 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Corruption-Agnostic Robust Domain Adaptation
Apr 21, 2021

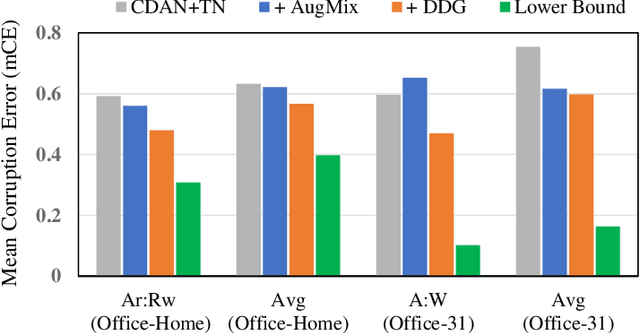
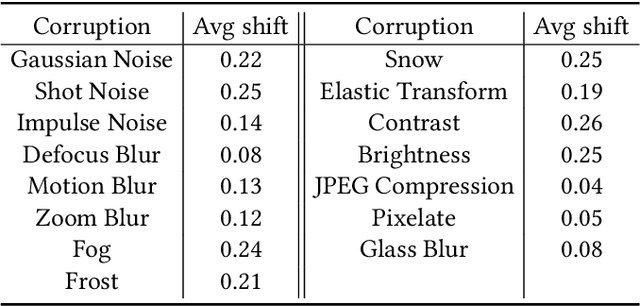
Big progress has been achieved in domain adaptation in decades. Existing works are always based on an ideal assumption that testing target domain are i.i.d. with training target domains. However, due to unpredictable corruptions (e.g., noise and blur) in real data like web images, domain adaptation methods are increasingly required to be corruption robust on target domains. In this paper, we investigate a new task, Corruption-agnostic Robust Domain Adaptation (CRDA): to be accurate on original data and robust against unavailable-for-training corruptions on target domains. This task is non-trivial due to large domain discrepancy and unsupervised target domains. We observe that simple combinations of popular methods of domain adaptation and corruption robustness have sub-optimal CRDA results. We propose a new approach based on two technical insights into CRDA: 1) an easy-to-plug module called Domain Discrepancy Generator (DDG) that generates samples that enlarge domain discrepancy to mimic unpredictable corruptions; 2) a simple but effective teacher-student scheme with contrastive loss to enhance the constraints on target domains. Experiments verify that DDG keeps or even improves performance on original data and achieves better corruption robustness that baselines.
A design of human-like robust AI machines in object identification
Jan 07, 2021
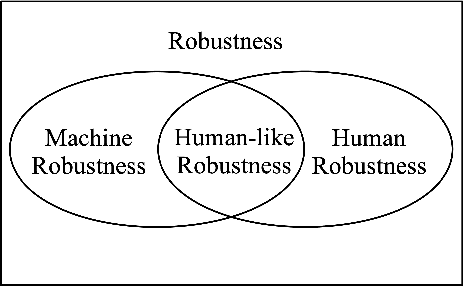
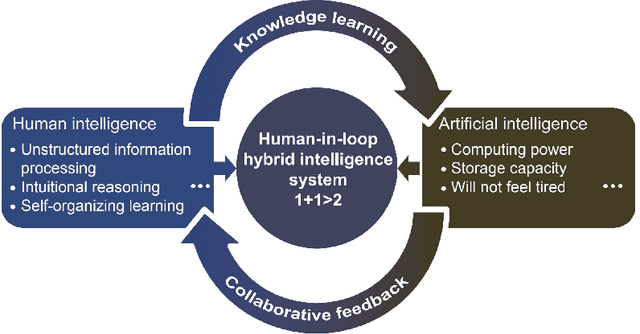
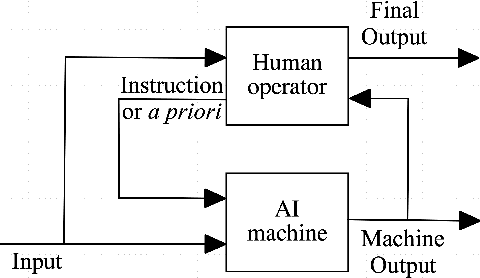
This is a perspective paper inspired from the study of Turing Test proposed by A.M. Turing (23 June 1912 - 7 June 1954) in 1950. Following one important implication of Turing Test for enabling a machine with a human-like behavior or performance, we define human-like robustness (HLR) for AI machines. The objective of the new definition aims to enforce AI machines with HLR, including to evaluate them in terms of HLR. A specific task is discussed only on object identification, because it is the most common task for every person in daily life. Similar to the perspective, or design, position by Turing, we provide a solution of how to achieve HLR AI machines without constructing them and conducting real experiments. The solution should consists of three important features in the machines. The first feature of HLR machines is to utilize common sense from humans for realizing a causal inference. The second feature is to make a decision from a semantic space for having interpretations to the decision. The third feature is to include a "human-in-the-loop" setting for advancing HLR machines. We show an "identification game" using proposed design of HLR machines. The present paper shows an attempt to learn and explore further from Turing Test towards the design of human-like AI machines.
Generalized Constraints as A New Mathematical Problem in Artificial Intelligence: A Review and Perspective
Nov 12, 2020

In this comprehensive review, we describe a new mathematical problem in artificial intelligence (AI) from a mathematical modeling perspective, following the philosophy stated by Rudolf E. Kalman that "Once you get the physics right, the rest is mathematics". The new problem is called "Generalized Constraints (GCs)", and we adopt GCs as a general term to describe any type of prior information in modelings. To understand better about GCs to be a general problem, we compare them with the conventional constraints (CCs) and list their extra challenges over CCs. In the construction of AI machines, we basically encounter more often GCs for modeling, rather than CCs with well-defined forms. Furthermore, we discuss the ultimate goals of AI and redefine transparent, interpretable, and explainable AI in terms of comprehension levels about machines. We review the studies in relation to the GC problems although most of them do not take the notion of GCs. We demonstrate that if AI machines are simplified by a coupling with both knowledge-driven submodel and data-driven submodel, GCs will play a critical role in a knowledge-driven submodel as well as in the coupling form between the two submodels. Examples are given to show that the studies in view of a generalized constraint problem will help us perceive and explore novel subjects in AI, or even in mathematics, such as generalized constraint learning (GCL).
Revisiting Image Aesthetic Assessment via Self-Supervised Feature Learning
Nov 26, 2019
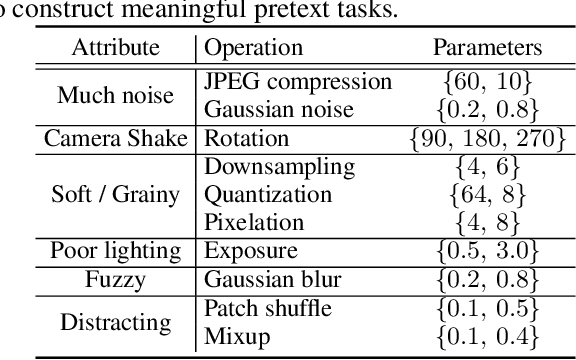

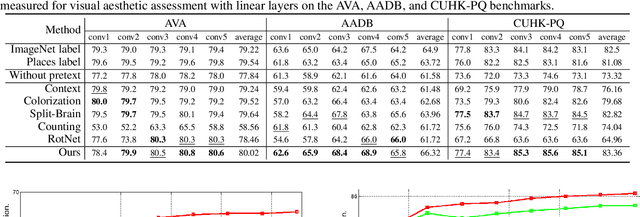
Visual aesthetic assessment has been an active research field for decades. Although latest methods have achieved promising performance on benchmark datasets, they typically rely on a large number of manual annotations including both aesthetic labels and related image attributes. In this paper, we revisit the problem of image aesthetic assessment from the self-supervised feature learning perspective. Our motivation is that a suitable feature representation for image aesthetic assessment should be able to distinguish different expert-designed image manipulations, which have close relationships with negative aesthetic effects. To this end, we design two novel pretext tasks to identify the types and parameters of editing operations applied to synthetic instances. The features from our pretext tasks are then adapted for a one-layer linear classifier to evaluate the performance in terms of binary aesthetic classification. We conduct extensive quantitative experiments on three benchmark datasets and demonstrate that our approach can faithfully extract aesthetics-aware features and outperform alternative pretext schemes. Moreover, we achieve comparable results to state-of-the-art supervised methods that use 10 million labels from ImageNet.
Incremental Concept Learning via Online Generative Memory Recall
Jul 05, 2019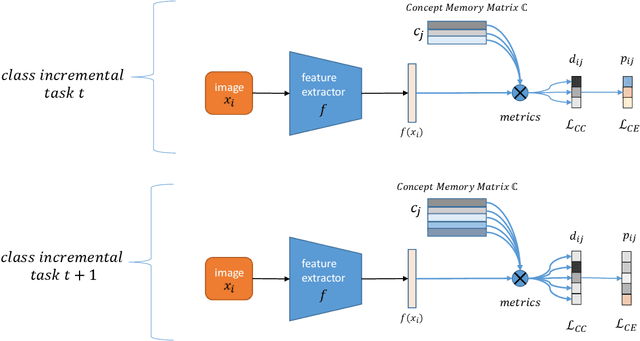
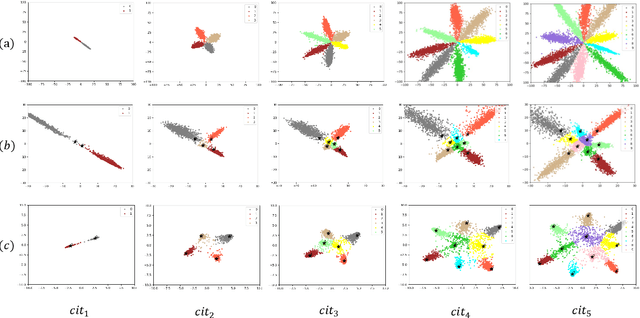
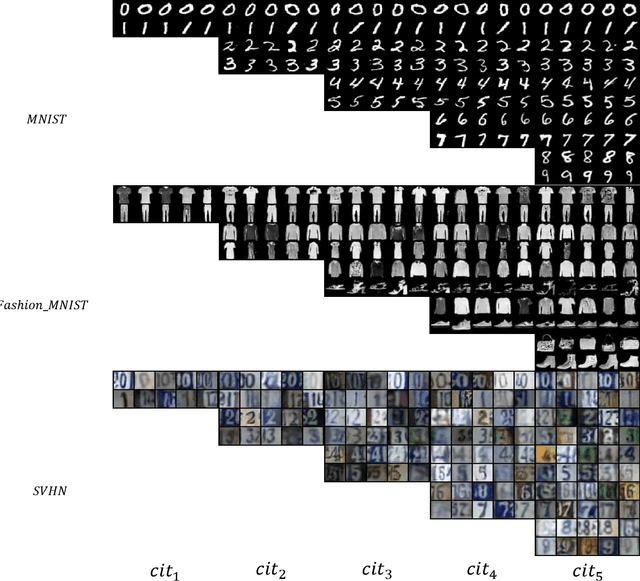
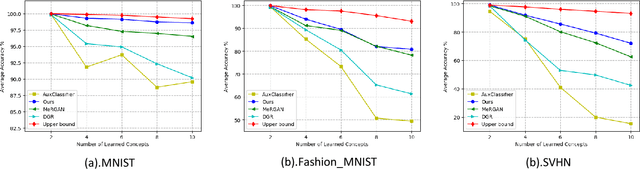
The ability to learn more and more concepts over time from incrementally arriving data is essential for the development of a life-long learning system. However, deep neural networks often suffer from forgetting previously learned concepts when continually learning new concepts, which is known as catastrophic forgetting problem. The main reason for catastrophic forgetting is that the past concept data is not available and neural weights are changed during incrementally learning new concepts. In this paper, we propose a pseudo-rehearsal based class incremental learning approach to make neural networks capable of continually learning new concepts. We use a conditional generative adversarial network to consolidate old concepts memory and recall pseudo samples during learning new concepts and a balanced online memory recall strategy is to maximally maintain old memories. And we design a comprehensible incremental concept learning network as well as a concept contrastive loss to alleviate the magnitude of neural weights change. We evaluate the proposed approach on MNIST, Fashion-MNIST and SVHN datasets and compare with other rehearsal based approaches. The extensive experiments demonstrate the effectiveness of our approach.
LGM-Net: Learning to Generate Matching Networks for Few-Shot Learning
May 15, 2019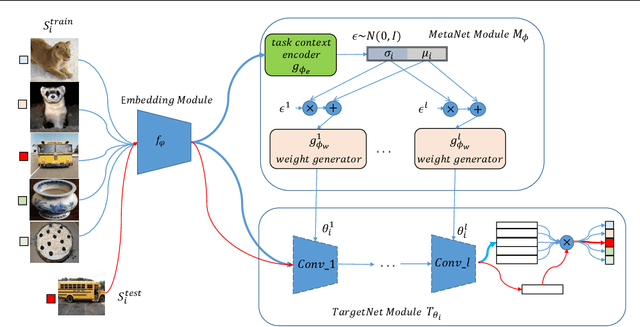
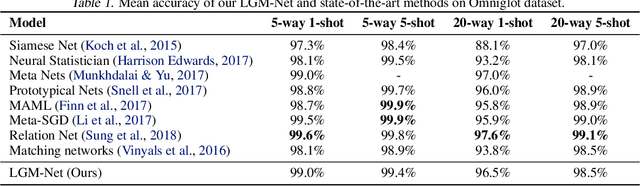
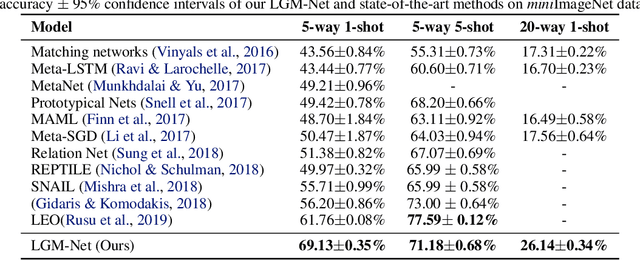
In this work, we propose a novel meta-learning approach for few-shot classification, which learns transferable prior knowledge across tasks and directly produces network parameters for similar unseen tasks with training samples. Our approach, called LGM-Net, includes two key modules, namely, TargetNet and MetaNet. The TargetNet module is a neural network for solving a specific task and the MetaNet module aims at learning to generate functional weights for TargetNet by observing training samples. We also present an intertask normalization strategy for the training process to leverage common information shared across different tasks. The experimental results on Omniglot and miniImageNet datasets demonstrate that LGM-Net can effectively adapt to similar unseen tasks and achieve competitive performance, and the results on synthetic datasets show that transferable prior knowledge is learned by the MetaNet module via mapping training data to functional weights. LGM-Net enables fast learning and adaptation since no further tuning steps are required compared to other meta-learning approaches.
Learning with Average Top-k Loss
Dec 20, 2017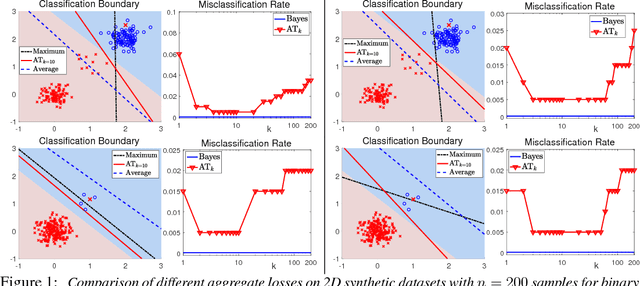
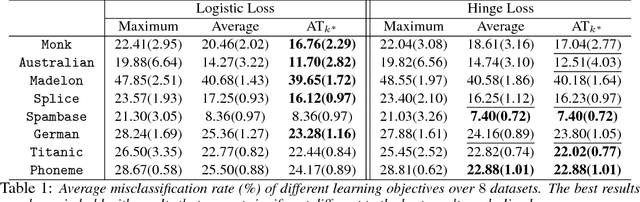
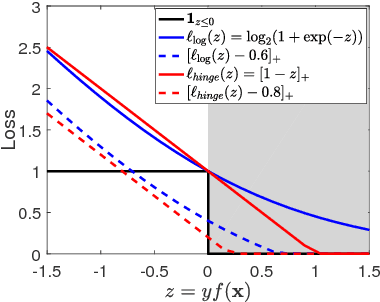
In this work, we introduce the {\em average top-$k$} (\atk) loss as a new aggregate loss for supervised learning, which is the average over the $k$ largest individual losses over a training dataset. We show that the \atk loss is a natural generalization of the two widely used aggregate losses, namely the average loss and the maximum loss, but can combine their advantages and mitigate their drawbacks to better adapt to different data distributions. Furthermore, it remains a convex function over all individual losses, which can lead to convex optimization problems that can be solved effectively with conventional gradient-based methods. We provide an intuitive interpretation of the \atk loss based on its equivalent effect on the continuous individual loss functions, suggesting that it can reduce the penalty on correctly classified data. We further give a learning theory analysis of \matk learning on the classification calibration of the \atk loss and the error bounds of \atk-SVM. We demonstrate the applicability of minimum average top-$k$ learning for binary classification and regression using synthetic and real datasets.
Robust Localized Multi-view Subspace Clustering
May 22, 2017
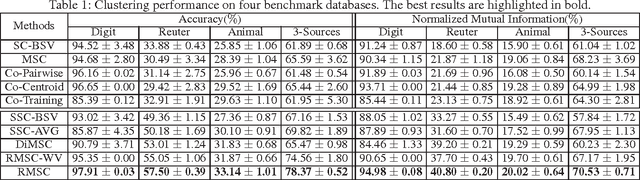
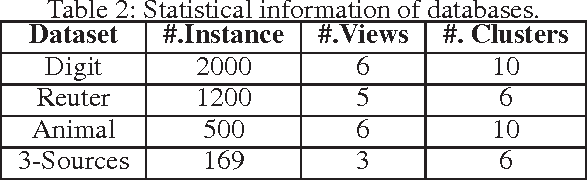

In multi-view clustering, different views may have different confidence levels when learning a consensus representation. Existing methods usually address this by assigning distinctive weights to different views. However, due to noisy nature of real-world applications, the confidence levels of samples in the same view may also vary. Thus considering a unified weight for a view may lead to suboptimal solutions. In this paper, we propose a novel localized multi-view subspace clustering model that considers the confidence levels of both views and samples. By assigning weight to each sample under each view properly, we can obtain a robust consensus representation via fusing the noiseless structures among views and samples. We further develop a regularizer on weight parameters based on the convex conjugacy theory, and samples weights are determined in an adaptive manner. An efficient iterative algorithm is developed with a convergence guarantee. Experimental results on four benchmarks demonstrate the correctness and effectiveness of the proposed model.
Self-Paced Learning: an Implicit Regularization Perspective
Sep 18, 2016
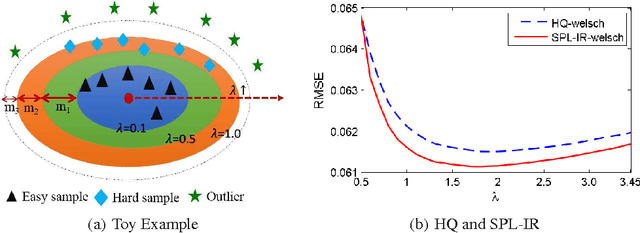
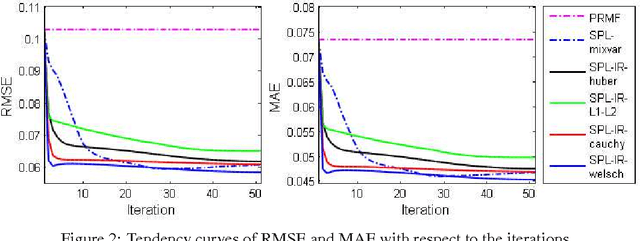

Self-paced learning (SPL) mimics the cognitive mechanism of humans and animals that gradually learns from easy to hard samples. One key issue in SPL is to obtain better weighting strategy that is determined by minimizer function. Existing methods usually pursue this by artificially designing the explicit form of SPL regularizer. In this paper, we focus on the minimizer function, and study a group of new regularizer, named self-paced implicit regularizer that is deduced from robust loss function. Based on the convex conjugacy theory, the minimizer function for self-paced implicit regularizer can be directly learned from the latent loss function, while the analytic form of the regularizer can be even known. A general framework (named SPL-IR) for SPL is developed accordingly. We demonstrate that the learning procedure of SPL-IR is associated with latent robust loss functions, thus can provide some theoretical inspirations for its working mechanism. We further analyze the relation between SPL-IR and half-quadratic optimization. Finally, we implement SPL-IR to both supervised and unsupervised tasks, and experimental results corroborate our ideas and demonstrate the correctness and effectiveness of implicit regularizers.
Locally Imposing Function for Generalized Constraint Neural Networks - A Study on Equality Constraints
Apr 18, 2016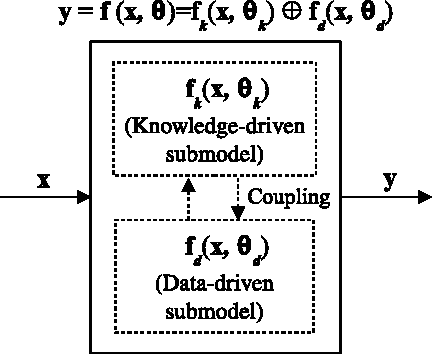
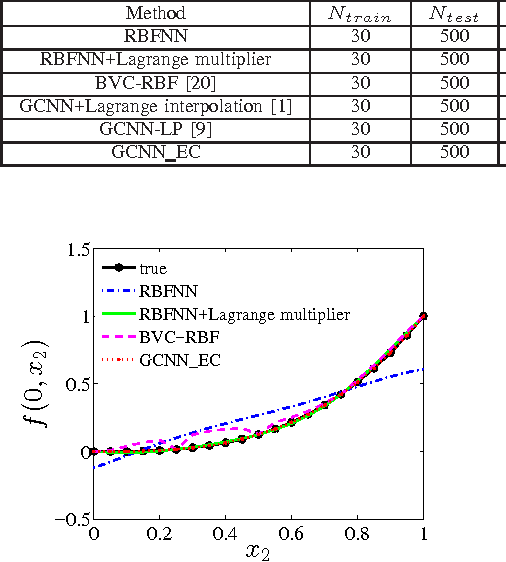

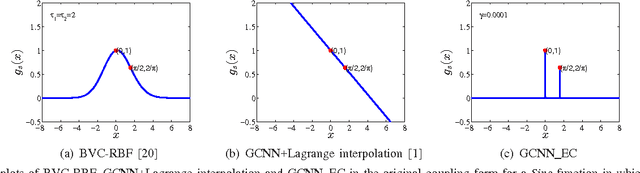
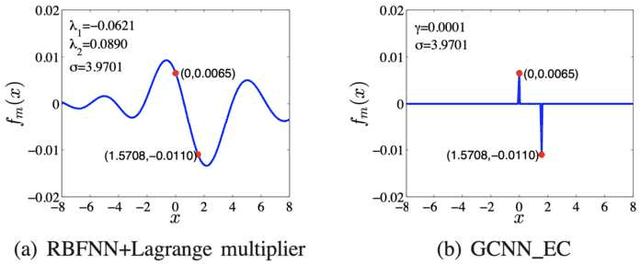
This work is a further study on the Generalized Constraint Neural Network (GCNN) model [1], [2]. Two challenges are encountered in the study, that is, to embed any type of prior information and to select its imposing schemes. The work focuses on the second challenge and studies a new constraint imposing scheme for equality constraints. A new method called locally imposing function (LIF) is proposed to provide a local correction to the GCNN prediction function, which therefore falls within Locally Imposing Scheme (LIS). In comparison, the conventional Lagrange multiplier method is considered as Globally Imposing Scheme (GIS) because its added constraint term exhibits a global impact to its objective function. Two advantages are gained from LIS over GIS. First, LIS enables constraints to fire locally and explicitly in the domain only where they need on the prediction function. Second, constraints can be implemented within a network setting directly. We attempt to interpret several constraint methods graphically from a viewpoint of the locality principle. Numerical examples confirm the advantages of the proposed method. In solving boundary value problems with Dirichlet and Neumann constraints, the GCNN model with LIF is possible to achieve an exact satisfaction of the constraints.