 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
Dec 12, 2022



This paper presents a 3D generative model that uses diffusion models to automatically generate 3D digital avatars represented as neural radiance fields. A significant challenge in generating such avatars is that the memory and processing costs in 3D are prohibitive for producing the rich details required for high-quality avatars. To tackle this problem we propose the roll-out diffusion network (Rodin), which represents a neural radiance field as multiple 2D feature maps and rolls out these maps into a single 2D feature plane within which we perform 3D-aware diffusion. The Rodin model brings the much-needed computational efficiency while preserving the integrity of diffusion in 3D by using 3D-aware convolution that attends to projected features in the 2D feature plane according to their original relationship in 3D. We also use latent conditioning to orchestrate the feature generation for global coherence, leading to high-fidelity avatars and enabling their semantic editing based on text prompts. Finally, we use hierarchical synthesis to further enhance details. The 3D avatars generated by our model compare favorably with those produced by existing generative techniques. We can generate highly detailed avatars with realistic hairstyles and facial hair like beards. We also demonstrate 3D avatar generation from image or text as well as text-guided editability.
Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer
Dec 07, 2022



The long-standing theory that a colour-naming system evolves under the dual pressure of efficient communication and perceptual mechanism is supported by more and more linguistic studies including the analysis of four decades' diachronic data from the Nafaanra language. This inspires us to explore whether artificial intelligence could evolve and discover a similar colour-naming system via optimising the communication efficiency represented by high-level recognition performance. Here, we propose a novel colour quantisation transformer, CQFormer, that quantises colour space while maintaining the accuracy of machine recognition on the quantised images. Given an RGB image, Annotation Branch maps it into an index map before generating the quantised image with a colour palette, meanwhile the Palette Branch utilises a key-point detection way to find proper colours in palette among whole colour space. By interacting with colour annotation, CQFormer is able to balance both the machine vision accuracy and colour perceptual structure such as distinct and stable colour distribution for discovered colour system. Very interestingly, we even observe the consistent evolution pattern between our artificial colour system and basic colour terms across human languages. Besides, our colour quantisation method also offers an efficient quantisation method that effectively compresses the image storage while maintaining a high performance in high-level recognition tasks such as classification and detection. Extensive experiments demonstrate the superior performance of our method with extremely low bit-rate colours. We will release the source code soon.
DigiFace-1M: 1 Million Digital Face Images for Face Recognition
Oct 05, 2022


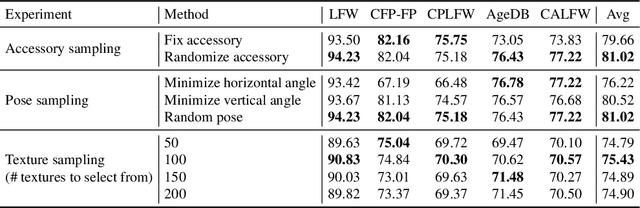
State-of-the-art face recognition models show impressive accuracy, achieving over 99.8% on Labeled Faces in the Wild (LFW) dataset. Such models are trained on large-scale datasets that contain millions of real human face images collected from the internet. Web-crawled face images are severely biased (in terms of race, lighting, make-up, etc) and often contain label noise. More importantly, the face images are collected without explicit consent, raising ethical concerns. To avoid such problems, we introduce a large-scale synthetic dataset for face recognition, obtained by rendering digital faces using a computer graphics pipeline. We first demonstrate that aggressive data augmentation can significantly reduce the synthetic-to-real domain gap. Having full control over the rendering pipeline, we also study how each attribute (e.g., variation in facial pose, accessories and textures) affects the accuracy. Compared to SynFace, a recent method trained on GAN-generated synthetic faces, we reduce the error rate on LFW by 52.5% (accuracy from 91.93% to 96.17%). By fine-tuning the network on a smaller number of real face images that could reasonably be obtained with consent, we achieve accuracy that is comparable to the methods trained on millions of real face images.
VolTeMorph: Realtime, Controllable and Generalisable Animation of Volumetric Representations
Aug 01, 2022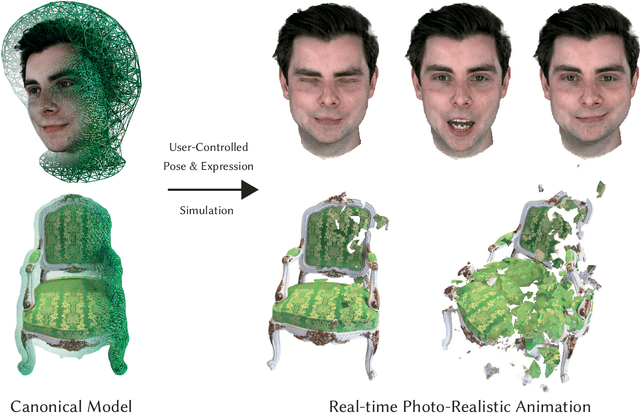
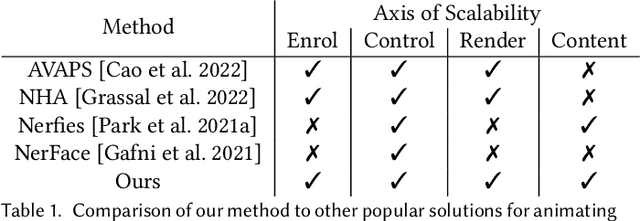
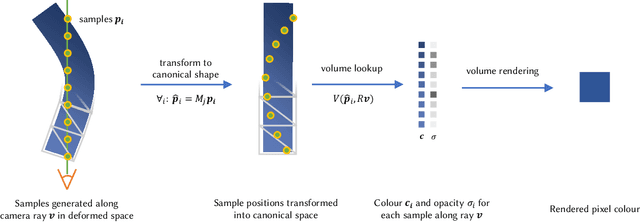
The recent increase in popularity of volumetric representations for scene reconstruction and novel view synthesis has put renewed focus on animating volumetric content at high visual quality and in real-time. While implicit deformation methods based on learned functions can produce impressive results, they are `black boxes' to artists and content creators, they require large amounts of training data to generalise meaningfully, and they do not produce realistic extrapolations outside the training data. In this work we solve these issues by introducing a volume deformation method which is real-time, easy to edit with off-the-shelf software and can extrapolate convincingly. To demonstrate the versatility of our method, we apply it in two scenarios: physics-based object deformation and telepresence where avatars are controlled using blendshapes. We also perform thorough experiments showing that our method compares favourably to both volumetric approaches combined with implicit deformation and methods based on mesh deformation.
3D face reconstruction with dense landmarks
Apr 06, 2022



Landmarks often play a key role in face analysis, but many aspects of identity or expression cannot be represented by sparse landmarks alone. Thus, in order to reconstruct faces more accurately, landmarks are often combined with additional signals like depth images or techniques like differentiable rendering. Can we keep things simple by just using more landmarks? In answer, we present the first method that accurately predicts 10x as many landmarks as usual, covering the whole head, including the eyes and teeth. This is accomplished using synthetic training data, which guarantees perfect landmark annotations. By fitting a morphable model to these dense landmarks, we achieve state-of-the-art results for monocular 3D face reconstruction in the wild. We show that dense landmarks are an ideal signal for integrating face shape information across frames by demonstrating accurate and expressive facial performance capture in both monocular and multi-view scenarios. This approach is also highly efficient: we can predict dense landmarks and fit our 3D face model at over 150FPS on a single CPU thread.
Learning to Fit Morphable Models
Nov 29, 2021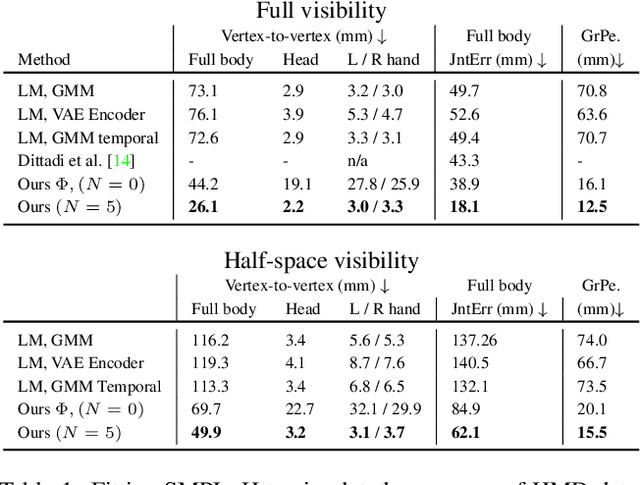
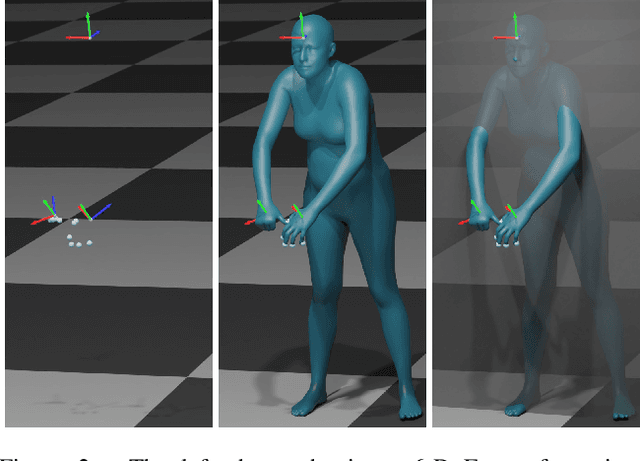


Fitting parametric models of human bodies, hands or faces to sparse input signals in an accurate, robust, and fast manner has the promise of significantly improving immersion in AR and VR scenarios. A common first step in systems that tackle these problems is to regress the parameters of the parametric model directly from the input data. This approach is fast, robust, and is a good starting point for an iterative minimization algorithm. The latter searches for the minimum of an energy function, typically composed of a data term and priors that encode our knowledge about the problem's structure. While this is undoubtedly a very successful recipe, priors are often hand defined heuristics and finding the right balance between the different terms to achieve high quality results is a non-trivial task. Furthermore, converting and optimizing these systems to run in a performant way requires custom implementations that demand significant time investments from both engineers and domain experts. In this work, we build upon recent advances in learned optimization and propose an update rule inspired by the classic Levenberg-Marquardt algorithm. We show the effectiveness of the proposed neural optimizer on the problems of 3D body surface estimation from a head-mounted device and face fitting from 2D landmarks. Our method can easily be applied to new model fitting problems and offers a competitive alternative to well tuned 'traditional' model fitting pipelines, both in terms of accuracy and speed.
Zeroth-Order Alternating Randomized Gradient Projection Algorithms for General Nonconvex-Concave Minimax Problems
Aug 05, 2021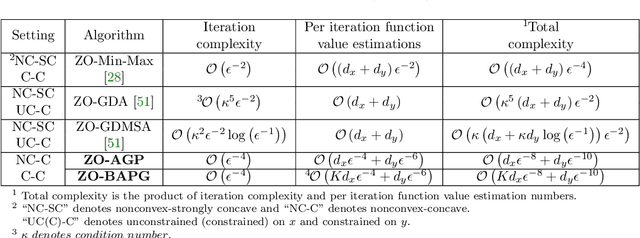
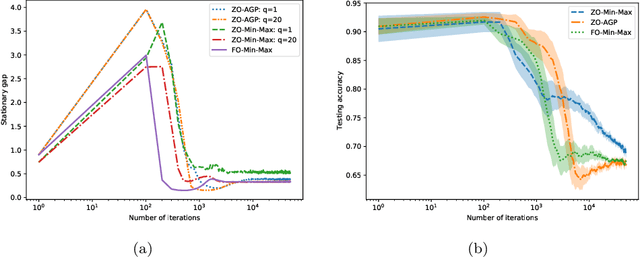
In this paper, we study zeroth-order algorithms for nonconvex-concave minimax problems, which have attracted widely attention in machine learning, signal processing and many other fields in recent years. We propose a zeroth-order alternating randomized gradient projection (ZO-AGP) algorithm for smooth nonconvex-concave minimax problems, and its iteration complexity to obtain an $\varepsilon$-stationary point is bounded by $\mathcal{O}(\varepsilon^{-4})$, and the number of function value estimation is bounded by $\mathcal{O}(d_{x}\varepsilon^{-4}+d_{y}\varepsilon^{-6})$ per iteration. Moreover, we propose a zeroth-order block alternating randomized proximal gradient algorithm (ZO-BAPG) for solving block-wise nonsmooth nonconvex-concave minimax optimization problems, and the iteration complexity to obtain an $\varepsilon$-stationary point is bounded by $\mathcal{O}(\varepsilon^{-4})$ and the number of function value estimation per iteration is bounded by $\mathcal{O}(K d_{x}\varepsilon^{-4}+d_{y}\varepsilon^{-6})$. To the best of our knowledge, this is the first time that zeroth-order algorithms with iteration complexity gurantee are developed for solving both general smooth and block-wise nonsmooth nonconvex-concave minimax problems. Numerical results on data poisoning attack problem validate the efficiency of the proposed algorithms.
The Phong Surface: Efficient 3D Model Fitting using Lifted Optimization
Jul 09, 2020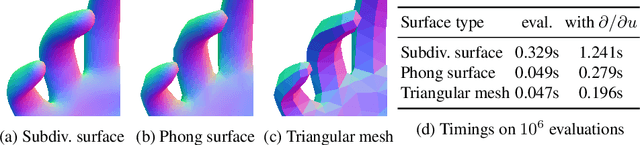
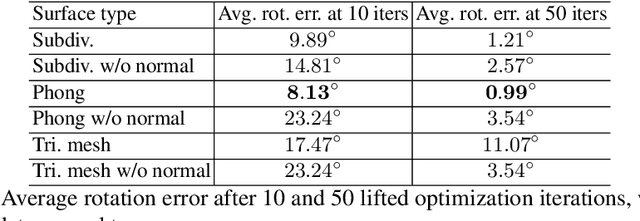
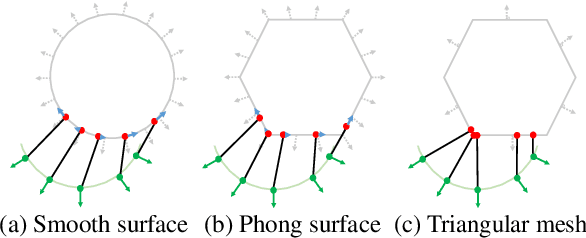
Realtime perceptual and interaction capabilities in mixed reality require a range of 3D tracking problems to be solved at low latency on resource-constrained hardware such as head-mounted devices. Indeed, for devices such as HoloLens 2 where the CPU and GPU are left available for applications, multiple tracking subsystems are required to run on a continuous, real-time basis while sharing a single Digital Signal Processor. To solve model-fitting problems for HoloLens 2 hand tracking, where the computational budget is approximately 100 times smaller than an iPhone 7, we introduce a new surface model: the `Phong surface'. Using ideas from computer graphics, the Phong surface describes the same 3D shape as a triangulated mesh model, but with continuous surface normals which enable the use of lifting-based optimization, providing significant efficiency gains over ICP-based methods. We show that Phong surfaces retain the convergence benefits of smoother surface models, while triangle meshes do not.