 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Before Reasoning: Two-Stage Reinforcement Learning for Visual Reasoning in Vision-Language Models
Sep 16, 2025Reinforcement learning (RL) has proven highly effective in eliciting the reasoning capabilities of large language models (LLMs). Inspired by this success, recent studies have explored applying similar techniques to vision-language models (VLMs), aiming to enhance their reasoning performance. However, directly transplanting RL methods from LLMs to VLMs is suboptimal, as the tasks faced by VLMs are inherently more complex. Specifically, VLMs must first accurately perceive and understand visual inputs before reasoning can be effectively performed. To address this challenge, we propose a two-stage reinforcement learning framework designed to jointly enhance both the perceptual and reasoning capabilities of VLMs. To mitigate the vanishing advantage issue commonly observed in RL training, we first perform dataset-level sampling to selectively strengthen specific capabilities using distinct data sources. During training, the first stage focuses on improving the model's visual perception through coarse- and fine-grained visual understanding, while the second stage targets the enhancement of reasoning abilities. After the proposed two-stage reinforcement learning process, we obtain PeBR-R1, a vision-language model with significantly enhanced perceptual and reasoning capabilities. Experimental results on seven benchmark datasets demonstrate the effectiveness of our approach and validate the superior performance of PeBR-R1 across diverse visual reasoning tasks.
OVLW-DETR: Open-Vocabulary Light-Weighted Detection Transformer
Jul 15, 2024

Open-vocabulary object detection focusing on detecting novel categories guided by natural language. In this report, we propose Open-Vocabulary Light-Weighted Detection Transformer (OVLW-DETR), a deployment friendly open-vocabulary detector with strong performance and low latency. Building upon OVLW-DETR, we provide an end-to-end training recipe that transferring knowledge from vision-language model (VLM) to object detector with simple alignment. We align detector with the text encoder from VLM by replacing the fixed classification layer weights in detector with the class-name embeddings extracted from the text encoder. Without additional fusing module, OVLW-DETR is flexible and deployment friendly, making it easier to implement and modulate. improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time open-vocabulary detectors on standard Zero-Shot LVIS benchmark. Source code and pre-trained models are available at [https://github.com/Atten4Vis/LW-DETR].
Accelerating Vision Transformers Based on Heterogeneous Attention Patterns
Oct 11, 2023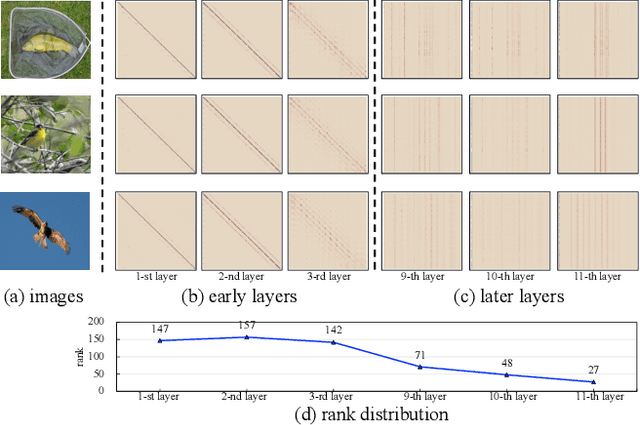
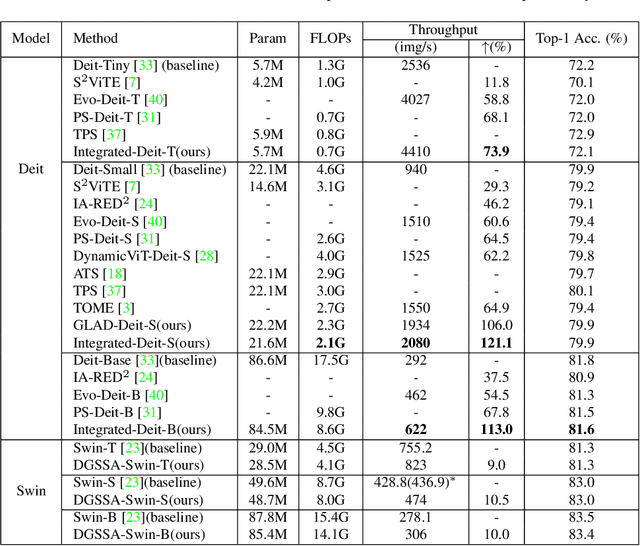
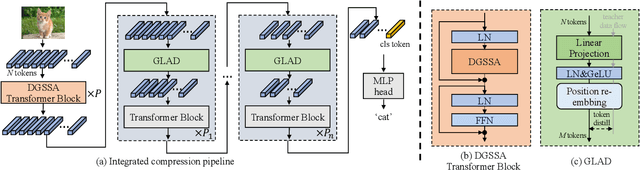
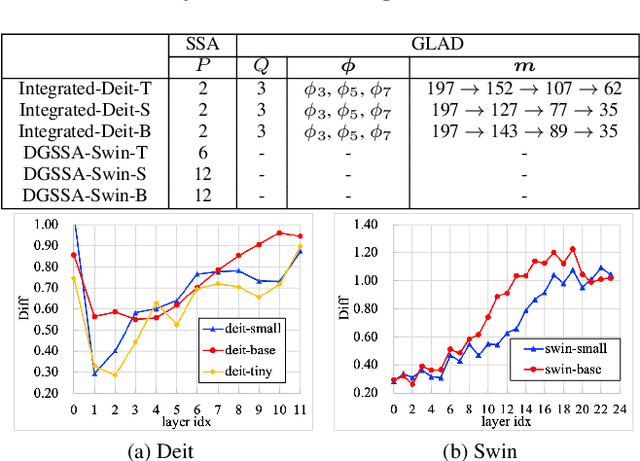
Recently, Vision Transformers (ViTs) have attracted a lot of attention in the field of computer vision. Generally, the powerful representative capacity of ViTs mainly benefits from the self-attention mechanism, which has a high computation complexity. To accelerate ViTs, we propose an integrated compression pipeline based on observed heterogeneous attention patterns across layers. On one hand, different images share more similar attention patterns in early layers than later layers, indicating that the dynamic query-by-key self-attention matrix may be replaced with a static self-attention matrix in early layers. Then, we propose a dynamic-guided static self-attention (DGSSA) method where the matrix inherits self-attention information from the replaced dynamic self-attention to effectively improve the feature representation ability of ViTs. On the other hand, the attention maps have more low-rank patterns, which reflect token redundancy, in later layers than early layers. In a view of linear dimension reduction, we further propose a method of global aggregation pyramid (GLAD) to reduce the number of tokens in later layers of ViTs, such as Deit. Experimentally, the integrated compression pipeline of DGSSA and GLAD can accelerate up to 121% run-time throughput compared with DeiT, which surpasses all SOTA approaches.
Open-TransMind: A New Baseline and Benchmark for 1st Foundation Model Challenge of Intelligent Transportation
Apr 12, 2023



With the continuous improvement of computing power and deep learning algorithms in recent years, the foundation model has grown in popularity. Because of its powerful capabilities and excellent performance, this technology is being adopted and applied by an increasing number of industries. In the intelligent transportation industry, artificial intelligence faces the following typical challenges: few shots, poor generalization, and a lack of multi-modal techniques. Foundation model technology can significantly alleviate the aforementioned issues. To address these, we designed the 1st Foundation Model Challenge, with the goal of increasing the popularity of foundation model technology in traffic scenarios and promoting the rapid development of the intelligent transportation industry. The challenge is divided into two tracks: all-in-one and cross-modal image retrieval. Furthermore, we provide a new baseline and benchmark for the two tracks, called Open-TransMind. According to our knowledge, Open-TransMind is the first open-source transportation foundation model with multi-task and multi-modal capabilities. Simultaneously, Open-TransMind can achieve state-of-the-art performance on detection, classification, and segmentation datasets of traffic scenarios. Our source code is available at https://github.com/Traffic-X/Open-TransMind.
A Unified Continual Learning Framework with General Parameter-Efficient Tuning
Mar 17, 2023



The "pre-training $\rightarrow$ downstream adaptation" presents both new opportunities and challenges for Continual Learning (CL). Although the recent state-of-the-art in CL is achieved through Parameter-Efficient-Tuning (PET) adaptation paradigm, only prompt has been explored, limiting its application to Transformers only. In this paper, we position prompting as one instantiation of PET, and propose a unified CL framework with general PET, dubbed as Learning-Accumulation-Ensemble (LAE). PET, e.g., using Adapter, LoRA, or Prefix, can adapt a pre-trained model to downstream tasks with fewer parameters and resources. Given a PET method, our LAE framework incorporates it for CL with three novel designs. 1) Learning: the pre-trained model adapts to the new task by tuning an online PET module, along with our adaptation speed calibration to align different PET modules, 2) Accumulation: the task-specific knowledge learned by the online PET module is accumulated into an offline PET module through momentum update, 3) Ensemble: During inference, we respectively construct two experts with online/offline PET modules (which are favored by the novel/historical tasks) for prediction ensemble. We show that LAE is compatible with a battery of PET methods and gains strong CL capability. For example, LAE with Adaptor PET surpasses the prior state-of-the-art by 1.3% and 3.6% in last-incremental accuracy on CIFAR100 and ImageNet-R datasets, respectively.
UFO: Unified Feature Optimization
Jul 21, 2022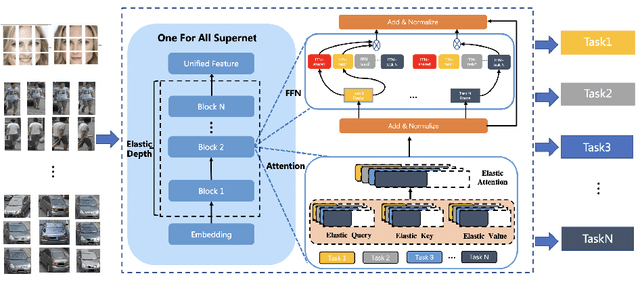
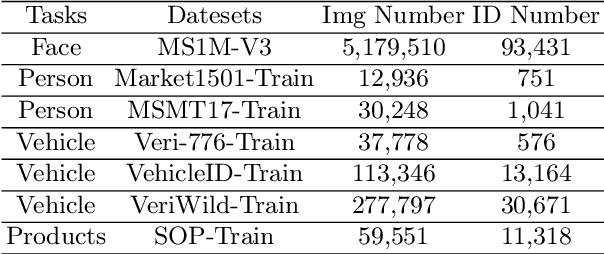
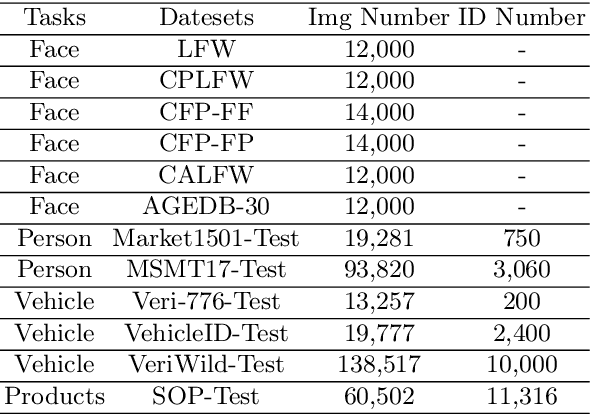
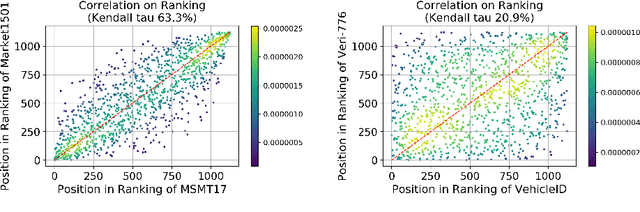
This paper proposes a novel Unified Feature Optimization (UFO) paradigm for training and deploying deep models under real-world and large-scale scenarios, which requires a collection of multiple AI functions. UFO aims to benefit each single task with a large-scale pretraining on all tasks. Compared with the well known foundation model, UFO has two different points of emphasis, i.e., relatively smaller model size and NO adaptation cost: 1) UFO squeezes a wide range of tasks into a moderate-sized unified model in a multi-task learning manner and further trims the model size when transferred to down-stream tasks. 2) UFO does not emphasize transfer to novel tasks. Instead, it aims to make the trimmed model dedicated for one or more already-seen task. With these two characteristics, UFO provides great convenience for flexible deployment, while maintaining the benefits of large-scale pretraining. A key merit of UFO is that the trimming process not only reduces the model size and inference consumption, but also even improves the accuracy on certain tasks. Specifically, UFO considers the multi-task training and brings two-fold impact on the unified model: some closely related tasks have mutual benefits, while some tasks have conflicts against each other. UFO manages to reduce the conflicts and to preserve the mutual benefits through a novel Network Architecture Search (NAS) method. Experiments on a wide range of deep representation learning tasks (i.e., face recognition, person re-identification, vehicle re-identification and product retrieval) show that the model trimmed from UFO achieves higher accuracy than its single-task-trained counterpart and yet has smaller model size, validating the concept of UFO. Besides, UFO also supported the release of 17 billion parameters computer vision (CV) foundation model which is the largest CV model in the industry.
An Information Theory-inspired Strategy for Automatic Network Pruning
Aug 19, 2021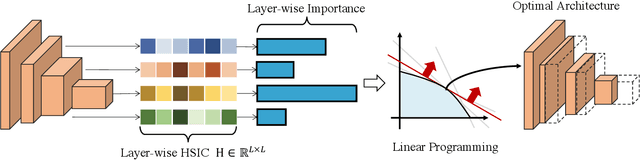
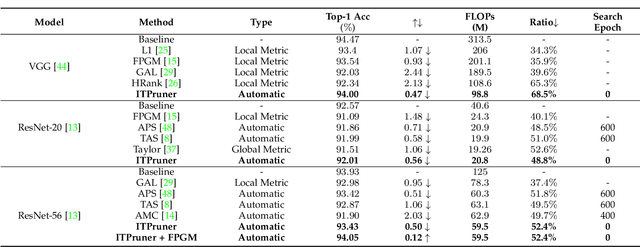
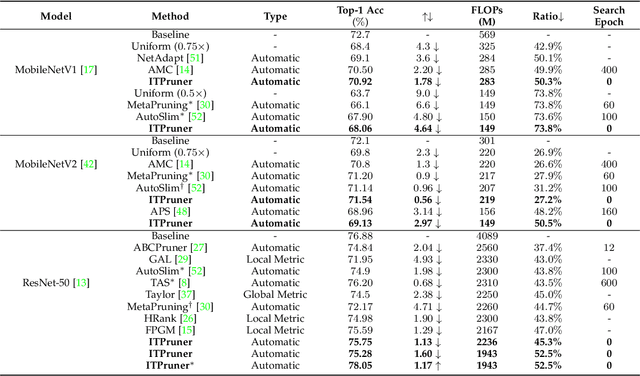
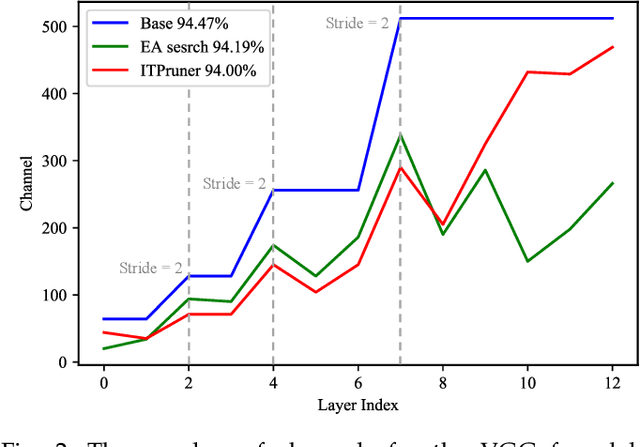
Despite superior performance on many computer vision tasks, deep convolution neural networks are well known to be compressed on devices that have resource constraints. Most existing network pruning methods require laborious human efforts and prohibitive computation resources, especially when the constraints are changed. This practically limits the application of model compression when the model needs to be deployed on a wide range of devices. Besides, existing methods are still challenged by the missing theoretical guidance. In this paper we propose an information theory-inspired strategy for automatic model compression. The principle behind our method is the information bottleneck theory, i.e., the hidden representation should compress information with each other. We thus introduce the normalized Hilbert-Schmidt Independence Criterion (nHSIC) on network activations as a stable and generalized indicator of layer importance. When a certain resource constraint is given, we integrate the HSIC indicator with the constraint to transform the architecture search problem into a linear programming problem with quadratic constraints. Such a problem is easily solved by a convex optimization method with a few seconds. We also provide a rigorous proof to reveal that optimizing the normalized HSIC simultaneously minimizes the mutual information between different layers. Without any search process, our method achieves better compression tradeoffs comparing to the state-of-the-art compression algorithms. For instance, with ResNet-50, we achieve a 45.3%-FLOPs reduction, with a 75.75 top-1 accuracy on ImageNet. Codes are avaliable at https://github.com/MAC-AutoML/ITPruner/tree/master.
Dynamic Class Queue for Large Scale Face Recognition In the Wild
May 24, 2021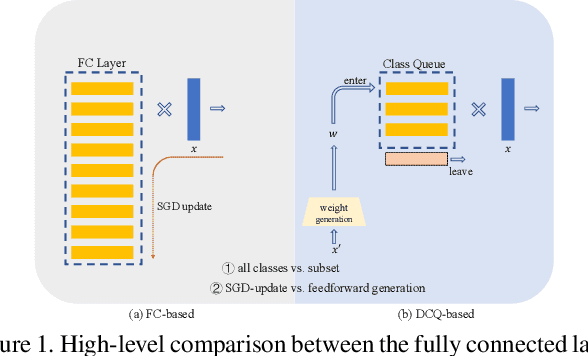

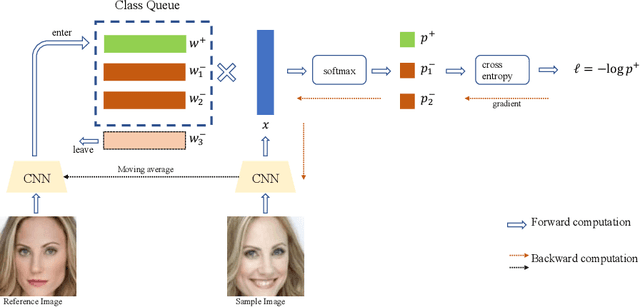
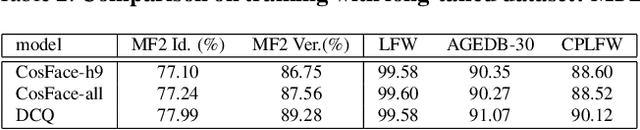
Learning discriminative representation using large-scale face datasets in the wild is crucial for real-world applications, yet it remains challenging. The difficulties lie in many aspects and this work focus on computing resource constraint and long-tailed class distribution. Recently, classification-based representation learning with deep neural networks and well-designed losses have demonstrated good recognition performance. However, the computing and memory cost linearly scales up to the number of identities (classes) in the training set, and the learning process suffers from unbalanced classes. In this work, we propose a dynamic class queue (DCQ) to tackle these two problems. Specifically, for each iteration during training, a subset of classes for recognition are dynamically selected and their class weights are dynamically generated on-the-fly which are stored in a queue. Since only a subset of classes is selected for each iteration, the computing requirement is reduced. By using a single server without model parallel, we empirically verify in large-scale datasets that 10% of classes are sufficient to achieve similar performance as using all classes. Moreover, the class weights are dynamically generated in a few-shot manner and therefore suitable for tail classes with only a few instances. We show clear improvement over a strong baseline in the largest public dataset Megaface Challenge2 (MF2) which has 672K identities and over 88% of them have less than 10 instances. Code is available at https://github.com/bilylee/DCQ
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020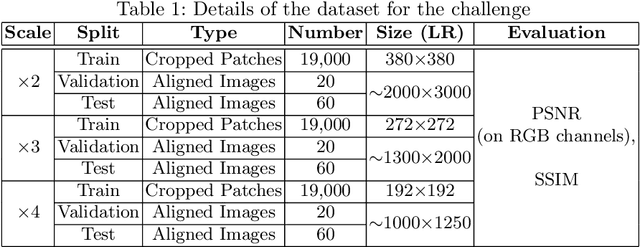
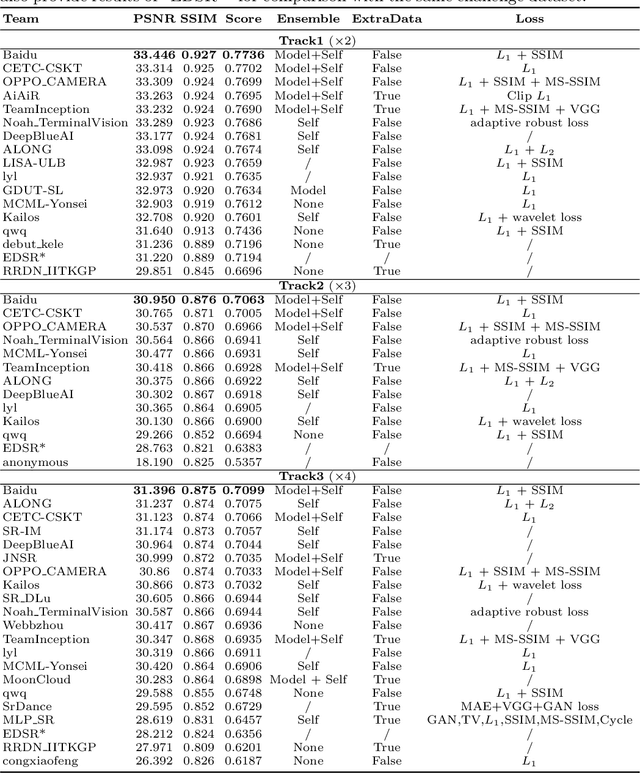
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
Real Image Super Resolution Via Heterogeneous Model using GP-NAS
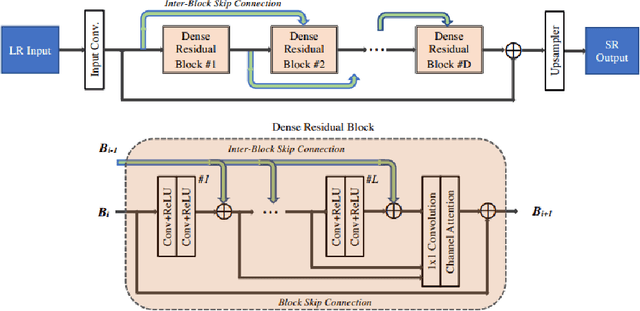
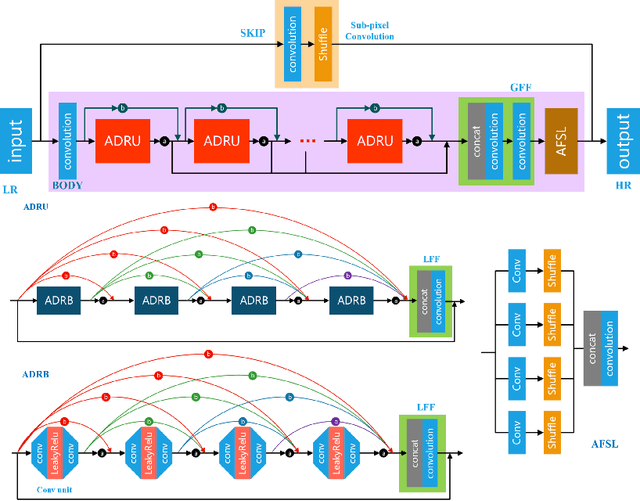
Sep 02, 2020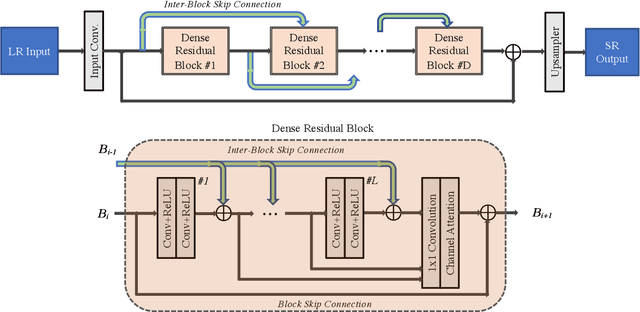

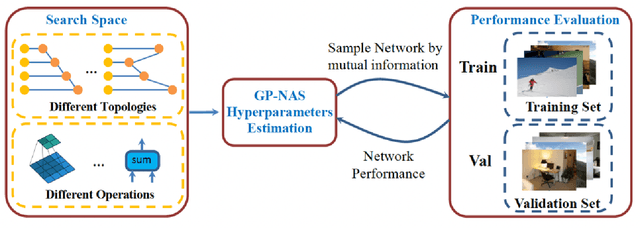
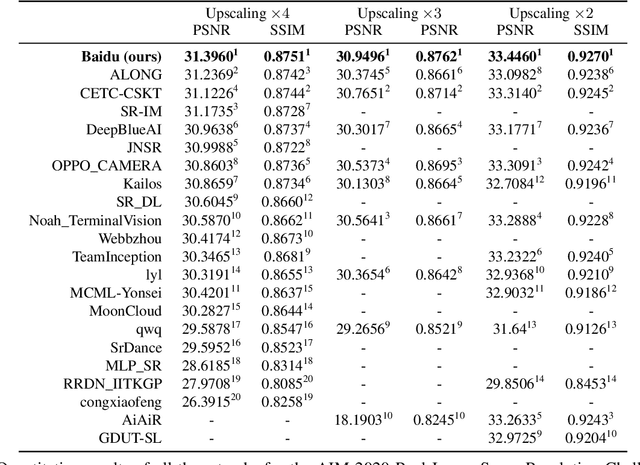
With advancement in deep neural network (DNN), recent state-of-the-art (SOTA) image superresolution (SR) methods have achieved impressive performance using deep residual network with dense skip connections. While these models perform well on benchmark dataset where low-resolution (LR) images are constructed from high-resolution (HR) references with known blur kernel, real image SR is more challenging when both images in the LR-HR pair are collected from real cameras. Based on existing dense residual networks, a Gaussian process based neural architecture search (GP-NAS) scheme is utilized to find candidate network architectures using a large search space by varying the number of dense residual blocks, the block size and the number of features. A suite of heterogeneous models with diverse network structure and hyperparameter are selected for model-ensemble to achieve outstanding performance in real image SR. The proposed method won the first place in all three tracks of the AIM 2020 Real Image Super-Resolution Challenge.