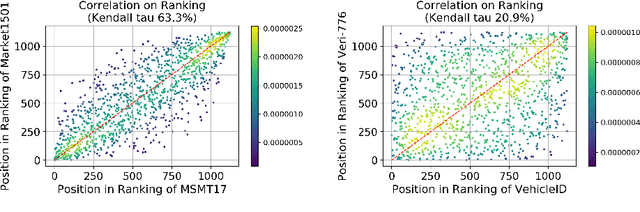
This paper proposes a novel Unified Feature Optimization (UFO) paradigm for training and deploying deep models under real-world and large-scale scenarios, which requires a collection of multiple AI functions. UFO aims to benefit each single task with a large-scale pretraining on all tasks. Compared with the well known foundation model, UFO has two different points of emphasis, i.e., relatively smaller model size and NO adaptation cost: 1) UFO squeezes a wide range of tasks into a moderate-sized unified model in a multi-task learning manner and further trims the model size when transferred to down-stream tasks. 2) UFO does not emphasize transfer to novel tasks. Instead, it aims to make the trimmed model dedicated for one or more already-seen task. With these two characteristics, UFO provides great convenience for flexible deployment, while maintaining the benefits of large-scale pretraining. A key merit of UFO is that the trimming process not only reduces the model size and inference consumption, but also even improves the accuracy on certain tasks. Specifically, UFO considers the multi-task training and brings two-fold impact on the unified model: some closely related tasks have mutual benefits, while some tasks have conflicts against each other. UFO manages to reduce the conflicts and to preserve the mutual benefits through a novel Network Architecture Search (NAS) method. Experiments on a wide range of deep representation learning tasks (i.e., face recognition, person re-identification, vehicle re-identification and product retrieval) show that the model trimmed from UFO achieves higher accuracy than its single-task-trained counterpart and yet has smaller model size, validating the concept of UFO. Besides, UFO also supported the release of 17 billion parameters computer vision (CV) foundation model which is the largest CV model in the industry.
Dynamic Class Queue for Large Scale Face Recognition In the Wild
May 24, 2021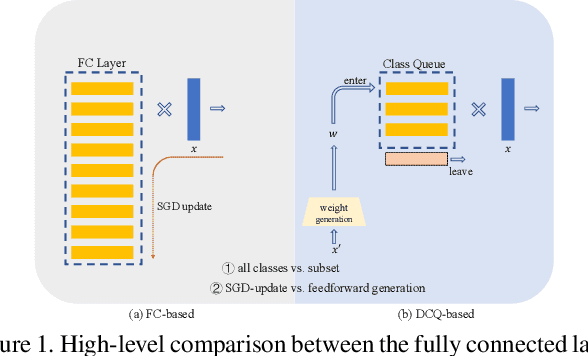

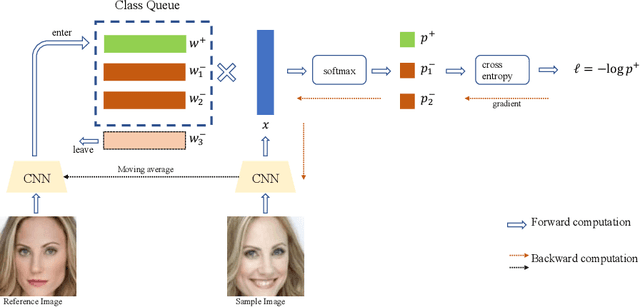
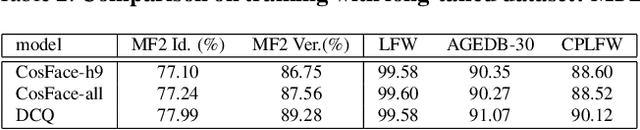
Learning discriminative representation using large-scale face datasets in the wild is crucial for real-world applications, yet it remains challenging. The difficulties lie in many aspects and this work focus on computing resource constraint and long-tailed class distribution. Recently, classification-based representation learning with deep neural networks and well-designed losses have demonstrated good recognition performance. However, the computing and memory cost linearly scales up to the number of identities (classes) in the training set, and the learning process suffers from unbalanced classes. In this work, we propose a dynamic class queue (DCQ) to tackle these two problems. Specifically, for each iteration during training, a subset of classes for recognition are dynamically selected and their class weights are dynamically generated on-the-fly which are stored in a queue. Since only a subset of classes is selected for each iteration, the computing requirement is reduced. By using a single server without model parallel, we empirically verify in large-scale datasets that 10% of classes are sufficient to achieve similar performance as using all classes. Moreover, the class weights are dynamically generated in a few-shot manner and therefore suitable for tail classes with only a few instances. We show clear improvement over a strong baseline in the largest public dataset Megaface Challenge2 (MF2) which has 672K identities and over 88% of them have less than 10 instances. Code is available at https://github.com/bilylee/DCQ
Learning Global Structure Consistency for Robust Object Tracking
Aug 26, 2020
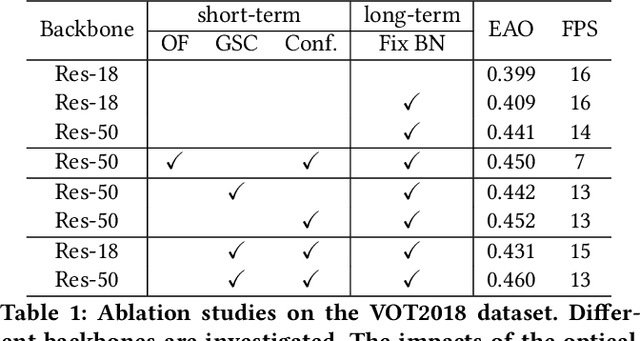
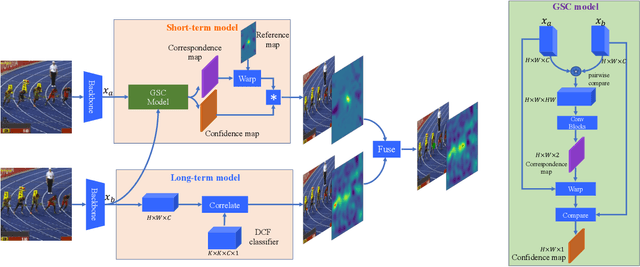
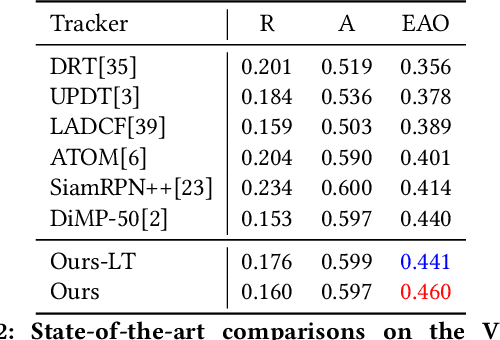
Fast appearance variations and the distractions of similar objects are two of the most challenging problems in visual object tracking. Unlike many existing trackers that focus on modeling only the target, in this work, we consider the \emph{transient variations of the whole scene}. The key insight is that the object correspondence and spatial layout of the whole scene are consistent (i.e., global structure consistency) in consecutive frames which helps to disambiguate the target from distractors. Moreover, modeling transient variations enables to localize the target under fast variations. Specifically, we propose an effective and efficient short-term model that learns to exploit the global structure consistency in a short time and thus can handle fast variations and distractors. Since short-term modeling falls short of handling occlusion and out of the views, we adopt the long-short term paradigm and use a long-term model that corrects the short-term model when it drifts away from the target or the target is not present. These two components are carefully combined to achieve the balance of stability and plasticity during tracking. We empirically verify that the proposed tracker can tackle the two challenging scenarios and validate it on large scale benchmarks. Remarkably, our tracker improves state-of-the-art-performance on VOT2018 from 0.440 to 0.460, GOT-10k from 0.611 to 0.640, and NFS from 0.619 to 0.629.
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019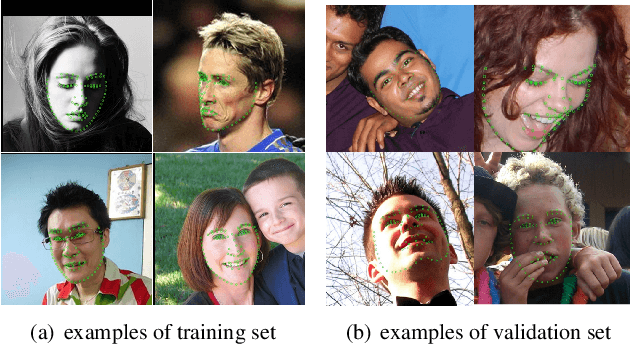
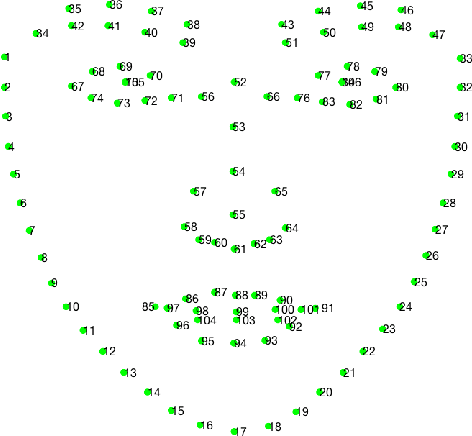

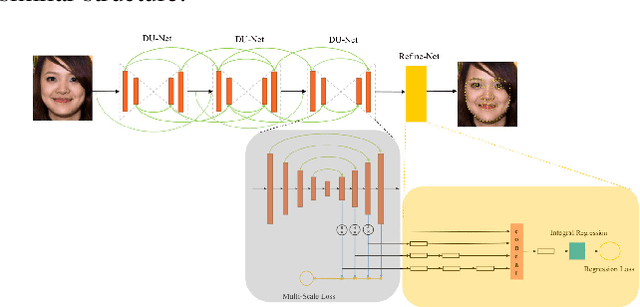
Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.
Learning to Update for Object Tracking
Jun 19, 2018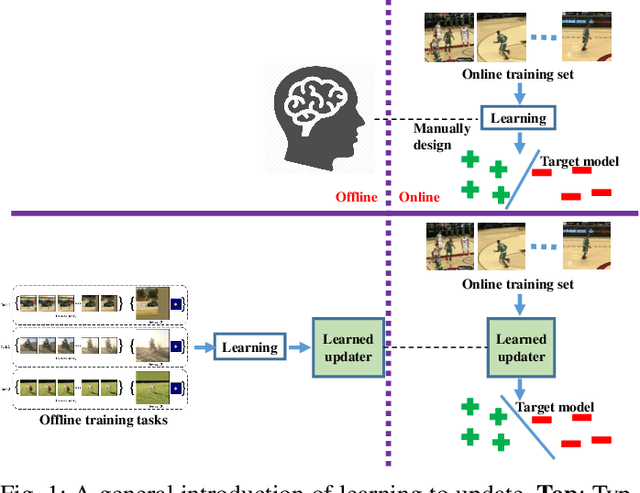
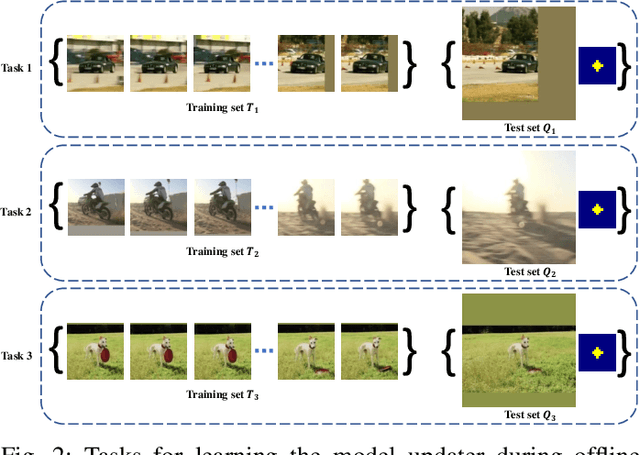
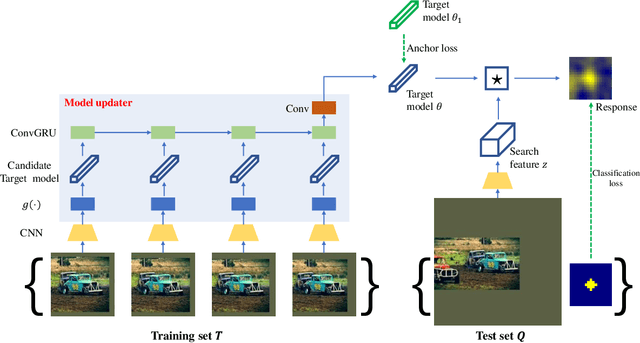

Model update lies at the heart of object tracking.Generally, model update is formulated as an online learning problem where a target model is learned over the online training dataset. Our key innovation is to \emph{learn the online learning algorithm itself using large number of offline videos}, i.e., \emph{learning to update}. The learned updater takes as input the online training dataset and outputs an updated target model. As a first attempt, we design the learned updater based on recurrent neural networks (RNNs) and demonstrate its application in a template-based tracker and a correlation filter-based tracker. Our learned updater consistently improves the base trackers and runs faster than realtime on GPU while requiring small memory footprint during testing. Experiments on standard benchmarks demonstrate that our learned updater outperforms commonly used update baselines including the efficient exponential moving average (EMA)-based update and the well-designed stochastic gradient descent (SGD)-based update. Equipped with our learned updater, the template-based tracker achieves state-of-the-art performance among realtime trackers on GPU.