 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeow-Omni 1: A Multimodal Large Language Model for Feline Ethology
May 09, 2026Deciphering animal intent is a fundamental challenge in computational ethology, largely because of semantic aliasing, the phenomenon where identical external signals (e.g., a cat's purr) correspond to radically different internal states depending on physiological context. Existing Multimodal Large Language Models (MLLMs) are blind to high-frequency biological time-series data, restricting them to superficial behavioural pattern matching rather than genuine latent-state reasoning. To bridge this gap, we introduce Meow-Omni 1, the first open-source, quad-modal MLLM purpose-built for computational ethology. It natively fuses video, audio, and physiological time-series streams with textual reasoning. Through targeted architectural adaptation, we integrate specialized scientific encoders into a unified backbone and formalize intent inference via physiologically grounded cross-modal alignment. Evaluated on MeowBench, a novel, expert-verified quad-modal benchmark, Meow-Omni 1 achieves state-of-the-art intent-recognition accuracy (71.16%), substantially outperforming leading vision-language and omni-modal baselines. We release the complete open-source pipeline including model weights, training framework, and the Meow-10K dataset, to establish a scalable paradigm for inter-species intent understanding and to advance foundation models toward real-world veterinary diagnostics and wildlife conservation.
A Survey on Cross-Modal Interaction Between Music and Multimodal Data
Apr 17, 2025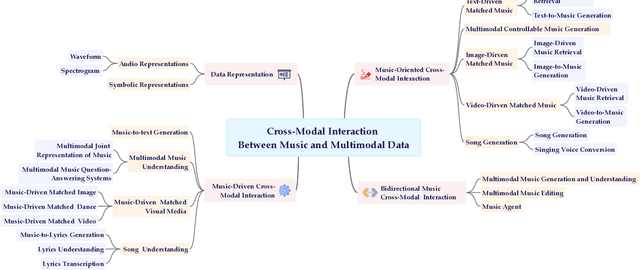
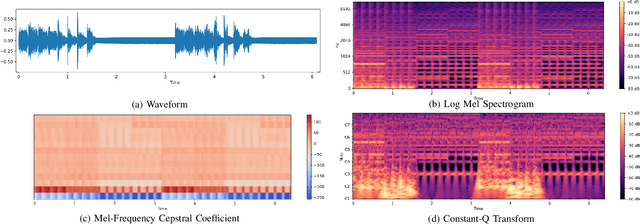

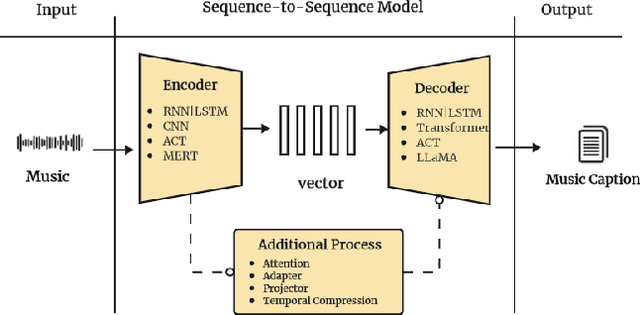
Multimodal learning has driven innovation across various industries, particularly in the field of music. By enabling more intuitive interaction experiences and enhancing immersion, it not only lowers the entry barriers to the music but also increases its overall appeal. This survey aims to provide a comprehensive review of multimodal tasks related to music, outlining how music contributes to multimodal learning and offering insights for researchers seeking to expand the boundaries of computational music. Unlike text and images, which are often semantically or visually intuitive, music primarily interacts with humans through auditory perception, making its data representation inherently less intuitive. Therefore, this paper first introduces the representations of music and provides an overview of music datasets. Subsequently, we categorize cross-modal interactions between music and multimodal data into three types: music-driven cross-modal interactions, music-oriented cross-modal interactions, and bidirectional music cross-modal interactions. For each category, we systematically trace the development of relevant sub-tasks, analyze existing limitations, and discuss emerging trends. Furthermore, we provide a comprehensive summary of datasets and evaluation metrics used in multimodal tasks related to music, offering benchmark references for future research. Finally, we discuss the current challenges in cross-modal interactions involving music and propose potential directions for future research.
VidMusician: Video-to-Music Generation with Semantic-Rhythmic Alignment via Hierarchical Visual Features
Dec 09, 2024Video-to-music generation presents significant potential in video production, requiring the generated music to be both semantically and rhythmically aligned with the video. Achieving this alignment demands advanced music generation capabilities, sophisticated video understanding, and an efficient mechanism to learn the correspondence between the two modalities. In this paper, we propose VidMusician, a parameter-efficient video-to-music generation framework built upon text-to-music models. VidMusician leverages hierarchical visual features to ensure semantic and rhythmic alignment between video and music. Specifically, our approach utilizes global visual features as semantic conditions and local visual features as rhythmic cues. These features are integrated into the generative backbone via cross-attention and in-attention mechanisms, respectively. Through a two-stage training process, we incrementally incorporate semantic and rhythmic features, utilizing zero initialization and identity initialization to maintain the inherent music-generative capabilities of the backbone. Additionally, we construct a diverse video-music dataset, DVMSet, encompassing various scenarios, such as promo videos, commercials, and compilations. Experiments demonstrate that VidMusician outperforms state-of-the-art methods across multiple evaluation metrics and exhibits robust performance on AI-generated videos. Samples are available at \url{https://youtu.be/EPOSXwtl1jw}.
Music Style Transfer with Time-Varying Inversion of Diffusion Models
Feb 21, 2024With the development of diffusion models, text-guided image style transfer has demonstrated high-quality controllable synthesis results. However, the utilization of text for diverse music style transfer poses significant challenges, primarily due to the limited availability of matched audio-text datasets. Music, being an abstract and complex art form, exhibits variations and intricacies even within the same genre, thereby making accurate textual descriptions challenging. This paper presents a music style transfer approach that effectively captures musical attributes using minimal data. We introduce a novel time-varying textual inversion module to precisely capture mel-spectrogram features at different levels. During inference, we propose a bias-reduced stylization technique to obtain stable results. Experimental results demonstrate that our method can transfer the style of specific instruments, as well as incorporate natural sounds to compose melodies. Samples and source code are available at https://lsfhuihuiff.github.io/MusicTI/.
Dance-to-Music Generation with Encoder-based Textual Inversion of Diffusion Models
Jan 31, 2024



The harmonious integration of music with dance movements is pivotal in vividly conveying the artistic essence of dance. This alignment also significantly elevates the immersive quality of gaming experiences and animation productions. While there has been remarkable advancement in creating high-fidelity music from textual descriptions, current methodologies mainly concentrate on modulating overarching characteristics such as genre and emotional tone. They often overlook the nuanced management of temporal rhythm, which is indispensable in crafting music for dance, since it intricately aligns the musical beats with the dancers' movements. Recognizing this gap, we propose an encoder-based textual inversion technique for augmenting text-to-music models with visual control, facilitating personalized music generation. Specifically, we develop dual-path rhythm-genre inversion to effectively integrate the rhythm and genre of a dance motion sequence into the textual space of a text-to-music model. Contrary to the classical textual inversion method, which directly updates text embeddings to reconstruct a single target object, our approach utilizes separate rhythm and genre encoders to obtain text embeddings for two pseudo-words, adapting to the varying rhythms and genres. To achieve a more accurate evaluation, we propose improved evaluation metrics for rhythm alignment. We demonstrate that our approach outperforms state-of-the-art methods across multiple evaluation metrics. Furthermore, our method seamlessly adapts to in-the-wild data and effectively integrates with the inherent text-guided generation capability of the pre-trained model. Samples are available at \url{https://youtu.be/D7XDwtH1YwE}.