 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation
Dec 17, 2022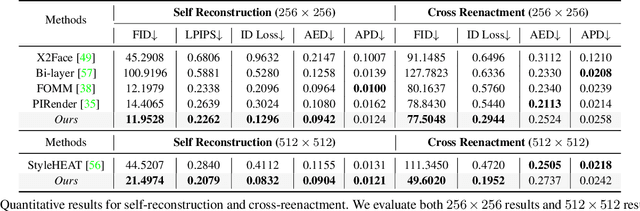
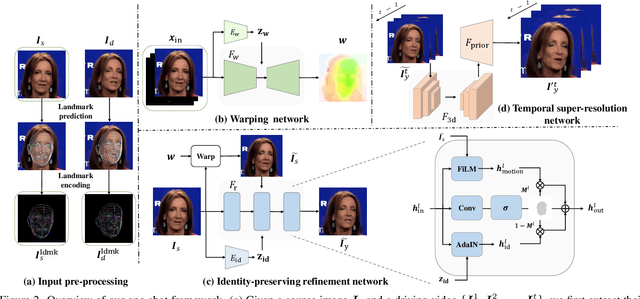
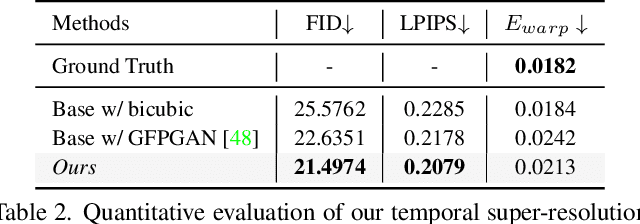
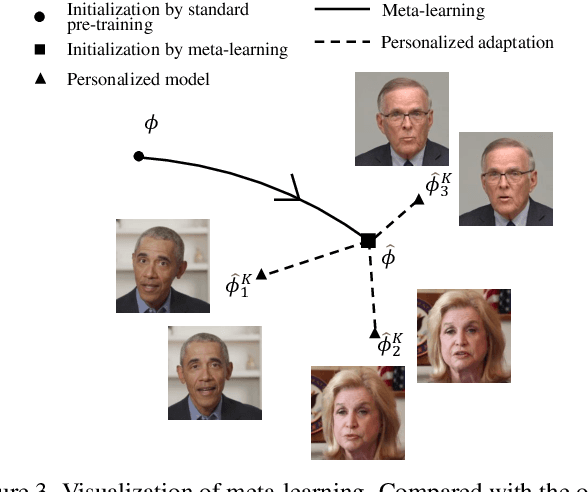
In this work, we propose an ID-preserving talking head generation framework, which advances previous methods in two aspects. First, as opposed to interpolating from sparse flow, we claim that dense landmarks are crucial to achieving accurate geometry-aware flow fields. Second, inspired by face-swapping methods, we adaptively fuse the source identity during synthesis, so that the network better preserves the key characteristics of the image portrait. Although the proposed model surpasses prior generation fidelity on established benchmarks, to further make the talking head generation qualified for real usage, personalized fine-tuning is usually needed. However, this process is rather computationally demanding that is unaffordable to standard users. To solve this, we propose a fast adaptation model using a meta-learning approach. The learned model can be adapted to a high-quality personalized model as fast as 30 seconds. Last but not the least, a spatial-temporal enhancement module is proposed to improve the fine details while ensuring temporal coherency. Extensive experiments prove the significant superiority of our approach over the state of the arts in both one-shot and personalized settings.
CLIP Itself is a Strong Fine-tuner: Achieving 85.7% and 88.0% Top-1 Accuracy with ViT-B and ViT-L on ImageNet
Dec 12, 2022



Recent studies have shown that CLIP has achieved remarkable success in performing zero-shot inference while its fine-tuning performance is not satisfactory. In this paper, we identify that fine-tuning performance is significantly impacted by hyper-parameter choices. We examine various key hyper-parameters and empirically evaluate their impact in fine-tuning CLIP for classification tasks through a comprehensive study. We find that the fine-tuning performance of CLIP is substantially underestimated. Equipped with hyper-parameter refinement, we demonstrate CLIP itself is better or at least competitive in fine-tuning compared with large-scale supervised pre-training approaches or latest works that use CLIP as prediction targets in Masked Image Modeling. Specifically, CLIP ViT-Base/16 and CLIP ViT-Large/14 can achieve 85.7%,88.0% finetuning Top-1 accuracy on the ImageNet-1K dataset . These observations challenge the conventional conclusion that CLIP is not suitable for fine-tuning, and motivate us to rethink recently proposed improvements based on CLIP. We will release our code publicly at \url{https://github.com/LightDXY/FT-CLIP}.
Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
Dec 12, 2022



This paper presents a 3D generative model that uses diffusion models to automatically generate 3D digital avatars represented as neural radiance fields. A significant challenge in generating such avatars is that the memory and processing costs in 3D are prohibitive for producing the rich details required for high-quality avatars. To tackle this problem we propose the roll-out diffusion network (Rodin), which represents a neural radiance field as multiple 2D feature maps and rolls out these maps into a single 2D feature plane within which we perform 3D-aware diffusion. The Rodin model brings the much-needed computational efficiency while preserving the integrity of diffusion in 3D by using 3D-aware convolution that attends to projected features in the 2D feature plane according to their original relationship in 3D. We also use latent conditioning to orchestrate the feature generation for global coherence, leading to high-fidelity avatars and enabling their semantic editing based on text prompts. Finally, we use hierarchical synthesis to further enhance details. The 3D avatars generated by our model compare favorably with those produced by existing generative techniques. We can generate highly detailed avatars with realistic hairstyles and facial hair like beards. We also demonstrate 3D avatar generation from image or text as well as text-guided editability.
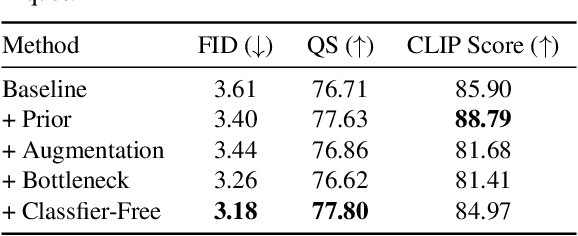
X-Paste: Revisit Copy-Paste at Scale with CLIP and StableDiffusion
Dec 07, 2022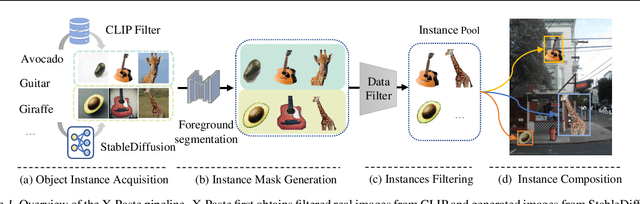



Copy-Paste is a simple and effective data augmentation strategy for instance segmentation. By randomly pasting object instances onto new background images, it creates new training data for free and significantly boosts the segmentation performance, especially for rare object categories. Although diverse, high-quality object instances used in Copy-Paste result in more performance gain, previous works utilize object instances either from human-annotated instance segmentation datasets or rendered from 3D object models, and both approaches are too expensive to scale up to obtain good diversity. In this paper, we revisit Copy-Paste at scale with the power of newly emerged zero-shot recognition models (e.g., CLIP) and text2image models (e.g., StableDiffusion). We demonstrate for the first time that using a text2image model to generate images or zero-shot recognition model to filter noisily crawled images for different object categories is a feasible way to make Copy-Paste truly scalable. To make such success happen, we design a data acquisition and processing framework, dubbed "X-Paste", upon which a systematic study is conducted. On the LVIS dataset, X-Paste provides impressive improvements over the strong baseline CenterNet2 with Swin-L as the backbone. Specifically, it archives +2.6 box AP and +2.1 mask AP gains on all classes and even more significant gains with +6.8 box AP +6.5 mask AP on long-tail classes.
Paint by Example: Exemplar-based Image Editing with Diffusion Models
Nov 23, 2022


Language-guided image editing has achieved great success recently. In this paper, for the first time, we investigate exemplar-guided image editing for more precise control. We achieve this goal by leveraging self-supervised training to disentangle and re-organize the source image and the exemplar. However, the naive approach will cause obvious fusing artifacts. We carefully analyze it and propose an information bottleneck and strong augmentations to avoid the trivial solution of directly copying and pasting the exemplar image. Meanwhile, to ensure the controllability of the editing process, we design an arbitrary shape mask for the exemplar image and leverage the classifier-free guidance to increase the similarity to the exemplar image. The whole framework involves a single forward of the diffusion model without any iterative optimization. We demonstrate that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity.
Explicitly Controllable 3D-Aware Portrait Generation
Sep 20, 2022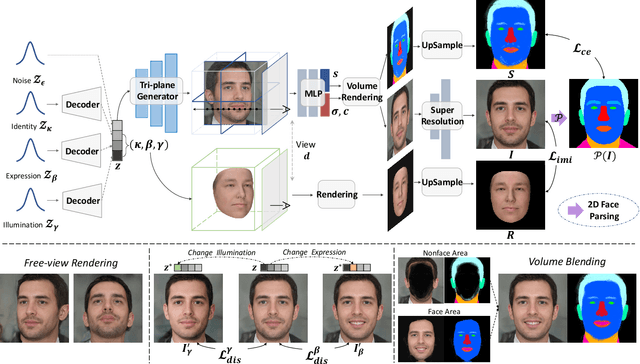
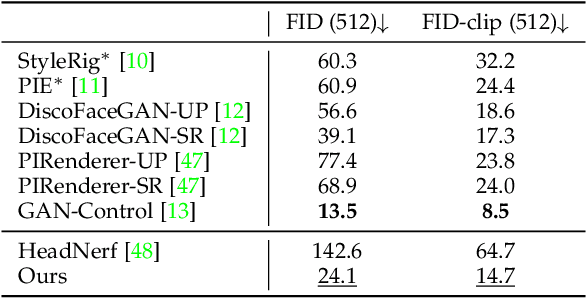
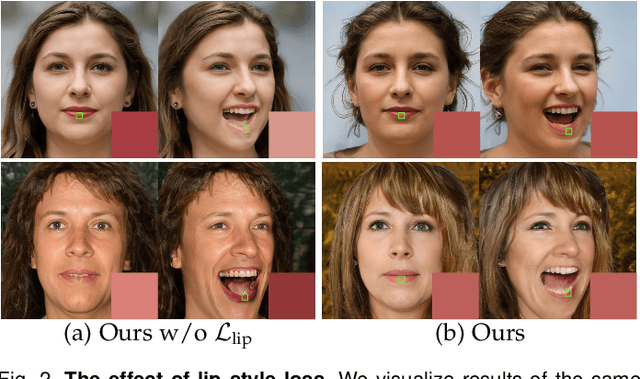
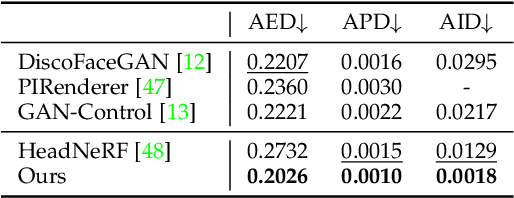
In contrast to the traditional avatar creation pipeline which is a costly process, contemporary generative approaches directly learn the data distribution from photographs. While plenty of works extend unconditional generative models and achieve some levels of controllability, it is still challenging to ensure multi-view consistency, especially in large poses. In this work, we propose a network that generates 3D-aware portraits while being controllable according to semantic parameters regarding pose, identity, expression and illumination. Our network uses neural scene representation to model 3D-aware portraits, whose generation is guided by a parametric face model that supports explicit control. While the latent disentanglement can be further enhanced by contrasting images with partially different attributes, there still exists noticeable inconsistency in non-face areas, e.g., hair and background, when animating expressions. Wesolve this by proposing a volume blending strategy in which we form a composite output by blending dynamic and static areas, with two parts segmented from the jointly learned semantic field. Our method outperforms prior arts in extensive experiments, producing realistic portraits with vivid expression in natural lighting when viewed from free viewpoints. It also demonstrates generalization ability to real images as well as out-of-domain data, showing great promise in real applications.
MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining
Aug 25, 2022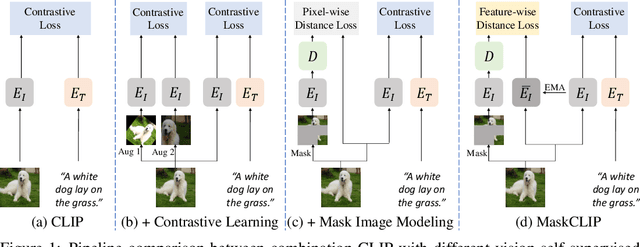
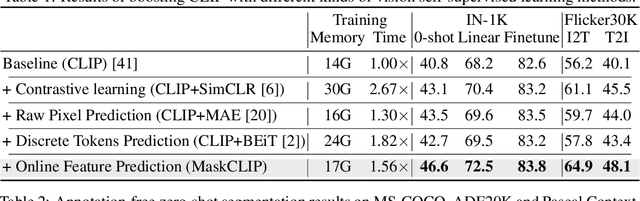
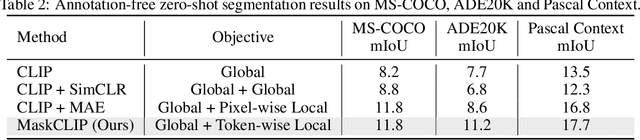
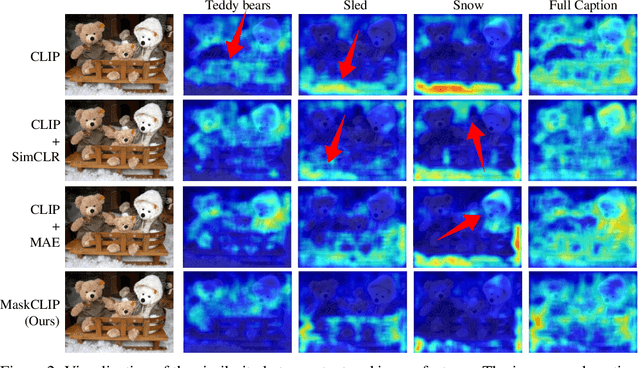
This paper presents a simple yet effective framework MaskCLIP, which incorporates a newly proposed masked self-distillation into contrastive language-image pretraining. The core idea of masked self-distillation is to distill representation from a full image to the representation predicted from a masked image. Such incorporation enjoys two vital benefits. First, masked self-distillation targets local patch representation learning, which is complementary to vision-language contrastive focusing on text-related representation.Second, masked self-distillation is also consistent with vision-language contrastive from the perspective of training objective as both utilize the visual encoder for feature aligning, and thus is able to learn local semantics getting indirect supervision from the language. We provide specially designed experiments with a comprehensive analysis to validate the two benefits. Empirically, we show that MaskCLIP, when applied to various challenging downstream tasks, achieves superior results in linear probing, finetuning as well as the zero-shot performance with the guidance of the language encoder.
Bootstrapped Masked Autoencoders for Vision BERT Pretraining
Jul 14, 2022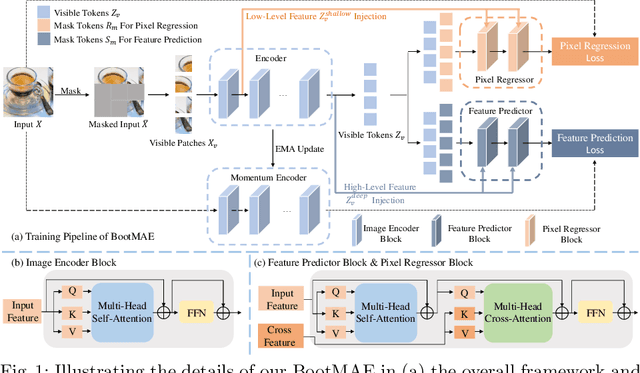



We propose bootstrapped masked autoencoders (BootMAE), a new approach for vision BERT pretraining. BootMAE improves the original masked autoencoders (MAE) with two core designs: 1) momentum encoder that provides online feature as extra BERT prediction targets; 2) target-aware decoder that tries to reduce the pressure on the encoder to memorize target-specific information in BERT pretraining. The first design is motivated by the observation that using a pretrained MAE to extract the features as the BERT prediction target for masked tokens can achieve better pretraining performance. Therefore, we add a momentum encoder in parallel with the original MAE encoder, which bootstraps the pretraining performance by using its own representation as the BERT prediction target. In the second design, we introduce target-specific information (e.g., pixel values of unmasked patches) from the encoder directly to the decoder to reduce the pressure on the encoder of memorizing the target-specific information. Thus, the encoder focuses on semantic modeling, which is the goal of BERT pretraining, and does not need to waste its capacity in memorizing the information of unmasked tokens related to the prediction target. Through extensive experiments, our BootMAE achieves $84.2\%$ Top-1 accuracy on ImageNet-1K with ViT-B backbone, outperforming MAE by $+0.8\%$ under the same pre-training epochs. BootMAE also gets $+1.0$ mIoU improvements on semantic segmentation on ADE20K and $+1.3$ box AP, $+1.4$ mask AP improvement on object detection and segmentation on COCO dataset. Code is released at https://github.com/LightDXY/BootMAE.
Improved Vector Quantized Diffusion Models
May 31, 2022
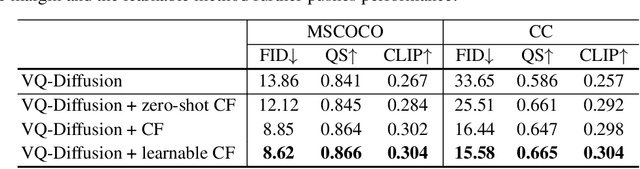
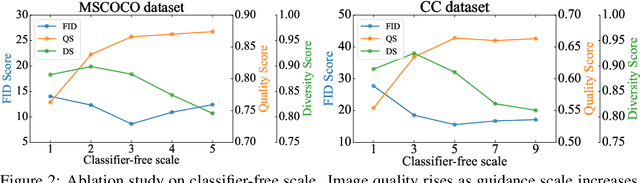
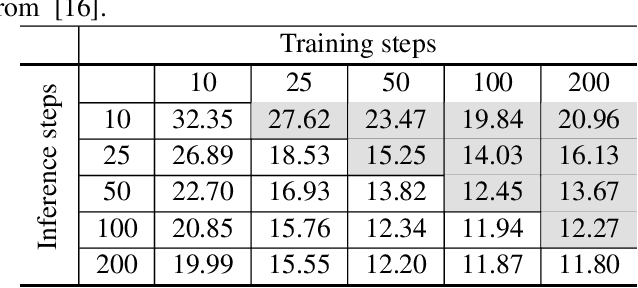
Vector quantized diffusion (VQ-Diffusion) is a powerful generative model for text-to-image synthesis, but sometimes can still generate low-quality samples or weakly correlated images with text input. We find these issues are mainly due to the flawed sampling strategy. In this paper, we propose two important techniques to further improve the sample quality of VQ-Diffusion. 1) We explore classifier-free guidance sampling for discrete denoising diffusion model and propose a more general and effective implementation of classifier-free guidance. 2) We present a high-quality inference strategy to alleviate the joint distribution issue in VQ-Diffusion. Finally, we conduct experiments on various datasets to validate their effectiveness and show that the improved VQ-Diffusion suppresses the vanilla version by large margins. We achieve an 8.44 FID score on MSCOCO, surpassing VQ-Diffusion by 5.42 FID score. When trained on ImageNet, we dramatically improve the FID score from 11.89 to 4.83, demonstrating the superiority of our proposed techniques.
Pretraining is All You Need for Image-to-Image Translation
May 25, 2022
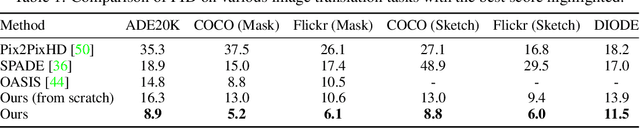
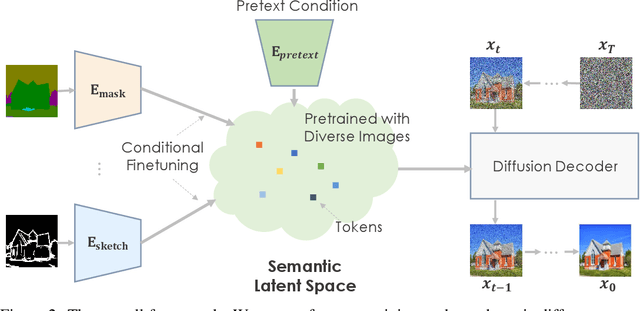
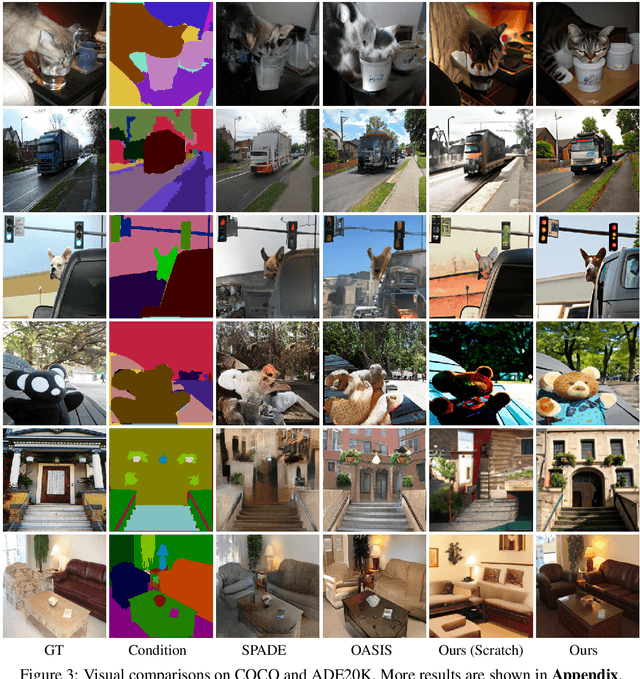
We propose to use pretraining to boost general image-to-image translation. Prior image-to-image translation methods usually need dedicated architectural design and train individual translation models from scratch, struggling for high-quality generation of complex scenes, especially when paired training data are not abundant. In this paper, we regard each image-to-image translation problem as a downstream task and introduce a simple and generic framework that adapts a pretrained diffusion model to accommodate various kinds of image-to-image translation. We also propose adversarial training to enhance the texture synthesis in the diffusion model training, in conjunction with normalized guidance sampling to improve the generation quality. We present extensive empirical comparison across various tasks on challenging benchmarks such as ADE20K, COCO-Stuff, and DIODE, showing the proposed pretraining-based image-to-image translation (PITI) is capable of synthesizing images of unprecedented realism and faithfulness.