 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Corruption-Agnostic Robust Domain Adaptation
Paper and Code


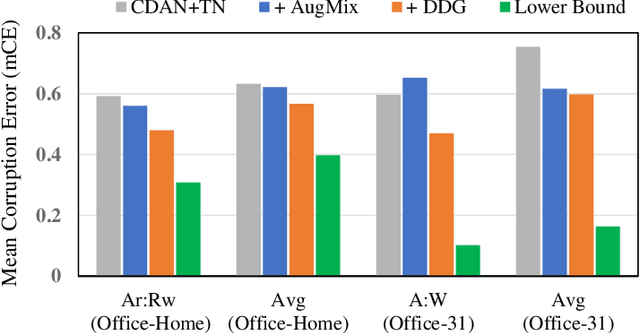
Big progress has been achieved in domain adaptation in decades. Existing works are always based on an ideal assumption that testing target domain are i.i.d. with training target domains. However, due to unpredictable corruptions (e.g., noise and blur) in real data like web images, domain adaptation methods are increasingly required to be corruption robust on target domains. In this paper, we investigate a new task, Corruption-agnostic Robust Domain Adaptation (CRDA): to be accurate on original data and robust against unavailable-for-training corruptions on target domains. This task is non-trivial due to large domain discrepancy and unsupervised target domains. We observe that simple combinations of popular methods of domain adaptation and corruption robustness have sub-optimal CRDA results. We propose a new approach based on two technical insights into CRDA: 1) an easy-to-plug module called Domain Discrepancy Generator (DDG) that generates samples that enlarge domain discrepancy to mimic unpredictable corruptions; 2) a simple but effective teacher-student scheme with contrastive loss to enhance the constraints on target domains. Experiments verify that DDG keeps or even improves performance on original data and achieves better corruption robustness that baselines.