 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRM: Diffusion-based Reward Model With Step-wise Guidance
May 25, 2026Current mainstream methods of aligning diffusion models with human preferences typically employ VLM-based reward models. However, these reward models, pre-trained for semantic alignment, struggle to capture the essential perceptual qualities-such as aesthetics, composition, and visual harmony. In this work, we argue that a model capable of high-fidelity generation must possess a profound understanding of these visual attributes. Based on this insight, we introduce the Diffusion-based Reward Model (DRM), a novel paradigm that use the pre-trained diffusion model as a powerful evaluative backbone. A key advantage of the DRM is its unique ability to assess not only the final image but also the noisy intermediate latents at any stage of the generative process. We leverage this step-wise evaluative capacity in two ways. First, we propose Step-wise GRPO, a reinforcement learning algorithm that provides dense, per-step rewards to resolve the imprecise credit assignment problem in GRPO algorithm, leading to more stable and effective alignment. Second, we introduce Step-wise Sampling, a novel inference strategy that employs the DRM as a dynamic guide to evaluate multiple generation paths at each step, steering the process towards higher-quality outcomes. Extensive experiments confirm that our approach significantly enhances the final quality of generated images. Code: https://github.com/jjaxonx/DRM.
VersusQ: Pairwise Margin Reasoning for Generalizable Video Quality Assessment
May 20, 2026Large Multimodal Models (LMMs) have shown promise for video quality assessment, but most methods still predict an absolute score for each video. Such pointwise supervision often mixes perceptual quality with dataset-specific calibration, including annotation protocols, rating habits, and score distributions. As a result, the learned scoring rule may work well within a benchmark but transfer poorly across unseen domains. We argue that relative comparisons alleviate the absolute-scale calibration bias by focusing purely on perceptual differences rather than dataset-specific rating habits. Consequently, we propose \textbf{VersusQ}, a pairwise margin reasoning framework driven entirely by direct comparisons. Specifically, VersusQ performs LMM-based comparison between two videos, reasons about their visual and temporal quality differences, and predicts a signed continuous margin that captures both the preferred choice and the degree of difference. Furthermore, to align interpretable comparison rationales with fine-grained numerical differences, we introduce Margin-Coupled GRPO, which jointly optimizes rollout-based relational reasoning and continuous margin regression. Extensive experiments on multiple public VQA benchmarks demonstrate that VersusQ achieves state-of-the-art performance, strong cross-domain generalization, and reliable fine-grained ranking under heterogeneous evaluation scenarios.
OmniHuman: A Large-scale Dataset and Benchmark for Human-Centric Video Generation
Apr 20, 2026Recent advancements in audio-video joint generation models have demonstrated impressive capabilities in content creation. However, generating high-fidelity human-centric videos in complex, real-world physical scenes remains a significant challenge. We identify that the root cause lies in the structural deficiencies of existing datasets across three dimensions: limited global scene and camera diversity, sparse interaction modeling (both person-person and person-object), and insufficient individual attribute alignment. To bridge these gaps, we present OmniHuman, a large-scale, multi-scene dataset designed for fine-grained human modeling. OmniHuman provides a hierarchical annotation covering video-level scenes, frame-level interactions, and individual-level attributes. To facilitate this, we develop a fully automated pipeline for high-quality data collection and multi-modal annotation. Complementary to the dataset, we establish the OmniHuman Benchmark (OHBench), a three-level evaluation system that provides a scientific diagnosis for human-centric audio-video synthesis. Crucially, OHBench introduces metrics that are highly consistent with human perception, filling the gaps in existing benchmarks by providing a comprehensive diagnosis across global scenes, relational interactions, and individual attributes.
Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing
Apr 12, 2026Recent progress in multimodal models has spurred rapid advances in audio understanding, generation, and editing. However, these capabilities are typically addressed by specialized models, leaving the development of a truly unified framework that can seamlessly integrate all three tasks underexplored. While some pioneering works have explored unifying audio understanding and generation, they often remain confined to specific domains. To address this, we introduce Audio-Omni, the first end-to-end framework to unify generation and editing across general sound, music, and speech domains, with integrated multi-modal understanding capabilities. Our architecture synergizes a frozen Multimodal Large Language Model for high-level reasoning with a trainable Diffusion Transformer for high-fidelity synthesis. To overcome the critical data scarcity in audio editing, we construct AudioEdit, a new large-scale dataset comprising over one million meticulously curated editing pairs. Extensive experiments demonstrate that Audio-Omni achieves state-of-the-art performance across a suite of benchmarks, outperforming prior unified approaches while achieving performance on par with or superior to specialized expert models. Beyond its core capabilities, Audio-Omni exhibits remarkable inherited capabilities, including knowledge-augmented reasoning generation, in-context generation, and zero-shot cross-lingual control for audio generation, highlighting a promising direction toward universal generative audio intelligence. The code, model, and dataset will be publicly released on https://zeyuet.github.io/Audio-Omni.
NOVA: Sparse Control, Dense Synthesis for Pair-Free Video Editing
Mar 03, 2026Recent video editing models have achieved impressive results, but most still require large-scale paired datasets. Collecting such naturally aligned pairs at scale remains highly challenging and constitutes a critical bottleneck, especially for local video editing data. Existing workarounds transfer image editing to video through global motion control for pair-free video editing, but such designs struggle with background and temporal consistency. In this paper, we propose NOVA: Sparse Control \& Dense Synthesis, a new framework for unpaired video editing. Specifically, the sparse branch provides semantic guidance through user-edited keyframes distributed across the video, and the dense branch continuously incorporates motion and texture information from the original video to maintain high fidelity and coherence. Moreover, we introduce a degradation-simulation training strategy that enables the model to learn motion reconstruction and temporal consistency by training on artificially degraded videos, thus eliminating the need for paired data. Our extensive experiments demonstrate that NOVA outperforms existing approaches in edit fidelity, motion preservation, and temporal coherence.
StableWorld: Towards Stable and Consistent Long Interactive Video Generation
Jan 21, 2026In this paper, we explore the overlooked challenge of stability and temporal consistency in interactive video generation, which synthesizes dynamic and controllable video worlds through interactive behaviors such as camera movements and text prompts. Despite remarkable progress in world modeling, current methods still suffer from severe instability and temporal degradation, often leading to spatial drift and scene collapse during long-horizon interactions. To better understand this issue, we initially investigate the underlying causes of instability and identify that the major source of error accumulation originates from the same scene, where generated frames gradually deviate from the initial clean state and propagate errors to subsequent frames. Building upon this observation, we propose a simple yet effective method, \textbf{StableWorld}, a Dynamic Frame Eviction Mechanism. By continuously filtering out degraded frames while retaining geometrically consistent ones, StableWorld effectively prevents cumulative drift at its source, leading to more stable and temporal consistency of interactive generation. Promising results on multiple interactive video models, \eg, Matrix-Game, Open-Oasis, and Hunyuan-GameCraft, demonstrate that StableWorld is model-agnostic and can be applied to different interactive video generation frameworks to substantially improve stability, temporal consistency, and generalization across diverse interactive scenarios.
Video-GPT via Next Clip Diffusion
May 18, 2025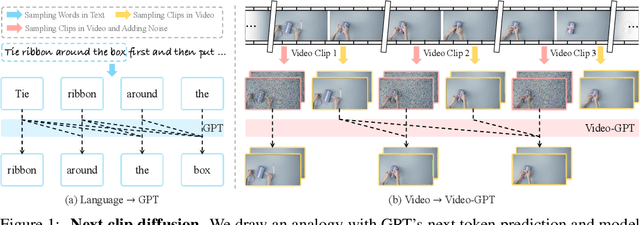
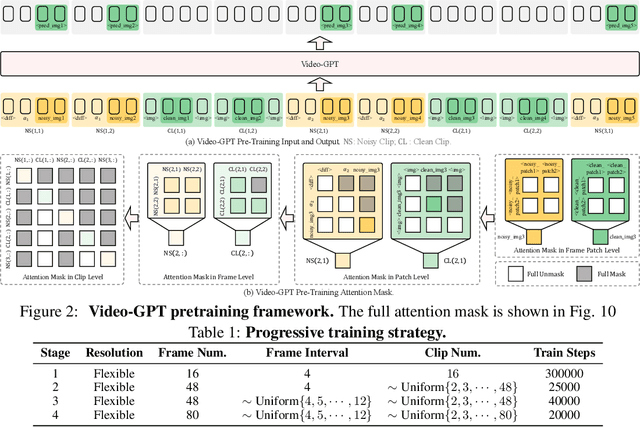
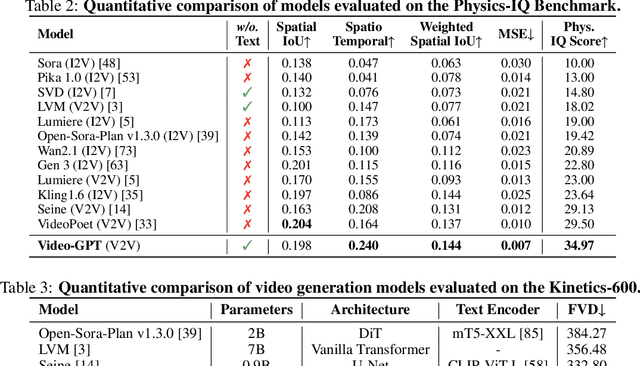
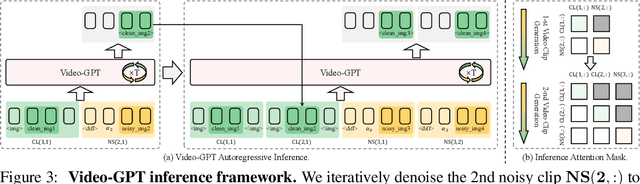
GPT has shown its remarkable success in natural language processing. However, the language sequence is not sufficient to describe spatial-temporal details in the visual world. Alternatively, the video sequence is good at capturing such details. Motivated by this fact, we propose a concise Video-GPT in this paper by treating video as new language for visual world modeling. By analogy to next token prediction in GPT, we introduce a novel next clip diffusion paradigm for pretraining Video-GPT. Different from the previous works, this distinct paradigm allows Video-GPT to tackle both short-term generation and long-term prediction, by autoregressively denoising the noisy clip according to the clean clips in the history. Extensive experiments show our Video-GPT achieves the state-of-the-art performance on video prediction, which is the key factor towards world modeling (Physics-IQ Benchmark: Video-GPT 34.97 vs. Kling 23.64 vs. Wan 20.89). Moreover, it can be well adapted on 6 mainstream video tasks in both video generation and understanding, showing its great generalization capacity in downstream. The project page is at https://Video-GPT.github.io.
Get In Video: Add Anything You Want to the Video
Mar 08, 2025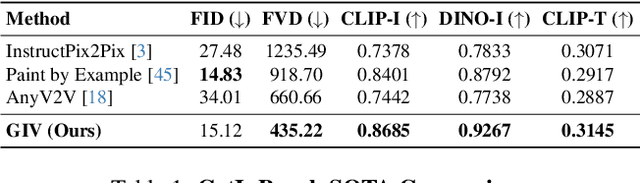
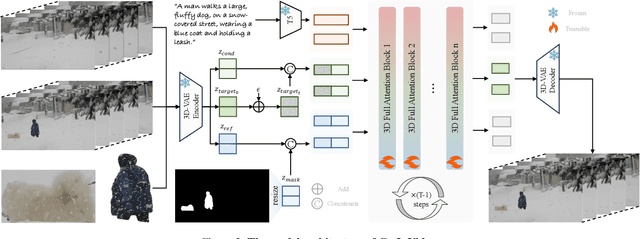


Video editing increasingly demands the ability to incorporate specific real-world instances into existing footage, yet current approaches fundamentally fail to capture the unique visual characteristics of particular subjects and ensure natural instance/scene interactions. We formalize this overlooked yet critical editing paradigm as "Get-In-Video Editing", where users provide reference images to precisely specify visual elements they wish to incorporate into videos. Addressing this task's dual challenges, severe training data scarcity and technical challenges in maintaining spatiotemporal coherence, we introduce three key contributions. First, we develop GetIn-1M dataset created through our automated Recognize-Track-Erase pipeline, which sequentially performs video captioning, salient instance identification, object detection, temporal tracking, and instance removal to generate high-quality video editing pairs with comprehensive annotations (reference image, tracking mask, instance prompt). Second, we present GetInVideo, a novel end-to-end framework that leverages a diffusion transformer architecture with 3D full attention to process reference images, condition videos, and masks simultaneously, maintaining temporal coherence, preserving visual identity, and ensuring natural scene interactions when integrating reference objects into videos. Finally, we establish GetInBench, the first comprehensive benchmark for Get-In-Video Editing scenario, demonstrating our approach's superior performance through extensive evaluations. Our work enables accessible, high-quality incorporation of specific real-world subjects into videos, significantly advancing personalized video editing capabilities.
WeGen: A Unified Model for Interactive Multimodal Generation as We Chat
Mar 03, 2025Existing multimodal generative models fall short as qualified design copilots, as they often struggle to generate imaginative outputs once instructions are less detailed or lack the ability to maintain consistency with the provided references. In this work, we introduce WeGen, a model that unifies multimodal generation and understanding, and promotes their interplay in iterative generation. It can generate diverse results with high creativity for less detailed instructions. And it can progressively refine prior generation results or integrating specific contents from references following the instructions in its chat with users. During this process, it is capable of preserving consistency in the parts that the user is already satisfied with. To this end, we curate a large-scale dataset, extracted from Internet videos, containing rich object dynamics and auto-labeled dynamics descriptions by advanced foundation models to date. These two information are interleaved into a single sequence to enable WeGen to learn consistency-aware generation where the specified dynamics are generated while the consistency of unspecified content is preserved aligned with instructions. Besides, we introduce a prompt self-rewriting mechanism to enhance generation diversity. Extensive experiments demonstrate the effectiveness of unifying multimodal understanding and generation in WeGen and show it achieves state-of-the-art performance across various visual generation benchmarks. These also demonstrate the potential of WeGen as a user-friendly design copilot as desired. The code and models will be available at https://github.com/hzphzp/WeGen.
VidMusician: Video-to-Music Generation with Semantic-Rhythmic Alignment via Hierarchical Visual Features
Dec 09, 2024Video-to-music generation presents significant potential in video production, requiring the generated music to be both semantically and rhythmically aligned with the video. Achieving this alignment demands advanced music generation capabilities, sophisticated video understanding, and an efficient mechanism to learn the correspondence between the two modalities. In this paper, we propose VidMusician, a parameter-efficient video-to-music generation framework built upon text-to-music models. VidMusician leverages hierarchical visual features to ensure semantic and rhythmic alignment between video and music. Specifically, our approach utilizes global visual features as semantic conditions and local visual features as rhythmic cues. These features are integrated into the generative backbone via cross-attention and in-attention mechanisms, respectively. Through a two-stage training process, we incrementally incorporate semantic and rhythmic features, utilizing zero initialization and identity initialization to maintain the inherent music-generative capabilities of the backbone. Additionally, we construct a diverse video-music dataset, DVMSet, encompassing various scenarios, such as promo videos, commercials, and compilations. Experiments demonstrate that VidMusician outperforms state-of-the-art methods across multiple evaluation metrics and exhibits robust performance on AI-generated videos. Samples are available at \url{https://youtu.be/EPOSXwtl1jw}.