 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Domain Adaptation for Face Anti-Spoofing
Jul 20, 2022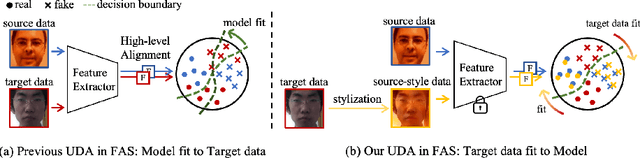
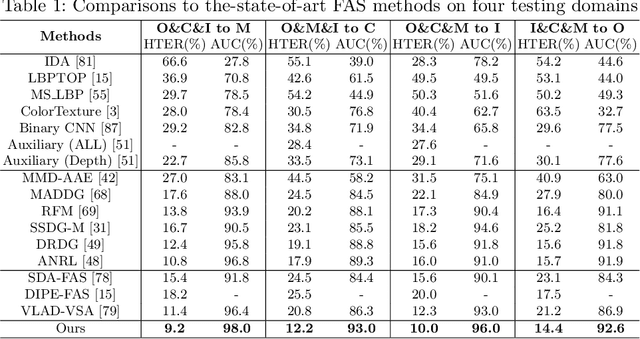
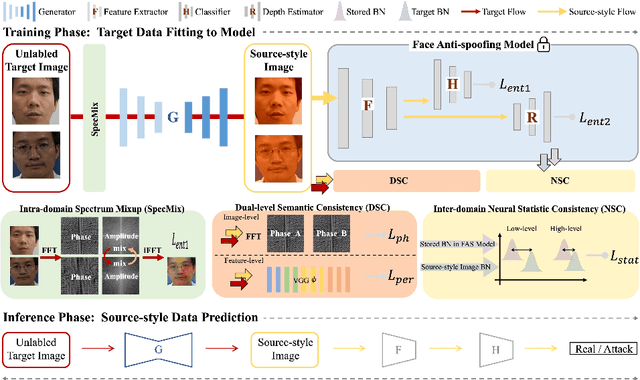
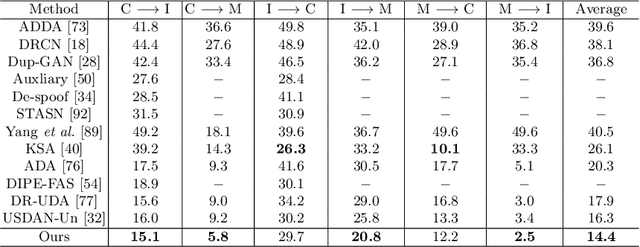
Face anti-spoofing (FAS) approaches based on unsupervised domain adaption (UDA) have drawn growing attention due to promising performances for target scenarios. Most existing UDA FAS methods typically fit the trained models to the target domain via aligning the distribution of semantic high-level features. However, insufficient supervision of unlabeled target domains and neglect of low-level feature alignment degrade the performances of existing methods. To address these issues, we propose a novel perspective of UDA FAS that directly fits the target data to the models, i.e., stylizes the target data to the source-domain style via image translation, and further feeds the stylized data into the well-trained source model for classification. The proposed Generative Domain Adaptation (GDA) framework combines two carefully designed consistency constraints: 1) Inter-domain neural statistic consistency guides the generator in narrowing the inter-domain gap. 2) Dual-level semantic consistency ensures the semantic quality of stylized images. Besides, we propose intra-domain spectrum mixup to further expand target data distributions to ensure generalization and reduce the intra-domain gap. Extensive experiments and visualizations demonstrate the effectiveness of our method against the state-of-the-art methods.
Open Vocabulary Object Detection with Proposal Mining and Prediction Equalization
Jun 24, 2022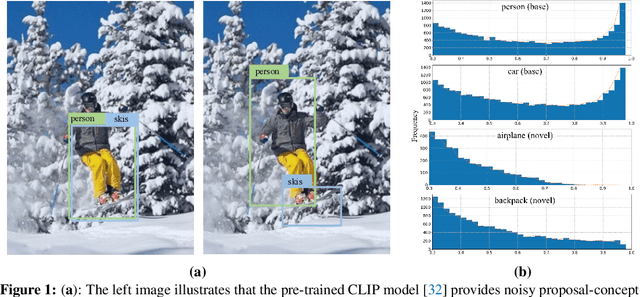
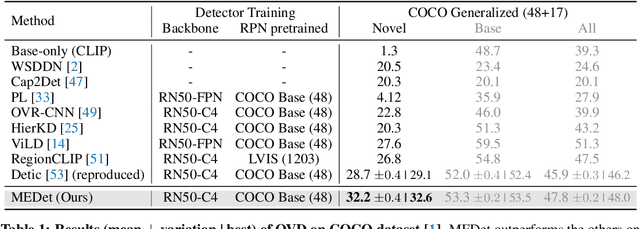
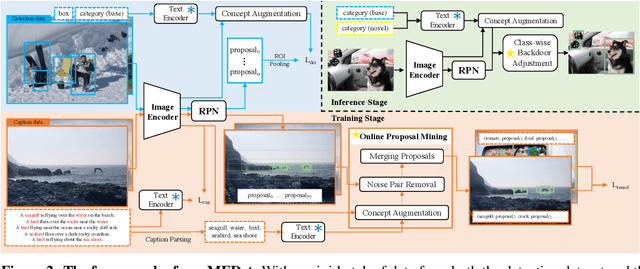
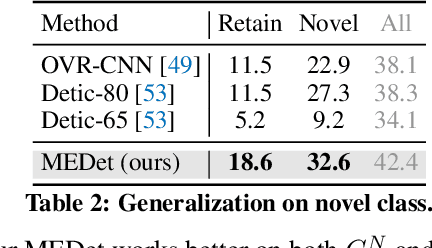
Open-vocabulary object detection (OVD) aims to scale up vocabulary size to detect objects of novel categories beyond the training vocabulary. Recent work resorts to the rich knowledge in pre-trained vision-language models. However, existing methods are ineffective in proposal-level vision-language alignment. Meanwhile, the models usually suffer from confidence bias toward base categories and perform worse on novel ones. To overcome the challenges, we present MEDet, a novel and effective OVD framework with proposal mining and prediction equalization. First, we design an online proposal mining to refine the inherited vision-semantic knowledge from coarse to fine, allowing for proposal-level detection-oriented feature alignment. Second, based on causal inference theory, we introduce a class-wise backdoor adjustment to reinforce the predictions on novel categories to improve the overall OVD performance. Extensive experiments on COCO and LVIS benchmarks verify the superiority of MEDet over the competing approaches in detecting objects of novel categories, e.g., 32.6% AP50 on COCO and 22.4% mask mAP on LVIS.
Efficient Decoder-free Object Detection with Transformers
Jun 17, 2022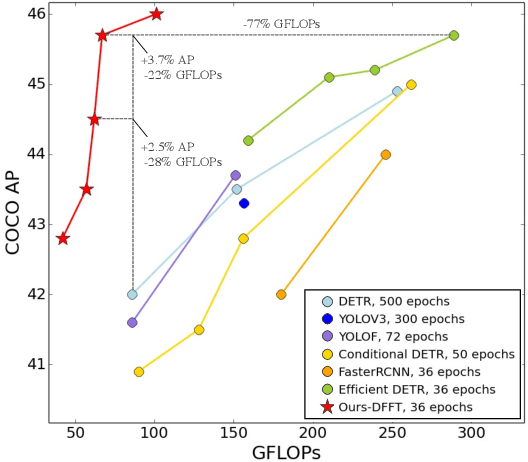
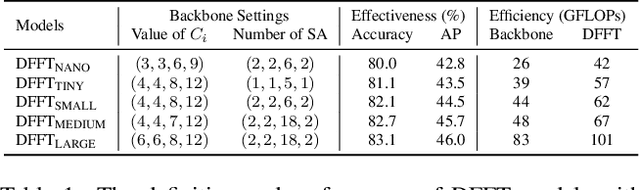
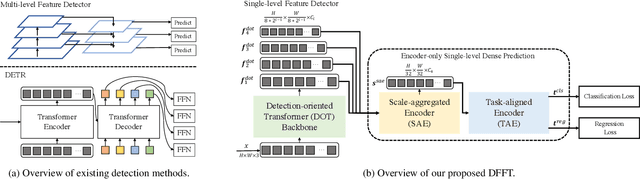
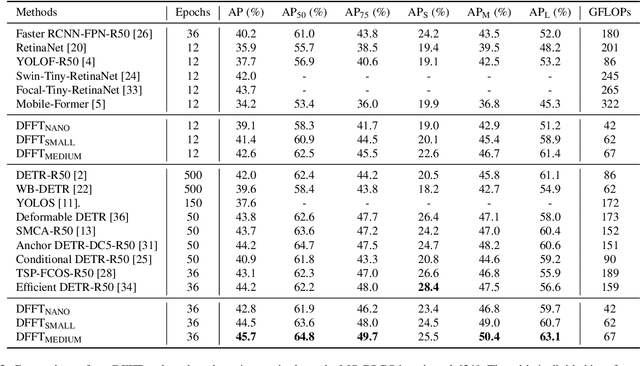
Vision transformers (ViTs) are changing the landscape of object detection approaches. A natural usage of ViTs in detection is to replace the CNN-based backbone with a transformer-based backbone, which is straightforward and effective, with the price of bringing considerable computation burden for inference. More subtle usage is the DETR family, which eliminates the need for many hand-designed components in object detection but introduces a decoder demanding an extra-long time to converge. As a result, transformer-based object detection can not prevail in large-scale applications. To overcome these issues, we propose a novel decoder-free fully transformer-based (DFFT) object detector, achieving high efficiency in both training and inference stages, for the first time. We simplify objection detection into an encoder-only single-level anchor-based dense prediction problem by centering around two entry points: 1) Eliminate the training-inefficient decoder and leverage two strong encoders to preserve the accuracy of single-level feature map prediction; 2) Explore low-level semantic features for the detection task with limited computational resources. In particular, we design a novel lightweight detection-oriented transformer backbone that efficiently captures low-level features with rich semantics based on a well-conceived ablation study. Extensive experiments on the MS COCO benchmark demonstrate that DFFT_SMALL outperforms DETR by 2.5% AP with 28% computation cost reduction and more than $10$x fewer training epochs. Compared with the cutting-edge anchor-based detector RetinaNet, DFFT_SMALL obtains over 5.5% AP gain while cutting down 70% computation cost.
Training-free Transformer Architecture Search
Mar 23, 2022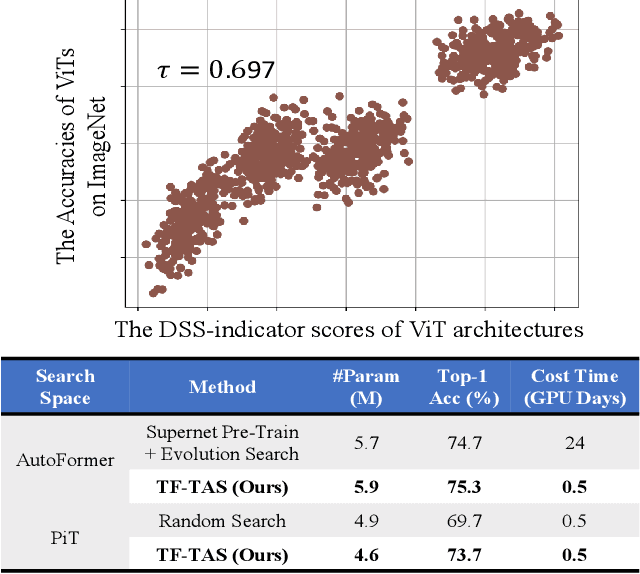
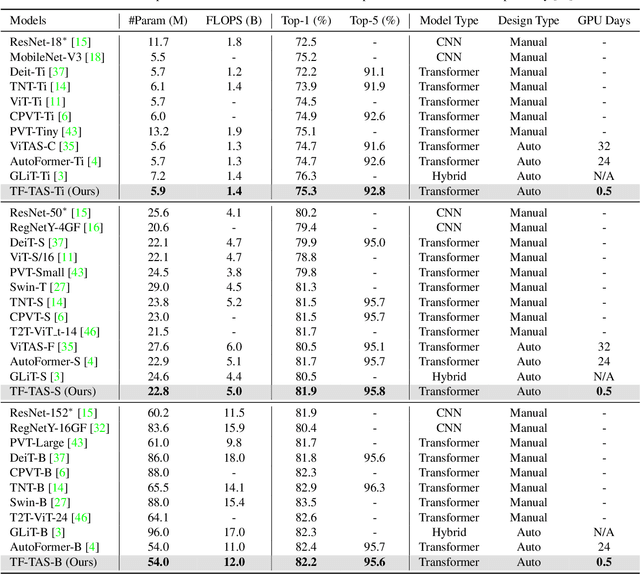
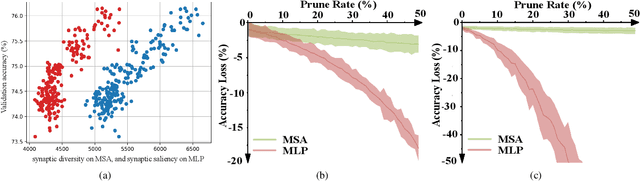
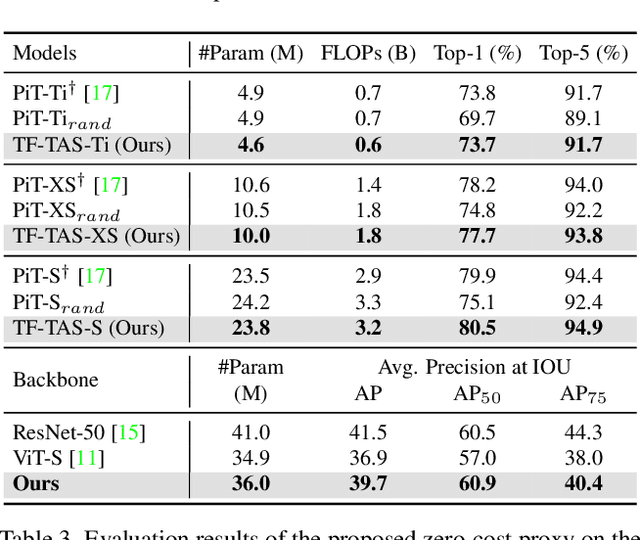
Recently, Vision Transformer (ViT) has achieved remarkable success in several computer vision tasks. The progresses are highly relevant to the architecture design, then it is worthwhile to propose Transformer Architecture Search (TAS) to search for better ViTs automatically. However, current TAS methods are time-consuming and existing zero-cost proxies in CNN do not generalize well to the ViT search space according to our experimental observations. In this paper, for the first time, we investigate how to conduct TAS in a training-free manner and devise an effective training-free TAS (TF-TAS) scheme. Firstly, we observe that the properties of multi-head self-attention (MSA) and multi-layer perceptron (MLP) in ViTs are quite different and that the synaptic diversity of MSA affects the performance notably. Secondly, based on the observation, we devise a modular strategy in TF-TAS that evaluates and ranks ViT architectures from two theoretical perspectives: synaptic diversity and synaptic saliency, termed as DSS-indicator. With DSS-indicator, evaluation results are strongly correlated with the test accuracies of ViT models. Experimental results demonstrate that our TF-TAS achieves a competitive performance against the state-of-the-art manually or automatically design ViT architectures, and it promotes the searching efficiency in ViT search space greatly: from about $24$ GPU days to less than $0.5$ GPU days. Moreover, the proposed DSS-indicator outperforms the existing cutting-edge zero-cost approaches (e.g., TE-score and NASWOT).
ARM: Any-Time Super-Resolution Method
Mar 21, 2022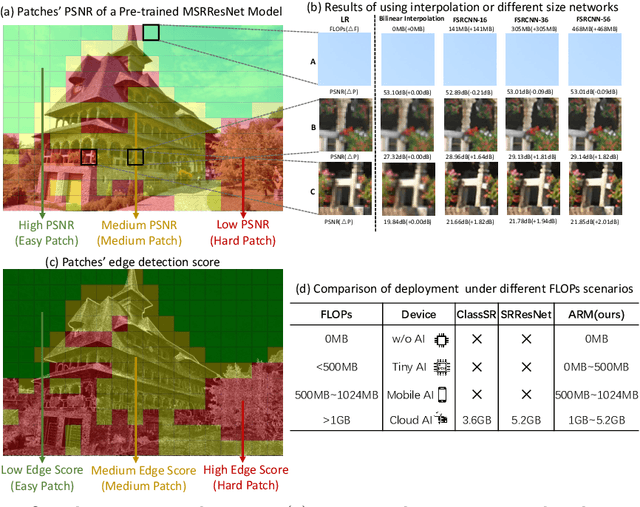
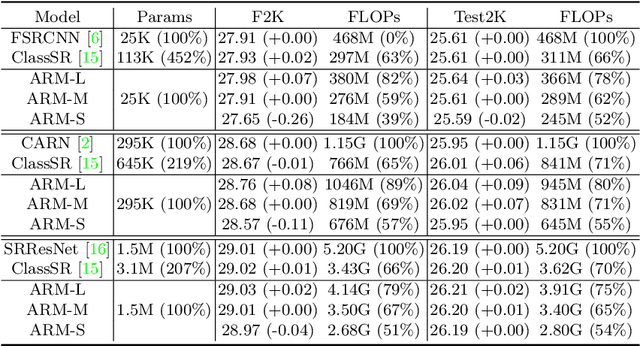

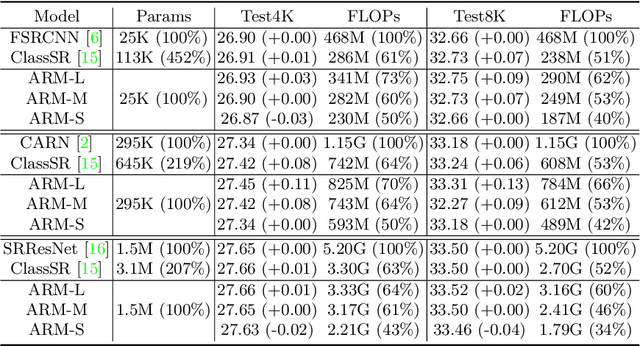
This paper proposes an Any-time super-Resolution Method (ARM) to tackle the over-parameterized single image super-resolution (SISR) models. Our ARM is motivated by three observations: (1) The performance of different image patches varies with SISR networks of different sizes. (2) There is a tradeoff between computation overhead and performance of the reconstructed image. (3) Given an input image, its edge information can be an effective option to estimate its PSNR. Subsequently, we train an ARM supernet containing SISR subnets of different sizes to deal with image patches of various complexity. To that effect, we construct an Edge-to-PSNR lookup table that maps the edge score of an image patch to the PSNR performance for each subnet, together with a set of computation costs for the subnets. In the inference, the image patches are individually distributed to different subnets for a better computation-performance tradeoff. Moreover, each SISR subnet shares weights of the ARM supernet, thus no extra parameters are introduced. The setting of multiple subnets can well adapt the computational cost of SISR model to the dynamically available hardware resources, allowing the SISR task to be in service at any time. Extensive experiments on resolution datasets of different sizes with popular SISR networks as backbones verify the effectiveness and the versatility of our ARM. The source code is available at \url{https://github.com/chenbong/ARM-Net}.
Reciprocal Normalization for Domain Adaptation
Dec 20, 2021
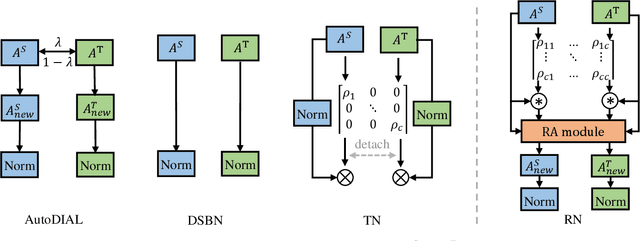
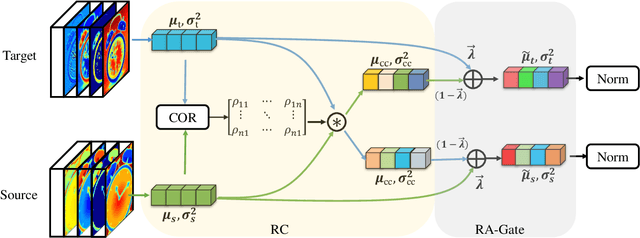
Batch normalization (BN) is widely used in modern deep neural networks, which has been shown to represent the domain-related knowledge, and thus is ineffective for cross-domain tasks like unsupervised domain adaptation (UDA). Existing BN variant methods aggregate source and target domain knowledge in the same channel in normalization module. However, the misalignment between the features of corresponding channels across domains often leads to a sub-optimal transferability. In this paper, we exploit the cross-domain relation and propose a novel normalization method, Reciprocal Normalization (RN). Specifically, RN first presents a Reciprocal Compensation (RC) module to acquire the compensatory for each channel in both domains based on the cross-domain channel-wise correlation. Then RN develops a Reciprocal Aggregation (RA) module to adaptively aggregate the feature with its cross-domain compensatory components. As an alternative to BN, RN is more suitable for UDA problems and can be easily integrated into popular domain adaptation methods. Experiments show that the proposed RN outperforms existing normalization counterparts by a large margin and helps state-of-the-art adaptation approaches achieve better results. The source code is available on https://github.com/Openning07/reciprocal-normalization-for-DA.
Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
Aug 04, 2021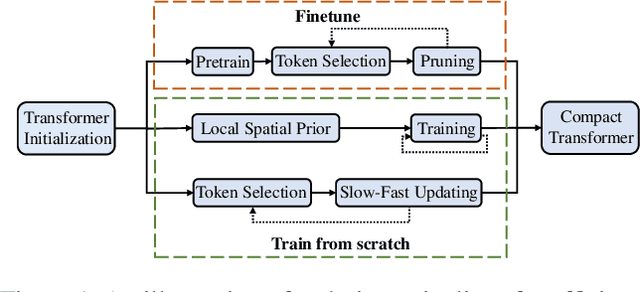
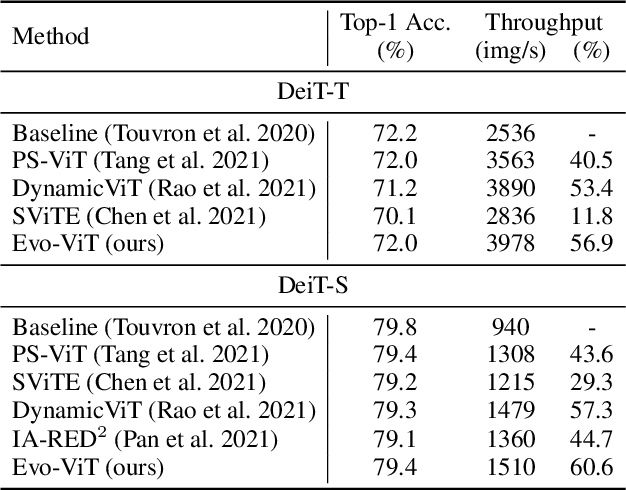
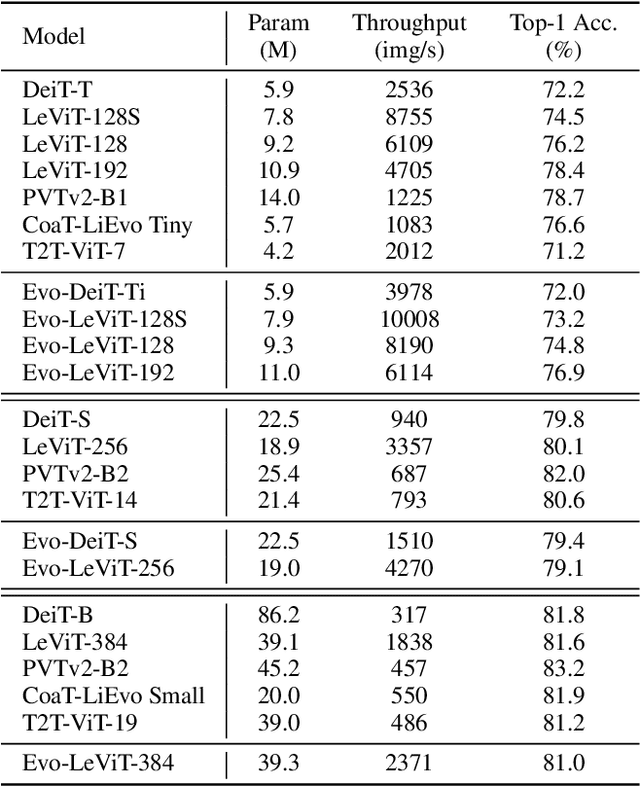
Vision transformers have recently received explosive popularity, but the huge computational cost is still a severe issue. Recent efficient designs for vision transformers follow two pipelines, namely, structural compression based on local spatial prior and non-structural token pruning. However, token pruning breaks the spatial structure that is indispensable for local spatial prior. To take advantage of both two pipelines, this work seeks to dynamically identify uninformative tokens for each instance and trim down both the training and inference complexity while maintaining complete spatial structure and information flow. To achieve this goal, we propose Evo-ViT, a self-motivated slow-fast token evolution method for vision transformers. Specifically, we conduct unstructured instance-wise token selection by taking advantage of the global class attention that is unique to vision transformers. Then, we propose to update informative tokens and placeholder tokens that contribute little to the final prediction with different computational priorities, namely, slow-fast updating. Thanks to the slow-fast updating mechanism that guarantees information flow and spatial structure, our Evo-ViT can accelerate vanilla transformers of both flat and deep-narrow structures from the very beginning of the training process. Experimental results demonstrate that the proposed method can significantly reduce the computational costs of vision transformers while maintaining comparable performance on image classification. For example, our method accelerates DeiTS by over 60% throughput while only sacrificing 0.4% top-1 accuracy.
Dual Reweighting Domain Generalization for Face Presentation Attack Detection
Jun 30, 2021
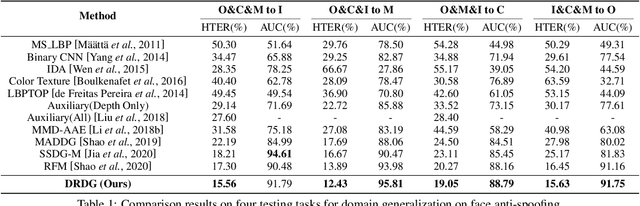
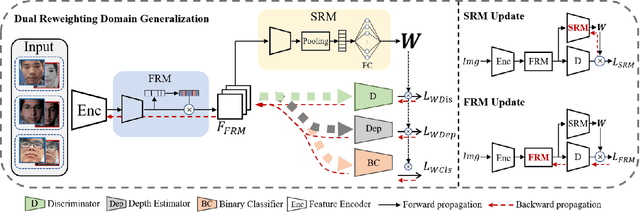
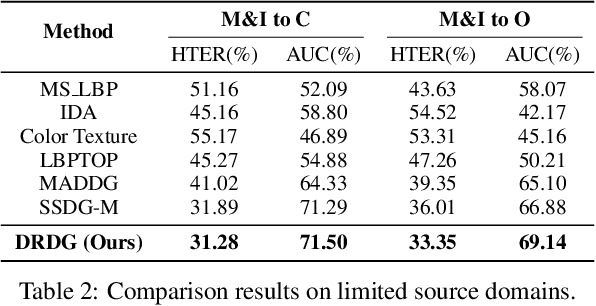
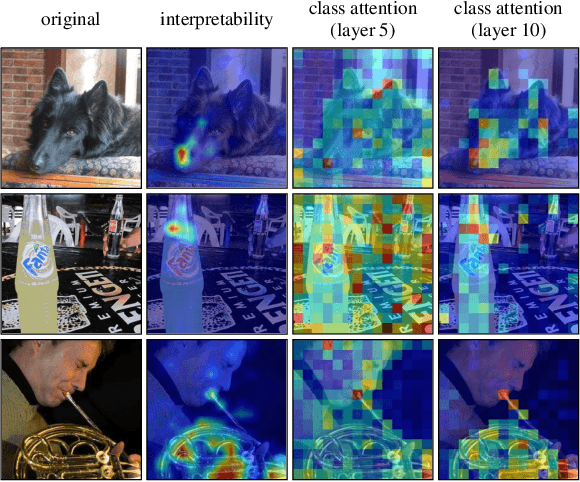
Face anti-spoofing approaches based on domain generalization (DG) have drawn growing attention due to their robustness for unseen scenarios. Previous methods treat each sample from multiple domains indiscriminately during the training process, and endeavor to extract a common feature space to improve the generalization. However, due to complex and biased data distribution, directly treating them equally will corrupt the generalization ability. To settle the issue, we propose a novel Dual Reweighting Domain Generalization (DRDG) framework which iteratively reweights the relative importance between samples to further improve the generalization. Concretely, Sample Reweighting Module is first proposed to identify samples with relatively large domain bias, and reduce their impact on the overall optimization. Afterwards, Feature Reweighting Module is introduced to focus on these samples and extract more domain-irrelevant features via a self-distilling mechanism. Combined with the domain discriminator, the iteration of the two modules promotes the extraction of generalized features. Extensive experiments and visualizations are presented to demonstrate the effectiveness and interpretability of our method against the state-of-the-art competitors.
Generalizable Representation Learning for Mixture Domain Face Anti-Spoofing
May 06, 2021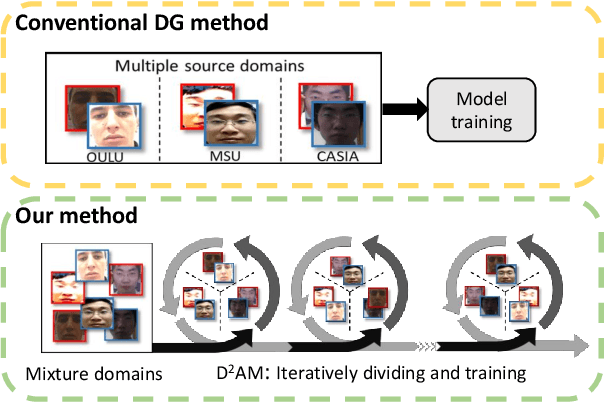
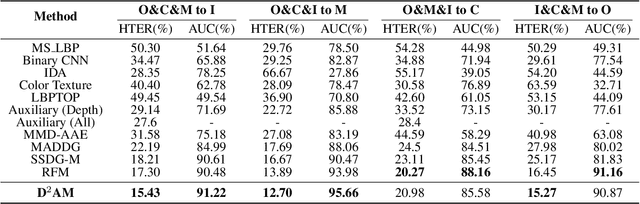
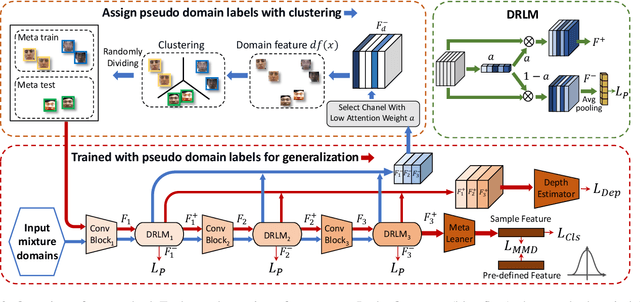
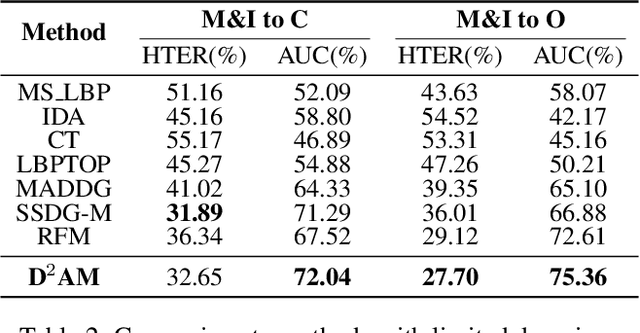
Face anti-spoofing approach based on domain generalization(DG) has drawn growing attention due to its robustness forunseen scenarios. Existing DG methods assume that the do-main label is known.However, in real-world applications, thecollected dataset always contains mixture domains, where thedomain label is unknown. In this case, most of existing meth-ods may not work. Further, even if we can obtain the domainlabel as existing methods, we think this is just a sub-optimalpartition. To overcome the limitation, we propose domain dy-namic adjustment meta-learning (D2AM) without using do-main labels, which iteratively divides mixture domains viadiscriminative domain representation and trains a generaliz-able face anti-spoofing with meta-learning. Specifically, wedesign a domain feature based on Instance Normalization(IN) and propose a domain representation learning module(DRLM) to extract discriminative domain features for cluster-ing. Moreover, to reduce the side effect of outliers on cluster-ing performance, we additionally utilize maximum mean dis-crepancy (MMD) to align the distribution of sample featuresto a prior distribution, which improves the reliability of clus tering. Extensive experiments show that the proposed methodoutperforms conventional DG-based face anti-spoofing meth-ods, including those utilizing domain labels. Furthermore, weenhance the interpretability through visualizatio
Towards Corruption-Agnostic Robust Domain Adaptation
Apr 21, 2021

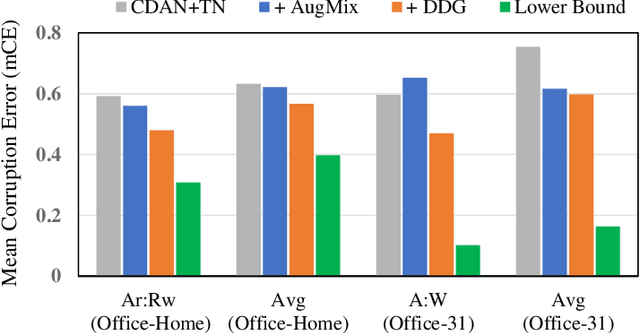
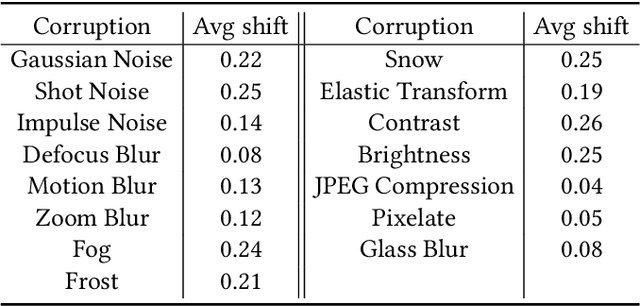
Big progress has been achieved in domain adaptation in decades. Existing works are always based on an ideal assumption that testing target domain are i.i.d. with training target domains. However, due to unpredictable corruptions (e.g., noise and blur) in real data like web images, domain adaptation methods are increasingly required to be corruption robust on target domains. In this paper, we investigate a new task, Corruption-agnostic Robust Domain Adaptation (CRDA): to be accurate on original data and robust against unavailable-for-training corruptions on target domains. This task is non-trivial due to large domain discrepancy and unsupervised target domains. We observe that simple combinations of popular methods of domain adaptation and corruption robustness have sub-optimal CRDA results. We propose a new approach based on two technical insights into CRDA: 1) an easy-to-plug module called Domain Discrepancy Generator (DDG) that generates samples that enlarge domain discrepancy to mimic unpredictable corruptions; 2) a simple but effective teacher-student scheme with contrastive loss to enhance the constraints on target domains. Experiments verify that DDG keeps or even improves performance on original data and achieves better corruption robustness that baselines.