 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperior Computer Chess with Model Predictive Control, Reinforcement Learning, and Rollout
Sep 10, 2024In this paper we apply model predictive control (MPC), rollout, and reinforcement learning (RL) methodologies to computer chess. We introduce a new architecture for move selection, within which available chess engines are used as components. One engine is used to provide position evaluations in an approximation in value space MPC/RL scheme, while a second engine is used as nominal opponent, to emulate or approximate the moves of the true opponent player. We show that our architecture improves substantially the performance of the position evaluation engine. In other words our architecture provides an additional layer of intelligence, on top of the intelligence of the engines on which it is based. This is true for any engine, regardless of its strength: top engines such as Stockfish and Komodo Dragon (of varying strengths), as well as weaker engines. Structurally, our basic architecture selects moves by a one-move lookahead search, with an intermediate move generated by a nominal opponent engine, and followed by a position evaluation by another chess engine. Simpler schemes that forego the use of the nominal opponent, also perform better than the position evaluator, but not quite by as much. More complex schemes, involving multistep lookahead, may also be used and generally tend to perform better as the length of the lookahead increases. Theoretically, our methodology relies on generic cost improvement properties and the superlinear convergence framework of Newton's method, which fundamentally underlies approximation in value space, and related MPC/RL and rollout/policy iteration schemes. A critical requirement of this framework is that the first lookahead step should be executed exactly. This fact has guided our architectural choices, and is apparently an important factor in improving the performance of even the best available chess engines.
An Approximate Dynamic Programming Framework for Occlusion-Robust Multi-Object Tracking
May 24, 2024In this work, we consider data association problems involving multi-object tracking (MOT). In particular, we address the challenges arising from object occlusions. We propose a framework called approximate dynamic programming track (ADPTrack), which applies dynamic programming principles to improve an existing method called the base heuristic. Given a set of tracks and the next target frame, the base heuristic extends the tracks by matching them to the objects of this target frame directly. In contrast, ADPTrack first processes a few subsequent frames and applies the base heuristic starting from the next target frame to obtain tentative tracks. It then leverages the tentative tracks to match the objects of the target frame. This tends to reduce the occlusion-based errors and leads to an improvement over the base heuristic. When tested on the MOT17 video dataset, the proposed method demonstrates a 0.7% improvement in the association accuracy (IDF1 metric) over a state-of-the-art method that is used as the base heuristic. It also obtains improvements with respect to all the other standard metrics. Empirically, we found that the improvements are particularly pronounced in scenarios where the video data is obtained by fixed-position cameras.
Most Likely Sequence Generation for $n$-Grams, Transformers, HMMs, and Markov Chains, by Using Rollout Algorithms
Mar 19, 2024In this paper we consider a transformer with an $n$-gram structure, such as the one underlying ChatGPT. The transformer provides next word probabilities, which can be used to generate word sequences. We consider methods for computing word sequences that are highly likely, based on these probabilities. Computing the optimal (i.e., most likely) word sequence starting with a given initial state is an intractable problem, so we propose methods to compute highly likely sequences of $N$ words in time that is a low order polynomial in $N$ and in the vocabulary size of the $n$-gram. These methods are based on the rollout approach from approximate dynamic programming, a form of single policy iteration, which can improve the performance of any given heuristic policy. In our case we use a greedy heuristic that generates as next word one that has the highest probability. We show with analysis, examples, and computational experimentation that our methods are capable of generating highly likely sequences with a modest increase in computation over the greedy heuristic. While our analysis and experiments are focused on Markov chains of the type arising in transformer and ChatGPT-like models, our methods apply to general finite-state Markov chains, and related inference applications of Hidden Markov Models (HMM), where Viterbi decoding is used extensively.
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity
Sep 19, 2023



With the fast growth of parameter size, it becomes increasingly challenging to deploy large generative models as they typically require large GPU memory consumption and massive computation. Unstructured model pruning has been a common approach to reduce both GPU memory footprint and the overall computation while retaining good model accuracy. However, the existing solutions do not provide a highly-efficient support for handling unstructured sparsity on modern GPUs, especially on the highly-structured Tensor Core hardware. Therefore, we propose Flash-LLM for enabling low-cost and highly-efficient large generative model inference with the sophisticated support of unstructured sparsity on high-performance but highly restrictive Tensor Cores. Based on our key observation that the main bottleneck of generative model inference is the several skinny matrix multiplications for which Tensor Cores would be significantly under-utilized due to low computational intensity, we propose a general Load-as-Sparse and Compute-as-Dense methodology for unstructured sparse matrix multiplication. The basic insight is to address the significant memory bandwidth bottleneck while tolerating redundant computations that are not critical for end-to-end performance on Tensor Cores. Based on this, we design an effective software framework for Tensor Core based unstructured SpMM, leveraging on-chip resources for efficient sparse data extraction and computation/memory-access overlapping. At SpMM kernel level, Flash-LLM significantly outperforms the state-of-the-art library, i.e., Sputnik and SparTA by an average of 2.9x and 1.5x, respectively. At end-to-end framework level on OPT-30B/66B/175B models, for tokens per GPU-second, Flash-LLM achieves up to 3.8x and 3.6x improvement over DeepSpeed and FasterTransformer, respectively, with significantly lower inference cost.
Multiagent Rollout with Reshuffling for Warehouse Robots Path Planning
Nov 15, 2022Efficiently solving path planning problems for a large number of robots is critical to the successful operation of modern warehouses. The existing approaches adopt classical shortest path algorithms to plan in environments whose cells are associated with both space and time in order to avoid collision between robots. In this work, we achieve the same goal by means of simulation in a smaller static environment. Built upon the new framework introduced in (Bertsekas, 2021a), we propose multiagent rollout with reshuffling algorithm, and apply it to address the warehouse robots path planning problem. The proposed scheme has a solid theoretical guarantee and exhibits consistent performance in our numerical studies. Moreover, it inherits from the generic rollout methods the ability to adapt to a changing environment by online replanning, which we demonstrate through examples where some robots malfunction.
Parameter-Efficient Sparsity for Large Language Models Fine-Tuning
May 23, 2022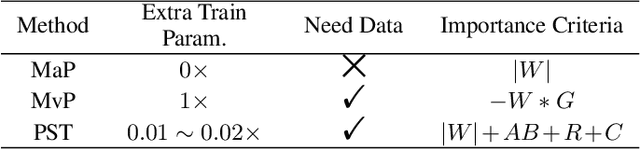
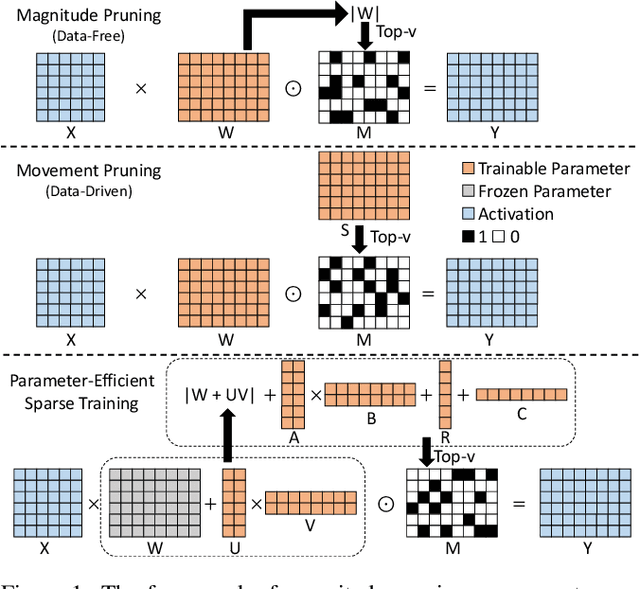
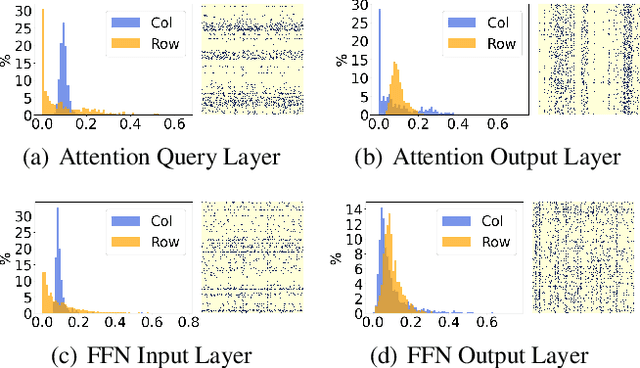
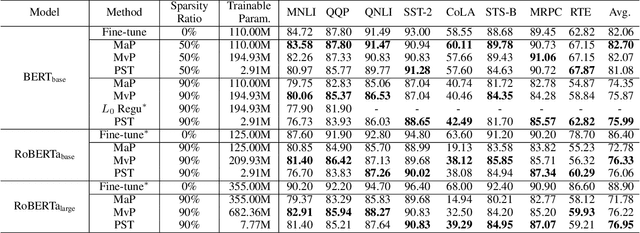
With the dramatically increased number of parameters in language models, sparsity methods have received ever-increasing research focus to compress and accelerate the models. While most research focuses on how to accurately retain appropriate weights while maintaining the performance of the compressed model, there are challenges in the computational overhead and memory footprint of sparse training when compressing large-scale language models. To address this problem, we propose a Parameter-efficient Sparse Training (PST) method to reduce the number of trainable parameters during sparse-aware training in downstream tasks. Specifically, we first combine the data-free and data-driven criteria to efficiently and accurately measure the importance of weights. Then we investigate the intrinsic redundancy of data-driven weight importance and derive two obvious characteristics i.e., low-rankness and structuredness. Based on that, two groups of small matrices are introduced to compute the data-driven importance of weights, instead of using the original large importance score matrix, which therefore makes the sparse training resource-efficient and parameter-efficient. Experiments with diverse networks (i.e., BERT, RoBERTa and GPT-2) on dozens of datasets demonstrate PST performs on par or better than previous sparsity methods, despite only training a small number of parameters. For instance, compared with previous sparsity methods, our PST only requires 1.5% trainable parameters to achieve comparable performance on BERT.
An Information Theory-inspired Strategy for Automatic Network Pruning
Aug 19, 2021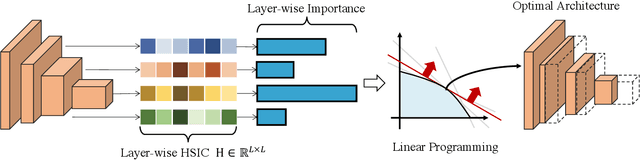
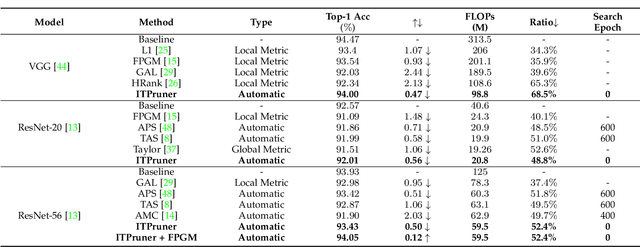
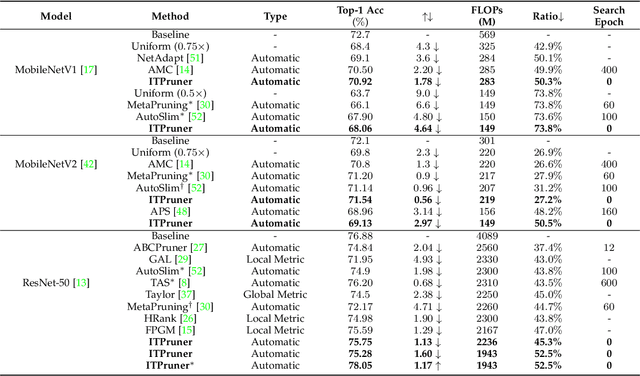
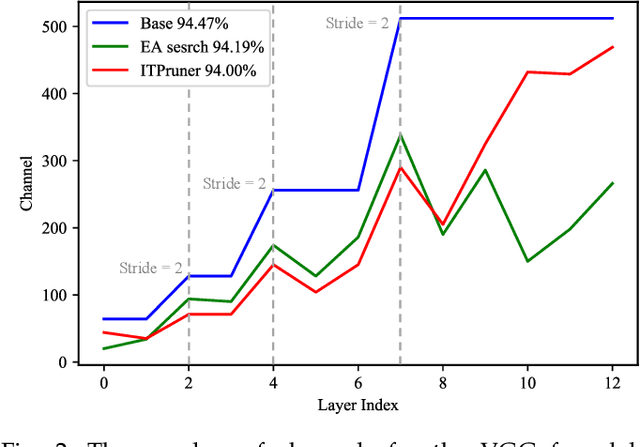
Despite superior performance on many computer vision tasks, deep convolution neural networks are well known to be compressed on devices that have resource constraints. Most existing network pruning methods require laborious human efforts and prohibitive computation resources, especially when the constraints are changed. This practically limits the application of model compression when the model needs to be deployed on a wide range of devices. Besides, existing methods are still challenged by the missing theoretical guidance. In this paper we propose an information theory-inspired strategy for automatic model compression. The principle behind our method is the information bottleneck theory, i.e., the hidden representation should compress information with each other. We thus introduce the normalized Hilbert-Schmidt Independence Criterion (nHSIC) on network activations as a stable and generalized indicator of layer importance. When a certain resource constraint is given, we integrate the HSIC indicator with the constraint to transform the architecture search problem into a linear programming problem with quadratic constraints. Such a problem is easily solved by a convex optimization method with a few seconds. We also provide a rigorous proof to reveal that optimizing the normalized HSIC simultaneously minimizes the mutual information between different layers. Without any search process, our method achieves better compression tradeoffs comparing to the state-of-the-art compression algorithms. For instance, with ResNet-50, we achieve a 45.3%-FLOPs reduction, with a 75.75 top-1 accuracy on ImageNet. Codes are avaliable at https://github.com/MAC-AutoML/ITPruner/tree/master.
1$\times$N Block Pattern for Network Sparsity
Jun 15, 2021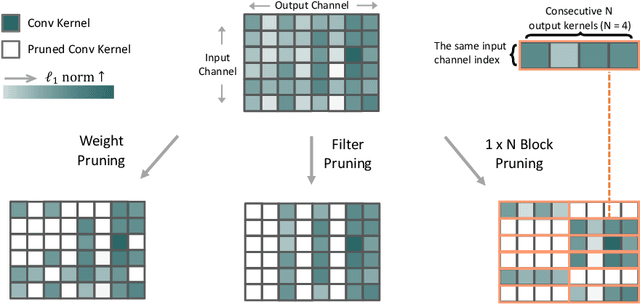

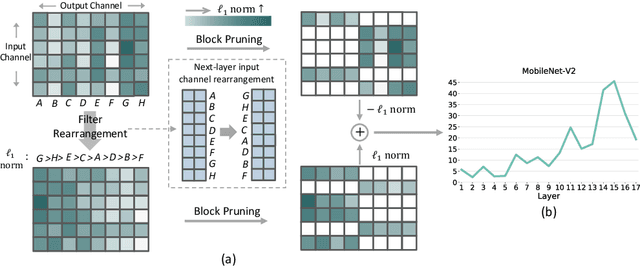
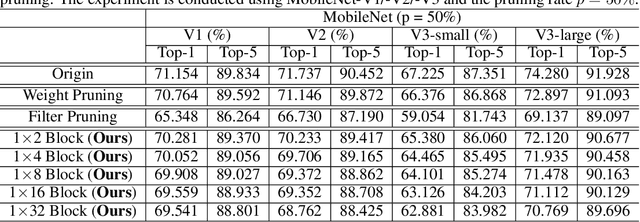
Though network sparsity emerges as a promising direction to overcome the drastically increasing size of neural networks, it remains an open problem to concurrently maintain model accuracy as well as achieve significant speedups on general CPUs. In this paper, we propose one novel concept of $1\times N$ block sparsity pattern (block pruning) to break this limitation. In particular, consecutive $N$ output kernels with the same input channel index are grouped into one block, which serves as a basic pruning granularity of our pruning pattern. Our $1 \times N$ sparsity pattern prunes these blocks considered unimportant. We also provide a workflow of filter rearrangement that first rearranges the weight matrix in the output channel dimension to derive more influential blocks for accuracy improvements, and then applies similar rearrangement to the next-layer weights in the input channel dimension to ensure correct convolutional operations. Moreover, the output computation after our $1 \times N$ block sparsity can be realized via a parallelized block-wise vectorized operation, leading to significant speedups on general CPUs-based platforms. The efficacy of our pruning pattern is proved with experiments on ILSVRC-2012. For example, in the case of 50% sparsity and $N=4$, our pattern obtains about 3.0% improvements over filter pruning in the top-1 accuracy of MobileNet-V2. Meanwhile, it obtains 56.04ms inference savings on Cortex-A7 CPU over weight pruning. Code is available at https://github.com/lmbxmu/1xN.
You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient
Jun 04, 2021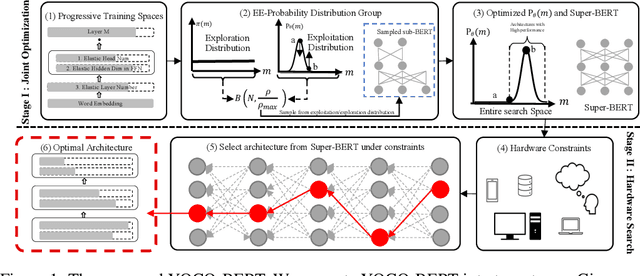
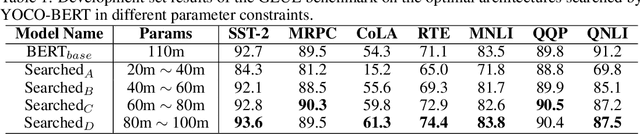
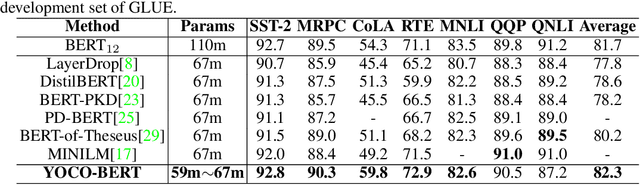
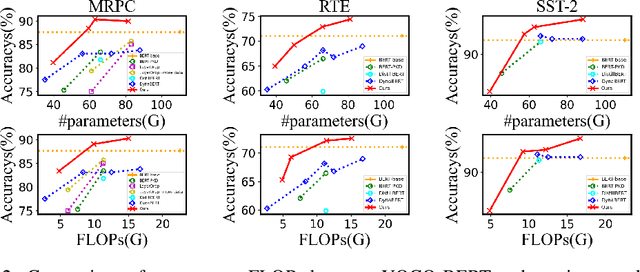
Despite superior performance on various natural language processing tasks, pre-trained models such as BERT are challenged by deploying on resource-constraint devices. Most existing model compression approaches require re-compression or fine-tuning across diverse constraints to accommodate various hardware deployments. This practically limits the further application of model compression. Moreover, the ineffective training and searching process of existing elastic compression paradigms[4,27] prevents the direct migration to BERT compression. Motivated by the necessity of efficient inference across various constraints on BERT, we propose a novel approach, YOCO-BERT, to achieve compress once and deploy everywhere. Specifically, we first construct a huge search space with 10^13 architectures, which covers nearly all configurations in BERT model. Then, we propose a novel stochastic nature gradient optimization method to guide the generation of optimal candidate architecture which could keep a balanced trade-off between explorations and exploitation. When a certain resource constraint is given, a lightweight distribution optimization approach is utilized to obtain the optimal network for target deployment without fine-tuning. Compared with state-of-the-art algorithms, YOCO-BERT provides more compact models, yet achieving 2.1%-4.5% average accuracy improvement on the GLUE benchmark. Besides, YOCO-BERT is also more effective, e.g.,the training complexity is O(1)for N different devices. Code is availablehttps://github.com/MAC-AutoML/YOCO-BERT.
Towards Compact CNNs via Collaborative Compression
May 24, 2021
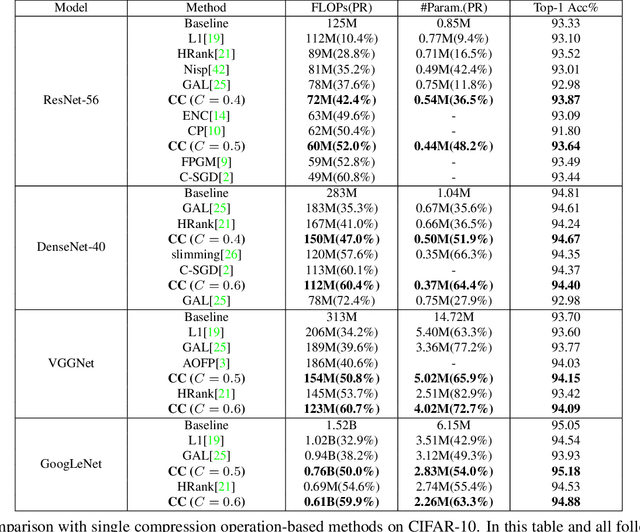
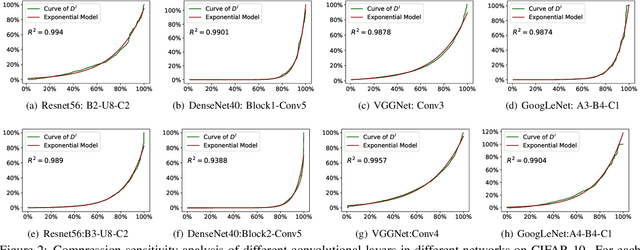
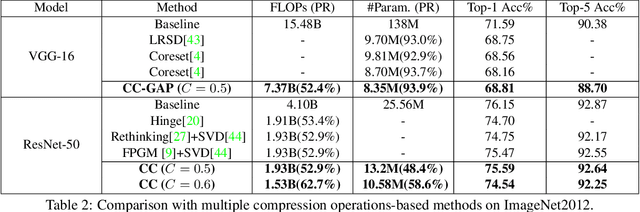
Channel pruning and tensor decomposition have received extensive attention in convolutional neural network compression. However, these two techniques are traditionally deployed in an isolated manner, leading to significant accuracy drop when pursuing high compression rates. In this paper, we propose a Collaborative Compression (CC) scheme, which joints channel pruning and tensor decomposition to compress CNN models by simultaneously learning the model sparsity and low-rankness. Specifically, we first investigate the compression sensitivity of each layer in the network, and then propose a Global Compression Rate Optimization that transforms the decision problem of compression rate into an optimization problem. After that, we propose multi-step heuristic compression to remove redundant compression units step-by-step, which fully considers the effect of the remaining compression space (i.e., unremoved compression units). Our method demonstrates superior performance gains over previous ones on various datasets and backbone architectures. For example, we achieve 52.9% FLOPs reduction by removing 48.4% parameters on ResNet-50 with only a Top-1 accuracy drop of 0.56% on ImageNet 2012.