 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolybasic Speculative Decoding Through a Theoretical Perspective
Oct 30, 2025



Inference latency stands as a critical bottleneck in the large-scale deployment of Large Language Models (LLMs). Speculative decoding methods have recently shown promise in accelerating inference without compromising the output distribution. However, existing work typically relies on a dualistic draft-verify framework and lacks rigorous theoretical grounding. In this paper, we introduce a novel \emph{polybasic} speculative decoding framework, underpinned by a comprehensive theoretical analysis. Specifically, we prove a fundamental theorem that characterizes the optimal inference time for multi-model speculative decoding systems, shedding light on how to extend beyond the dualistic approach to a more general polybasic paradigm. Through our theoretical investigation of multi-model token generation, we expose and optimize the interplay between model capabilities, acceptance lengths, and overall computational cost. Our framework supports both standalone implementation and integration with existing speculative techniques, leading to accelerated performance in practice. Experimental results across multiple model families demonstrate that our approach yields speedup ratios ranging from $3.31\times$ to $4.01\times$ for LLaMA2-Chat 7B, up to $3.87 \times$ for LLaMA3-8B, up to $4.43 \times$ for Vicuna-7B and up to $3.85 \times$ for Qwen2-7B -- all while preserving the original output distribution. We release our theoretical proofs and implementation code to facilitate further investigation into polybasic speculative decoding.
AffineQuant: Affine Transformation Quantization for Large Language Models
Mar 19, 2024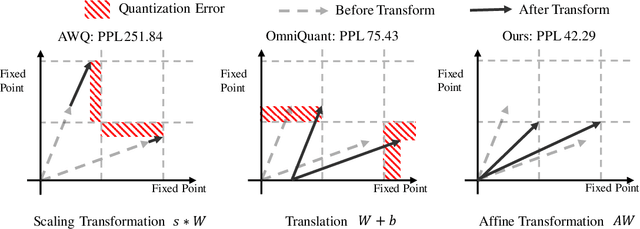
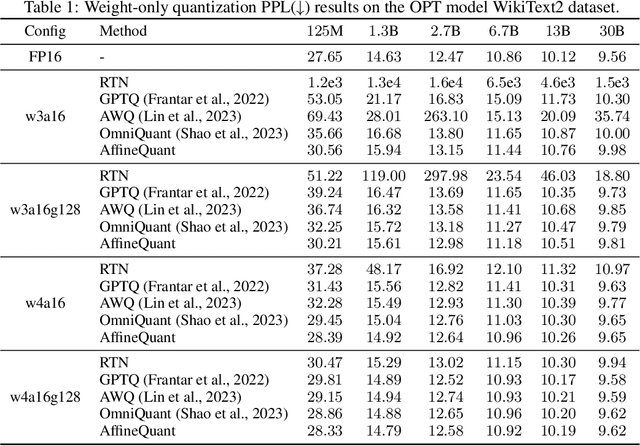
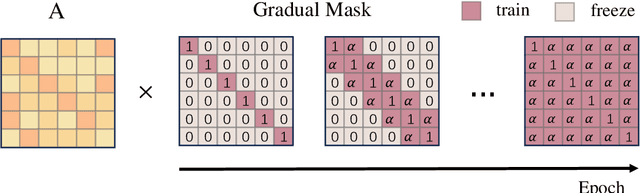
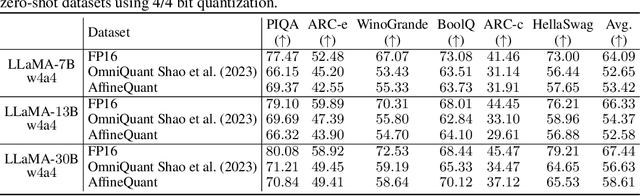
The significant resource requirements associated with Large-scale Language Models (LLMs) have generated considerable interest in the development of techniques aimed at compressing and accelerating neural networks. Among these techniques, Post-Training Quantization (PTQ) has emerged as a subject of considerable interest due to its noteworthy compression efficiency and cost-effectiveness in the context of training. Existing PTQ methods for LLMs limit the optimization scope to scaling transformations between pre- and post-quantization weights. In this paper, we advocate for the direct optimization using equivalent Affine transformations in PTQ (AffineQuant). This approach extends the optimization scope and thus significantly minimizing quantization errors. Additionally, by employing the corresponding inverse matrix, we can ensure equivalence between the pre- and post-quantization outputs of PTQ, thereby maintaining its efficiency and generalization capabilities. To ensure the invertibility of the transformation during optimization, we further introduce a gradual mask optimization method. This method initially focuses on optimizing the diagonal elements and gradually extends to the other elements. Such an approach aligns with the Levy-Desplanques theorem, theoretically ensuring invertibility of the transformation. As a result, significant performance improvements are evident across different LLMs on diverse datasets. To illustrate, we attain a C4 perplexity of 15.76 (2.26 lower vs 18.02 in OmniQuant) on the LLaMA2-7B model of W4A4 quantization without overhead. On zero-shot tasks, AffineQuant achieves an average of 58.61 accuracy (1.98 lower vs 56.63 in OmniQuant) when using 4/4-bit quantization for LLaMA-30B, which setting a new state-of-the-art benchmark for PTQ in LLMs.
Solving Oscillation Problem in Post-Training Quantization Through a Theoretical Perspective
Apr 04, 2023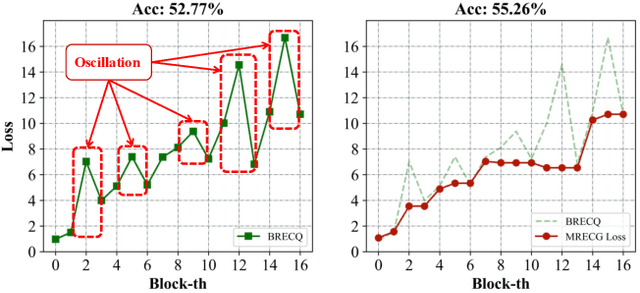
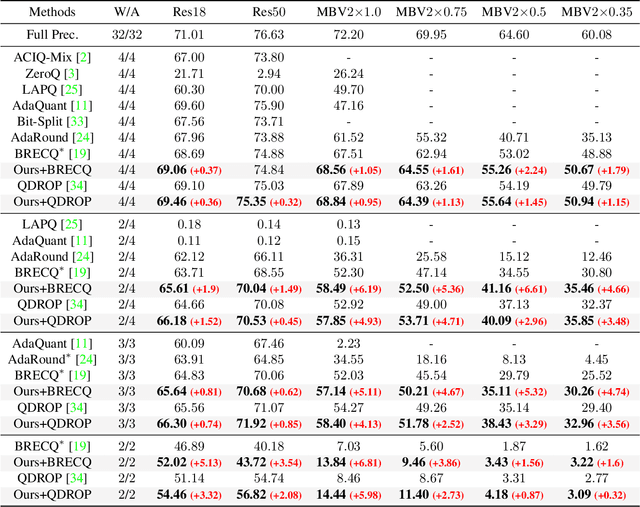
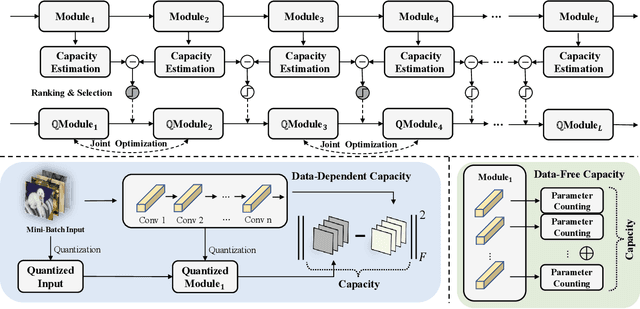
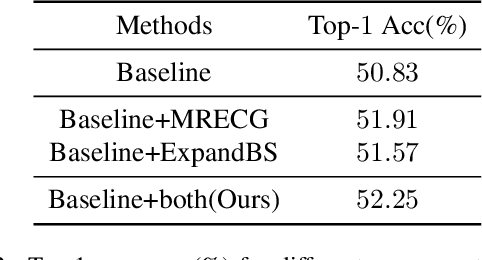
Post-training quantization (PTQ) is widely regarded as one of the most efficient compression methods practically, benefitting from its data privacy and low computation costs. We argue that an overlooked problem of oscillation is in the PTQ methods. In this paper, we take the initiative to explore and present a theoretical proof to explain why such a problem is essential in PTQ. And then, we try to solve this problem by introducing a principled and generalized framework theoretically. In particular, we first formulate the oscillation in PTQ and prove the problem is caused by the difference in module capacity. To this end, we define the module capacity (ModCap) under data-dependent and data-free scenarios, where the differentials between adjacent modules are used to measure the degree of oscillation. The problem is then solved by selecting top-k differentials, in which the corresponding modules are jointly optimized and quantized. Extensive experiments demonstrate that our method successfully reduces the performance drop and is generalized to different neural networks and PTQ methods. For example, with 2/4 bit ResNet-50 quantization, our method surpasses the previous state-of-the-art method by 1.9%. It becomes more significant on small model quantization, e.g. surpasses BRECQ method by 6.61% on MobileNetV2*0.5.
OMPQ: Orthogonal Mixed Precision Quantization
Sep 16, 2021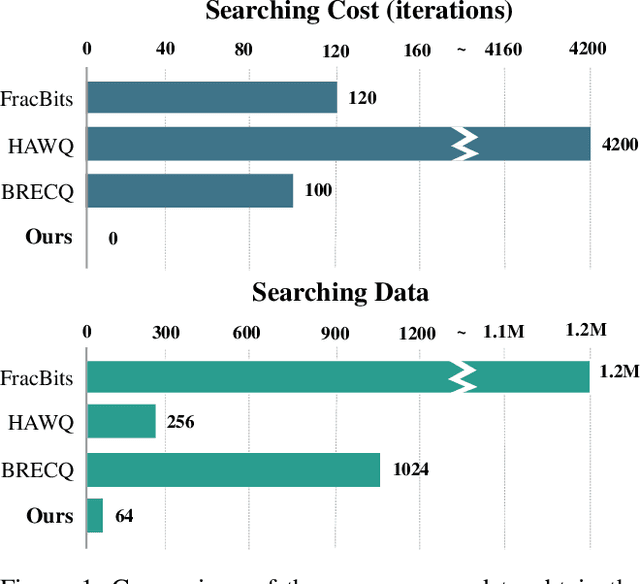


To bridge the ever increasing gap between deep neural networks' complexity and hardware capability, network quantization has attracted more and more research attention. The latest trend of mixed precision quantization takes advantage of hardware's multiple bit-width arithmetic operations to unleash the full potential of network quantization. However, this also results in a difficult integer programming formulation, and forces most existing approaches to use an extremely time-consuming search process even with various relaxations. Instead of solving a problem of the original integer programming, we propose to optimize a proxy metric, the concept of network orthogonality, which is highly correlated with the loss of the integer programming but also easy to optimize with linear programming. This approach reduces the search time and required data amount by orders of magnitude, with little compromise on quantization accuracy. Specifically, on post-training quantization, we achieve 71.27% Top-1 accuracy on MobileNetV2, which only takes 9 seconds for searching and 1.4 GPU hours for finetuning on ImageNet. Our codes are avaliable at https://github.com/MAC-AutoML/OMPQ.
An Information Theory-inspired Strategy for Automatic Network Pruning
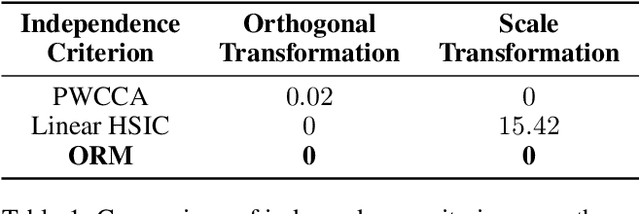
Aug 19, 2021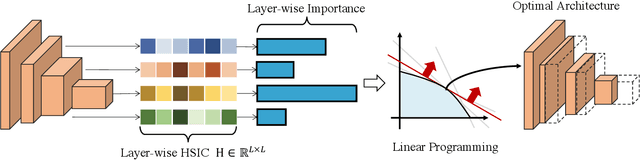
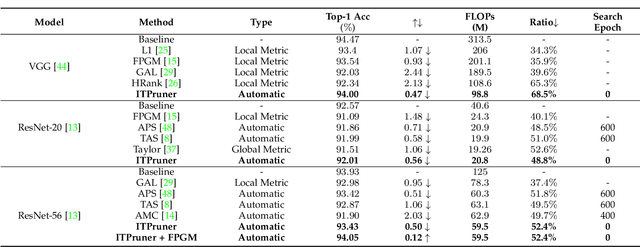
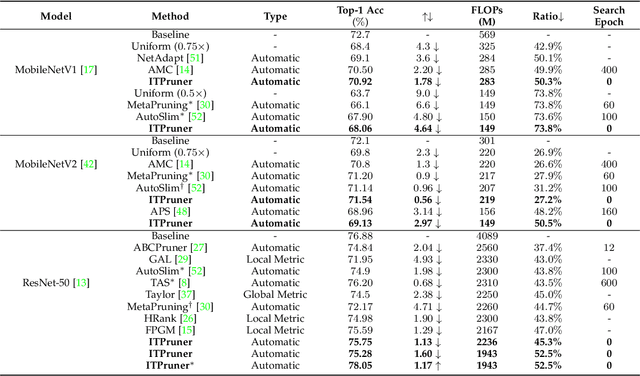
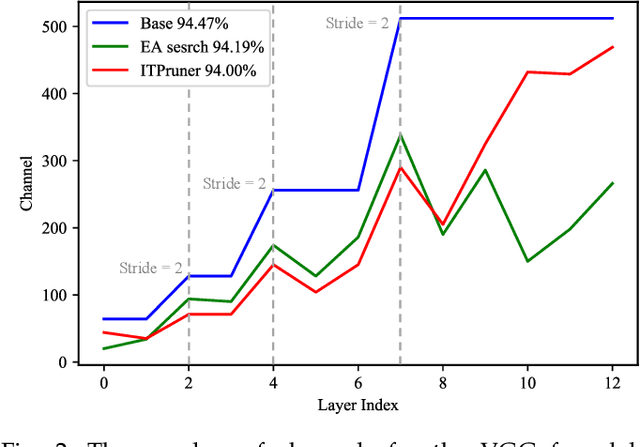
Despite superior performance on many computer vision tasks, deep convolution neural networks are well known to be compressed on devices that have resource constraints. Most existing network pruning methods require laborious human efforts and prohibitive computation resources, especially when the constraints are changed. This practically limits the application of model compression when the model needs to be deployed on a wide range of devices. Besides, existing methods are still challenged by the missing theoretical guidance. In this paper we propose an information theory-inspired strategy for automatic model compression. The principle behind our method is the information bottleneck theory, i.e., the hidden representation should compress information with each other. We thus introduce the normalized Hilbert-Schmidt Independence Criterion (nHSIC) on network activations as a stable and generalized indicator of layer importance. When a certain resource constraint is given, we integrate the HSIC indicator with the constraint to transform the architecture search problem into a linear programming problem with quadratic constraints. Such a problem is easily solved by a convex optimization method with a few seconds. We also provide a rigorous proof to reveal that optimizing the normalized HSIC simultaneously minimizes the mutual information between different layers. Without any search process, our method achieves better compression tradeoffs comparing to the state-of-the-art compression algorithms. For instance, with ResNet-50, we achieve a 45.3%-FLOPs reduction, with a 75.75 top-1 accuracy on ImageNet. Codes are avaliable at https://github.com/MAC-AutoML/ITPruner/tree/master.