 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSissi: Zero-shot Style-guided Image Synthesis via Semantic-style Integration
Jan 10, 2026Text-guided image generation has advanced rapidly with large-scale diffusion models, yet achieving precise stylization with visual exemplars remains difficult. Existing approaches often depend on task-specific retraining or expensive inversion procedures, which can compromise content integrity, reduce style fidelity, and lead to an unsatisfactory trade-off between semantic prompt adherence and style alignment. In this work, we introduce a training-free framework that reformulates style-guided synthesis as an in-context learning task. Guided by textual semantic prompts, our method concatenates a reference style image with a masked target image, leveraging a pretrained ReFlow-based inpainting model to seamlessly integrate semantic content with the desired style through multimodal attention fusion. We further analyze the imbalance and noise sensitivity inherent in multimodal attention fusion and propose a Dynamic Semantic-Style Integration (DSSI) mechanism that reweights attention between textual semantic and style visual tokens, effectively resolving guidance conflicts and enhancing output coherence. Experiments show that our approach achieves high-fidelity stylization with superior semantic-style balance and visual quality, offering a simple yet powerful alternative to complex, artifact-prone prior methods.
TourPlanner: A Competitive Consensus Framework with Constraint-Gated Reinforcement Learning for Travel Planning
Jan 08, 2026Travel planning is a sophisticated decision-making process that requires synthesizing multifaceted information to construct itineraries. However, existing travel planning approaches face several challenges: (1) Pruning candidate points of interest (POIs) while maintaining a high recall rate; (2) A single reasoning path restricts the exploration capability within the feasible solution space for travel planning; (3) Simultaneously optimizing hard constraints and soft constraints remains a significant difficulty. To address these challenges, we propose TourPlanner, a comprehensive framework featuring multi-path reasoning and constraint-gated reinforcement learning. Specifically, we first introduce a Personalized Recall and Spatial Optimization (PReSO) workflow to construct spatially-aware candidate POIs' set. Subsequently, we propose Competitive consensus Chain-of-Thought (CCoT), a multi-path reasoning paradigm that improves the ability of exploring the feasible solution space. To further refine the plan, we integrate a sigmoid-based gating mechanism into the reinforcement learning stage, which dynamically prioritizes soft-constraint satisfaction only after hard constraints are met. Experimental results on travel planning benchmarks demonstrate that TourPlanner achieves state-of-the-art performance, significantly surpassing existing methods in both feasibility and user-preference alignment.
LiveStar: Live Streaming Assistant for Real-World Online Video Understanding
Nov 07, 2025Despite significant progress in Video Large Language Models (Video-LLMs) for offline video understanding, existing online Video-LLMs typically struggle to simultaneously process continuous frame-by-frame inputs and determine optimal response timing, often compromising real-time responsiveness and narrative coherence. To address these limitations, we introduce LiveStar, a pioneering live streaming assistant that achieves always-on proactive responses through adaptive streaming decoding. Specifically, LiveStar incorporates: (1) a training strategy enabling incremental video-language alignment for variable-length video streams, preserving temporal consistency across dynamically evolving frame sequences; (2) a response-silence decoding framework that determines optimal proactive response timing via a single forward pass verification; (3) memory-aware acceleration via peak-end memory compression for online inference on 10+ minute videos, combined with streaming key-value cache to achieve 1.53x faster inference. We also construct an OmniStar dataset, a comprehensive dataset for training and benchmarking that encompasses 15 diverse real-world scenarios and 5 evaluation tasks for online video understanding. Extensive experiments across three benchmarks demonstrate LiveStar's state-of-the-art performance, achieving an average 19.5% improvement in semantic correctness with 18.1% reduced timing difference compared to existing online Video-LLMs, while improving FPS by 12.0% across all five OmniStar tasks. Our model and dataset can be accessed at https://github.com/yzy-bupt/LiveStar.
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation
Jun 05, 2025In recent years, Multimodal Large Language Models (MLLMs) have been extensively utilized for multimodal reasoning tasks, including Graphical User Interface (GUI) automation. Unlike general offline multimodal tasks, GUI automation is executed in online interactive environments, necessitating step-by-step decision-making based on real-time status of the environment. This task has a lower tolerance for decision-making errors at each step, as any mistakes may cumulatively disrupt the process and potentially lead to irreversible outcomes like deletions or payments. To address these issues, we introduce a pre-operative critic mechanism that provides effective feedback prior to the actual execution, by reasoning about the potential outcome and correctness of actions. Specifically, we propose a Suggestion-aware Gradient Relative Policy Optimization (S-GRPO) strategy to construct our pre-operative critic model GUI-Critic-R1, incorporating a novel suggestion reward to enhance the reliability of the model's feedback. Furthermore, we develop a reasoning-bootstrapping based data collection pipeline to create a GUI-Critic-Train and a GUI-Critic-Test, filling existing gaps in GUI critic data. Static experiments on the GUI-Critic-Test across both mobile and web domains reveal that our GUI-Critic-R1 offers significant advantages in critic accuracy compared to current MLLMs. Dynamic evaluation on GUI automation benchmark further highlights the effectiveness and superiority of our model, as evidenced by improved success rates and operational efficiency.
Multi-turn Consistent Image Editing
May 07, 2025Many real-world applications, such as interactive photo retouching, artistic content creation, and product design, require flexible and iterative image editing. However, existing image editing methods primarily focus on achieving the desired modifications in a single step, which often struggles with ambiguous user intent, complex transformations, or the need for progressive refinements. As a result, these methods frequently produce inconsistent outcomes or fail to meet user expectations. To address these challenges, we propose a multi-turn image editing framework that enables users to iteratively refine their edits, progressively achieving more satisfactory results. Our approach leverages flow matching for accurate image inversion and a dual-objective Linear Quadratic Regulators (LQR) for stable sampling, effectively mitigating error accumulation. Additionally, by analyzing the layer-wise roles of transformers, we introduce a adaptive attention highlighting method that enhances editability while preserving multi-turn coherence. Extensive experiments demonstrate that our framework significantly improves edit success rates and visual fidelity compared to existing methods.
A Survey on Cross-Modal Interaction Between Music and Multimodal Data
Apr 17, 2025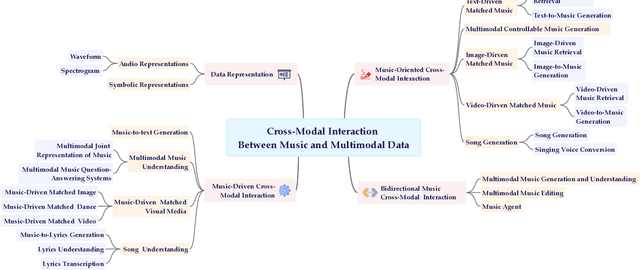
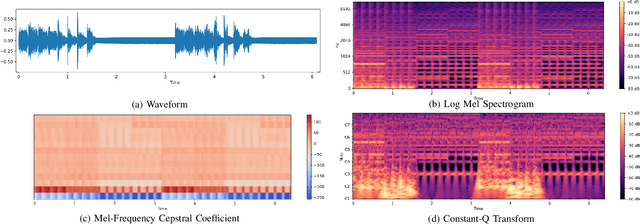

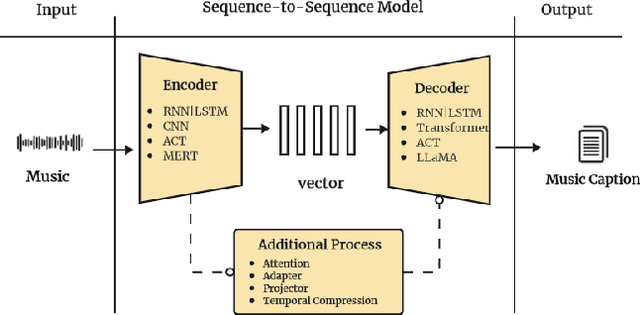
Multimodal learning has driven innovation across various industries, particularly in the field of music. By enabling more intuitive interaction experiences and enhancing immersion, it not only lowers the entry barriers to the music but also increases its overall appeal. This survey aims to provide a comprehensive review of multimodal tasks related to music, outlining how music contributes to multimodal learning and offering insights for researchers seeking to expand the boundaries of computational music. Unlike text and images, which are often semantically or visually intuitive, music primarily interacts with humans through auditory perception, making its data representation inherently less intuitive. Therefore, this paper first introduces the representations of music and provides an overview of music datasets. Subsequently, we categorize cross-modal interactions between music and multimodal data into three types: music-driven cross-modal interactions, music-oriented cross-modal interactions, and bidirectional music cross-modal interactions. For each category, we systematically trace the development of relevant sub-tasks, analyze existing limitations, and discuss emerging trends. Furthermore, we provide a comprehensive summary of datasets and evaluation metrics used in multimodal tasks related to music, offering benchmark references for future research. Finally, we discuss the current challenges in cross-modal interactions involving music and propose potential directions for future research.
Z-Magic: Zero-shot Multiple Attributes Guided Image Creator
Mar 15, 2025The customization of multiple attributes has gained popularity with the rising demand for personalized content creation. Despite promising empirical results, the contextual coherence between different attributes has been largely overlooked. In this paper, we argue that subsequent attributes should follow the multivariable conditional distribution introduced by former attribute creation. In light of this, we reformulate multi-attribute creation from a conditional probability theory perspective and tackle the challenging zero-shot setting. By explicitly modeling the dependencies between attributes, we further enhance the coherence of generated images across diverse attribute combinations. Furthermore, we identify connections between multi-attribute customization and multi-task learning, effectively addressing the high computing cost encountered in multi-attribute synthesis. Extensive experiments demonstrate that Z-Magic outperforms existing models in zero-shot image generation, with broad implications for AI-driven design and creative applications.
Bringing Characters to New Stories: Training-Free Theme-Specific Image Generation via Dynamic Visual Prompting
Jan 26, 2025



The stories and characters that captivate us as we grow up shape unique fantasy worlds, with images serving as the primary medium for visually experiencing these realms. Personalizing generative models through fine-tuning with theme-specific data has become a prevalent approach in text-to-image generation. However, unlike object customization, which focuses on learning specific objects, theme-specific generation encompasses diverse elements such as characters, scenes, and objects. Such diversity also introduces a key challenge: how to adaptively generate multi-character, multi-concept, and continuous theme-specific images (TSI). Moreover, fine-tuning approaches often come with significant computational overhead, time costs, and risks of overfitting. This paper explores a fundamental question: Can image generation models directly leverage images as contextual input, similarly to how large language models use text as context? To address this, we present T-Prompter, a novel training-free TSI method for generation. T-Prompter introduces visual prompting, a mechanism that integrates reference images into generative models, allowing users to seamlessly specify the target theme without requiring additional training. To further enhance this process, we propose a Dynamic Visual Prompting (DVP) mechanism, which iteratively optimizes visual prompts to improve the accuracy and quality of generated images. Our approach enables diverse applications, including consistent story generation, character design, realistic character generation, and style-guided image generation. Comparative evaluations against state-of-the-art personalization methods demonstrate that T-Prompter achieves significantly better results and excels in maintaining character identity preserving, style consistency and text alignment, offering a robust and flexible solution for theme-specific image generation.
VidMusician: Video-to-Music Generation with Semantic-Rhythmic Alignment via Hierarchical Visual Features
Dec 09, 2024Video-to-music generation presents significant potential in video production, requiring the generated music to be both semantically and rhythmically aligned with the video. Achieving this alignment demands advanced music generation capabilities, sophisticated video understanding, and an efficient mechanism to learn the correspondence between the two modalities. In this paper, we propose VidMusician, a parameter-efficient video-to-music generation framework built upon text-to-music models. VidMusician leverages hierarchical visual features to ensure semantic and rhythmic alignment between video and music. Specifically, our approach utilizes global visual features as semantic conditions and local visual features as rhythmic cues. These features are integrated into the generative backbone via cross-attention and in-attention mechanisms, respectively. Through a two-stage training process, we incrementally incorporate semantic and rhythmic features, utilizing zero initialization and identity initialization to maintain the inherent music-generative capabilities of the backbone. Additionally, we construct a diverse video-music dataset, DVMSet, encompassing various scenarios, such as promo videos, commercials, and compilations. Experiments demonstrate that VidMusician outperforms state-of-the-art methods across multiple evaluation metrics and exhibits robust performance on AI-generated videos. Samples are available at \url{https://youtu.be/EPOSXwtl1jw}.
Z-STAR+: A Zero-shot Style Transfer Method via Adjusting Style Distribution
Nov 28, 2024



Style transfer presents a significant challenge, primarily centered on identifying an appropriate style representation. Conventional methods employ style loss, derived from second-order statistics or contrastive learning, to constrain style representation in the stylized result. However, these pre-defined style representations often limit stylistic expression, leading to artifacts. In contrast to existing approaches, we have discovered that latent features in vanilla diffusion models inherently contain natural style and content distributions. This allows for direct extraction of style information and seamless integration of generative priors into the content image without necessitating retraining. Our method adopts dual denoising paths to represent content and style references in latent space, subsequently guiding the content image denoising process with style latent codes. We introduce a Cross-attention Reweighting module that utilizes local content features to query style image information best suited to the input patch, thereby aligning the style distribution of the stylized results with that of the style image. Furthermore, we design a scaled adaptive instance normalization to mitigate inconsistencies in color distribution between style and stylized images on a global scale. Through theoretical analysis and extensive experimentation, we demonstrate the effectiveness and superiority of our diffusion-based \uline{z}ero-shot \uline{s}tyle \uline{t}ransfer via \uline{a}djusting style dist\uline{r}ibution, termed Z-STAR+.