 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation
Jun 02, 2026In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at long-term planning, while VLAs are better at reactive control. However, their performance is limited by the same perceptual bottleneck: visual hallucinations arise due to the models' inability to distinguish task-relevant objects from distractors. In principle, accurate identification and focus on critical objects while filtering out irrelevant ones is the key to break this limitation. A straightforward solution is one-step focus: directly attending to essential objects. However, this approach proves ineffective because effective focus inherently requires deep scene understanding. To this end, we propose SceneDiver, a coarse-to-fine focus plan generation method for VLMs leveraging their long-term planning abilities, that first constructs a holistic scene graph to establish initial comprehension, then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis. To enable reactive control, we also design a lightweight adapter for distilling the deliberate focus ability into VLAs. Evaluations on standard embodied AI benchmarks confirm that our method substantially reduces visual hallucinations for both VLMs and VLAs, while preserving computational efficiency in tasks requiring fast execution. Our code and data are released at: https://future-item.github.io/SceneDiver.
EchoAvatar: Real-time Generative Avatar Animation from Audio Streams
May 27, 2026Real-time synthesis of high-fidelity 3D character motion from audio is a pivotal component for next-generation interactive avatars and virtual assistants. However, most existing approaches are limited to offline processing of complete audio sequences or are constrained to specific domains, rarely handling both speech and music effectively. In this paper, we introduce a novel framework designed to generate continuous, coherent full-body motion from streaming speech and music with low latency. Central to our approach is a unified streaming architecture capable of synthesizing continuous motion from incremental audio inputs. We employ a robust training strategy that enforces strong audio dependency, allowing the model to seamlessly generalize across conversational speech and rhythmic music without requiring explicit domain labels or mode switching. Additionally, we explored Reinforcement Learning to refine the quality of online generation. Furthermore, we bridge reactive animation with intent-driven behavior via a tool-call interface that allows upstream Large Language Models to inject explicit semantic control. By combining this controllability with stream audio-driven synthesis, our framework serves as a plug-and-play solution for transforming voice agents into interactive humanoid avatars. Extensive experiments demonstrate that our method outperforms state-of-the-art realtime baselines in motion quality and synchronization while maintaining the flexibility required for live deployment. Our code, pre-trained models, and videos are available at https://robinwitch.github.io/EchoAvatar-Page.
DyStream: Streaming Dyadic Talking Heads Generation via Flow Matching-based Autoregressive Model
Dec 30, 2025Generating realistic, dyadic talking head video requires ultra-low latency. Existing chunk-based methods require full non-causal context windows, introducing significant delays. This high latency critically prevents the immediate, non-verbal feedback required for a realistic listener. To address this, we present DyStream, a flow matching-based autoregressive model that could generate video in real-time from both speaker and listener audio. Our method contains two key designs: (1) we adopt a stream-friendly autoregressive framework with flow-matching heads for probabilistic modeling, and (2) We propose a causal encoder enhanced by a lookahead module to incorporate short future context (e.g., 60 ms) to improve quality while maintaining low latency. Our analysis shows this simple-and-effective method significantly surpass alternative causal strategies, including distillation and generative encoder. Extensive experiments show that DyStream could generate video within 34 ms per frame, guaranteeing the entire system latency remains under 100 ms. Besides, it achieves state-of-the-art lip-sync quality, with offline and online LipSync Confidence scores of 8.13 and 7.61 on HDTF, respectively. The model, weights and codes are available.
Motion-example-controlled Co-speech Gesture Generation Leveraging Large Language Models
Jul 27, 2025The automatic generation of controllable co-speech gestures has recently gained growing attention. While existing systems typically achieve gesture control through predefined categorical labels or implicit pseudo-labels derived from motion examples, these approaches often compromise the rich details present in the original motion examples. We present MECo, a framework for motion-example-controlled co-speech gesture generation by leveraging large language models (LLMs). Our method capitalizes on LLMs' comprehension capabilities through fine-tuning to simultaneously interpret speech audio and motion examples, enabling the synthesis of gestures that preserve example-specific characteristics while maintaining speech congruence. Departing from conventional pseudo-labeling paradigms, we position motion examples as explicit query contexts within the prompt structure to guide gesture generation. Experimental results demonstrate state-of-the-art performance across three metrics: Fr\'echet Gesture Distance (FGD), motion diversity, and example-gesture similarity. Furthermore, our framework enables granular control of individual body parts and accommodates diverse input modalities including motion clips, static poses, human video sequences, and textual descriptions. Our code, pre-trained models, and videos are available at https://robinwitch.github.io/MECo-Page.
Enabling Synergistic Full-Body Control in Prompt-Based Co-Speech Motion Generation
Oct 01, 2024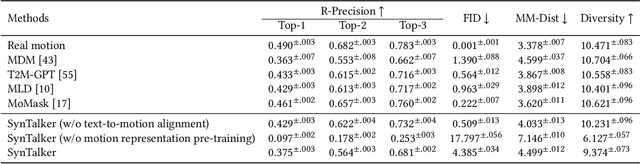
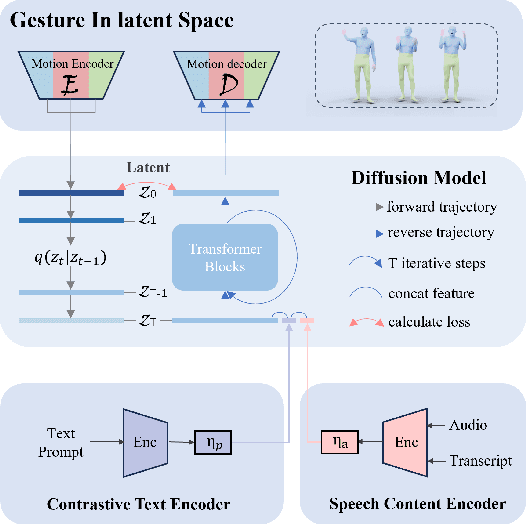
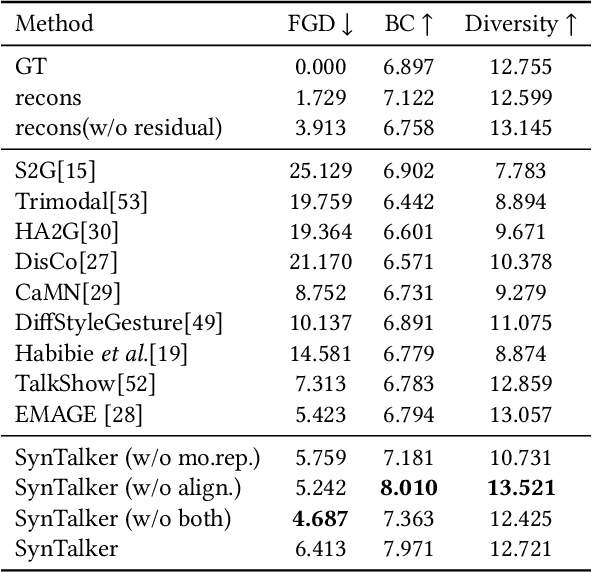
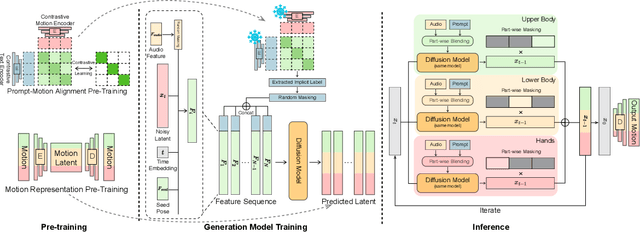
Current co-speech motion generation approaches usually focus on upper body gestures following speech contents only, while lacking supporting the elaborate control of synergistic full-body motion based on text prompts, such as talking while walking. The major challenges lie in 1) the existing speech-to-motion datasets only involve highly limited full-body motions, making a wide range of common human activities out of training distribution; 2) these datasets also lack annotated user prompts. To address these challenges, we propose SynTalker, which utilizes the off-the-shelf text-to-motion dataset as an auxiliary for supplementing the missing full-body motion and prompts. The core technical contributions are two-fold. One is the multi-stage training process which obtains an aligned embedding space of motion, speech, and prompts despite the significant distributional mismatch in motion between speech-to-motion and text-to-motion datasets. Another is the diffusion-based conditional inference process, which utilizes the separate-then-combine strategy to realize fine-grained control of local body parts. Extensive experiments are conducted to verify that our approach supports precise and flexible control of synergistic full-body motion generation based on both speeches and user prompts, which is beyond the ability of existing approaches.
ARM: Any-Time Super-Resolution Method
Mar 21, 2022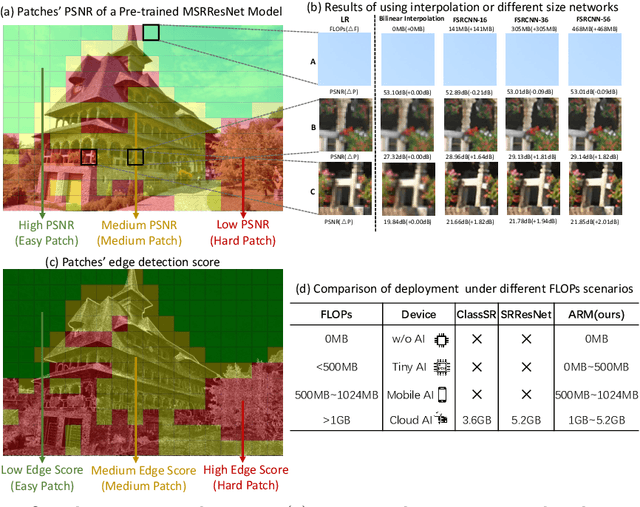
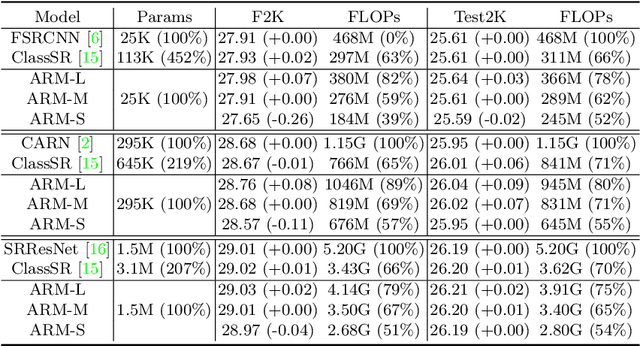

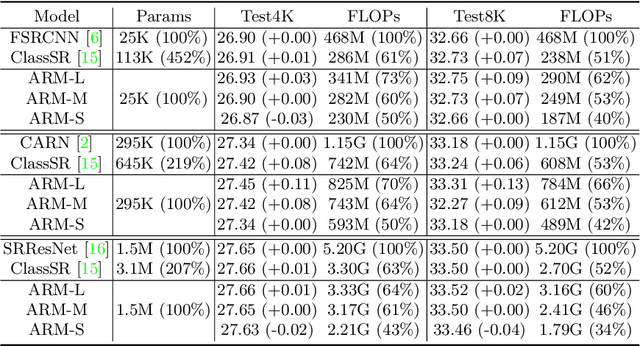
This paper proposes an Any-time super-Resolution Method (ARM) to tackle the over-parameterized single image super-resolution (SISR) models. Our ARM is motivated by three observations: (1) The performance of different image patches varies with SISR networks of different sizes. (2) There is a tradeoff between computation overhead and performance of the reconstructed image. (3) Given an input image, its edge information can be an effective option to estimate its PSNR. Subsequently, we train an ARM supernet containing SISR subnets of different sizes to deal with image patches of various complexity. To that effect, we construct an Edge-to-PSNR lookup table that maps the edge score of an image patch to the PSNR performance for each subnet, together with a set of computation costs for the subnets. In the inference, the image patches are individually distributed to different subnets for a better computation-performance tradeoff. Moreover, each SISR subnet shares weights of the ARM supernet, thus no extra parameters are introduced. The setting of multiple subnets can well adapt the computational cost of SISR model to the dynamically available hardware resources, allowing the SISR task to be in service at any time. Extensive experiments on resolution datasets of different sizes with popular SISR networks as backbones verify the effectiveness and the versatility of our ARM. The source code is available at \url{https://github.com/chenbong/ARM-Net}.
Prioritized Subnet Sampling for Resource-Adaptive Supernet Training
Sep 12, 2021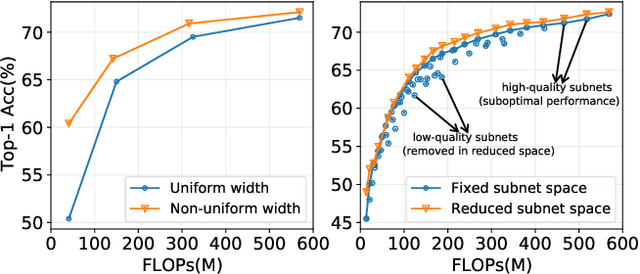
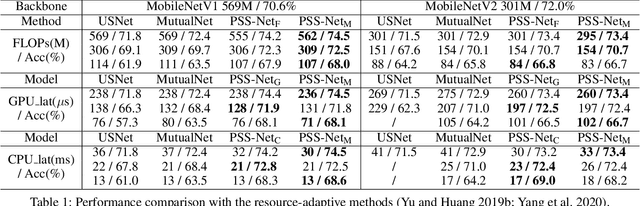
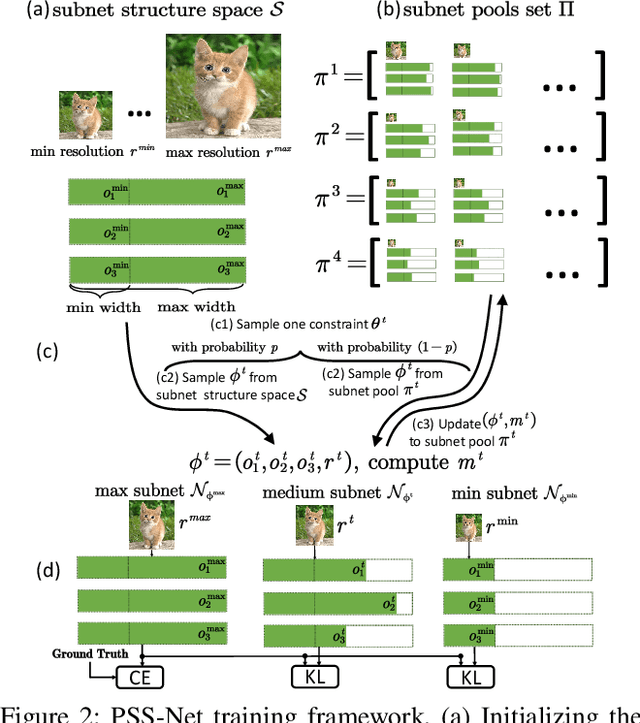
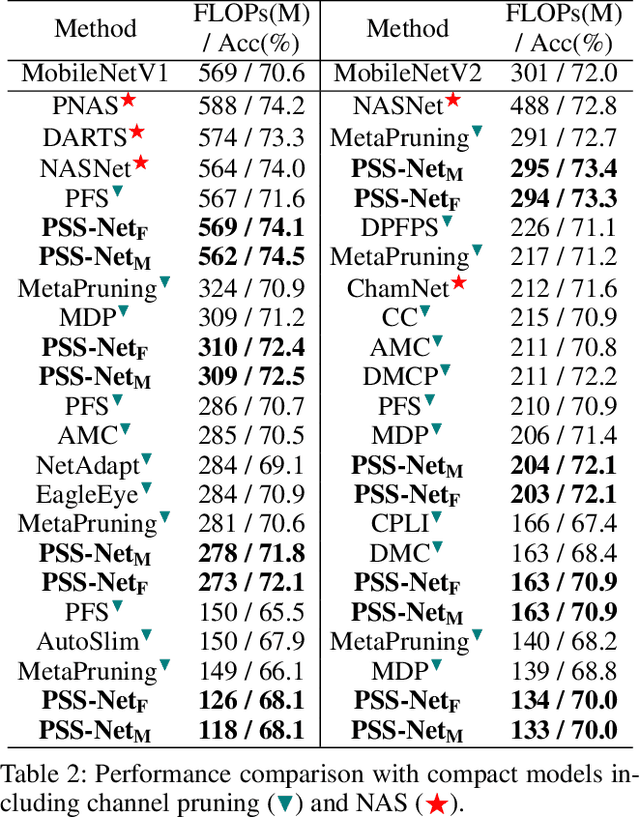
A resource-adaptive supernet adjusts its subnets for inference to fit the dynamically available resources. In this paper, we propose Prioritized Subnet Sampling to train a resource-adaptive supernet, termed PSS-Net. We maintain multiple subnet pools, each of which stores the information of substantial subnets with similar resource consumption. Considering a resource constraint, subnets conditioned on this resource constraint are sampled from a pre-defined subnet structure space and high-quality ones will be inserted into the corresponding subnet pool. Then, the sampling will gradually be prone to sampling subnets from the subnet pools. Moreover, the one with a better performance metric is assigned with higher priority to train our PSS-Net, if sampling is from a subnet pool. At the end of training, our PSS-Net retains the best subnet in each pool to entitle a fast switch of high-quality subnets for inference when the available resources vary. Experiments on ImageNet using MobileNetV1/V2 show that our PSS-Net can well outperform state-of-the-art resource-adaptive supernets. Our project is at https://github.com/chenbong/PSS-Net.
Training Compact CNNs for Image Classification using Dynamic-coded Filter Fusion
Jul 14, 2021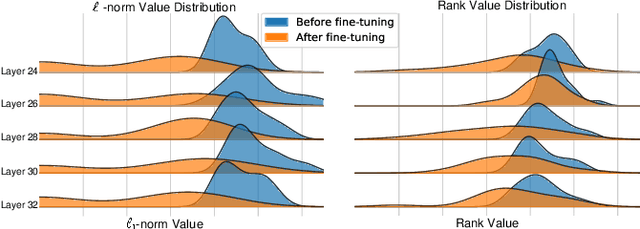
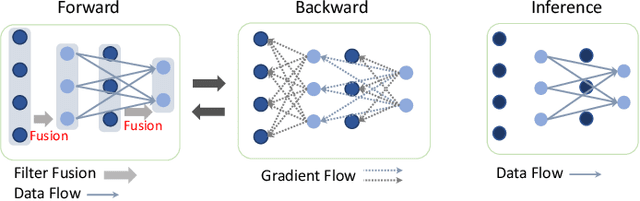
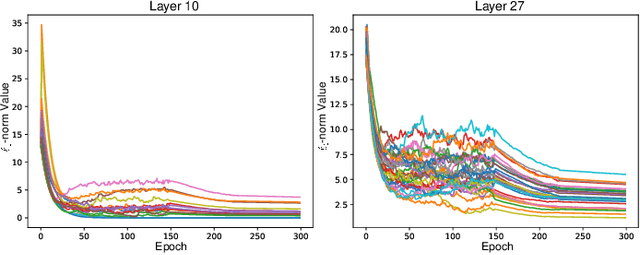

The mainstream approach for filter pruning is usually either to force a hard-coded importance estimation upon a computation-heavy pretrained model to select "important" filters, or to impose a hyperparameter-sensitive sparse constraint on the loss objective to regularize the network training. In this paper, we present a novel filter pruning method, dubbed dynamic-coded filter fusion (DCFF), to derive compact CNNs in a computation-economical and regularization-free manner for efficient image classification. Each filter in our DCFF is firstly given an inter-similarity distribution with a temperature parameter as a filter proxy, on top of which, a fresh Kullback-Leibler divergence based dynamic-coded criterion is proposed to evaluate the filter importance. In contrast to simply keeping high-score filters in other methods, we propose the concept of filter fusion, i.e., the weighted averages using the assigned proxies, as our preserved filters. We obtain a one-hot inter-similarity distribution as the temperature parameter approaches infinity. Thus, the relative importance of each filter can vary along with the training of the compact CNN, leading to dynamically changeable fused filters without both the dependency on the pretrained model and the introduction of sparse constraints. Extensive experiments on classification benchmarks demonstrate the superiority of our DCFF over the compared counterparts. For example, our DCFF derives a compact VGGNet-16 with only 72.77M FLOPs and 1.06M parameters while reaching top-1 accuracy of 93.47% on CIFAR-10. A compact ResNet-50 is obtained with 63.8% FLOPs and 58.6% parameter reductions, retaining 75.60% top-1 accuracy on ILSVRC-2012. Our code, narrower models and training logs are available at https://github.com/lmbxmu/DCFF.
1$\times$N Block Pattern for Network Sparsity
Jun 15, 2021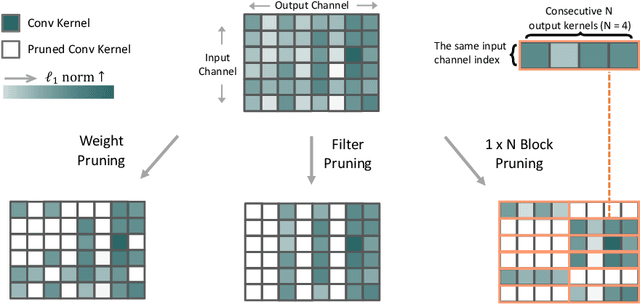

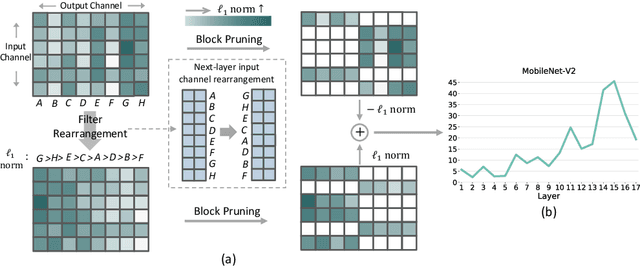
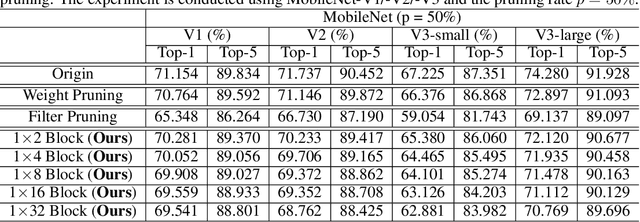
Though network sparsity emerges as a promising direction to overcome the drastically increasing size of neural networks, it remains an open problem to concurrently maintain model accuracy as well as achieve significant speedups on general CPUs. In this paper, we propose one novel concept of $1\times N$ block sparsity pattern (block pruning) to break this limitation. In particular, consecutive $N$ output kernels with the same input channel index are grouped into one block, which serves as a basic pruning granularity of our pruning pattern. Our $1 \times N$ sparsity pattern prunes these blocks considered unimportant. We also provide a workflow of filter rearrangement that first rearranges the weight matrix in the output channel dimension to derive more influential blocks for accuracy improvements, and then applies similar rearrangement to the next-layer weights in the input channel dimension to ensure correct convolutional operations. Moreover, the output computation after our $1 \times N$ block sparsity can be realized via a parallelized block-wise vectorized operation, leading to significant speedups on general CPUs-based platforms. The efficacy of our pruning pattern is proved with experiments on ILSVRC-2012. For example, in the case of 50% sparsity and $N=4$, our pattern obtains about 3.0% improvements over filter pruning in the top-1 accuracy of MobileNet-V2. Meanwhile, it obtains 56.04ms inference savings on Cortex-A7 CPU over weight pruning. Code is available at https://github.com/lmbxmu/1xN.