 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Ma, no markers: holistic performance capture without the hassle
Oct 15, 2024



We tackle the problem of highly-accurate, holistic performance capture for the face, body and hands simultaneously. Motion-capture technologies used in film and game production typically focus only on face, body or hand capture independently, involve complex and expensive hardware and a high degree of manual intervention from skilled operators. While machine-learning-based approaches exist to overcome these problems, they usually only support a single camera, often operate on a single part of the body, do not produce precise world-space results, and rarely generalize outside specific contexts. In this work, we introduce the first technique for marker-free, high-quality reconstruction of the complete human body, including eyes and tongue, without requiring any calibration, manual intervention or custom hardware. Our approach produces stable world-space results from arbitrary camera rigs as well as supporting varied capture environments and clothing. We achieve this through a hybrid approach that leverages machine learning models trained exclusively on synthetic data and powerful parametric models of human shape and motion. We evaluate our method on a number of body, face and hand reconstruction benchmarks and demonstrate state-of-the-art results that generalize on diverse datasets.
VolTeMorph: Realtime, Controllable and Generalisable Animation of Volumetric Representations
Aug 01, 2022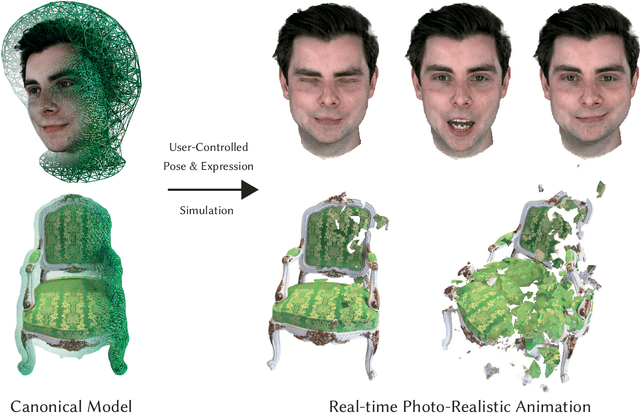
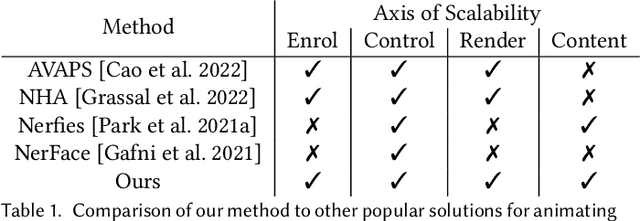
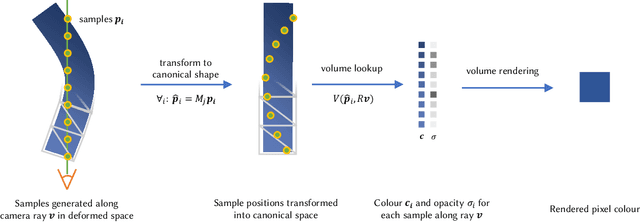
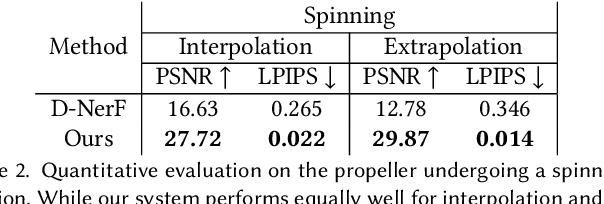
The recent increase in popularity of volumetric representations for scene reconstruction and novel view synthesis has put renewed focus on animating volumetric content at high visual quality and in real-time. While implicit deformation methods based on learned functions can produce impressive results, they are `black boxes' to artists and content creators, they require large amounts of training data to generalise meaningfully, and they do not produce realistic extrapolations outside the training data. In this work we solve these issues by introducing a volume deformation method which is real-time, easy to edit with off-the-shelf software and can extrapolate convincingly. To demonstrate the versatility of our method, we apply it in two scenarios: physics-based object deformation and telepresence where avatars are controlled using blendshapes. We also perform thorough experiments showing that our method compares favourably to both volumetric approaches combined with implicit deformation and methods based on mesh deformation.
Offline Reinforcement Learning as Anti-Exploration
Jun 11, 2021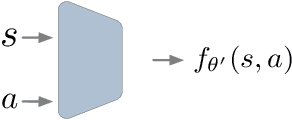
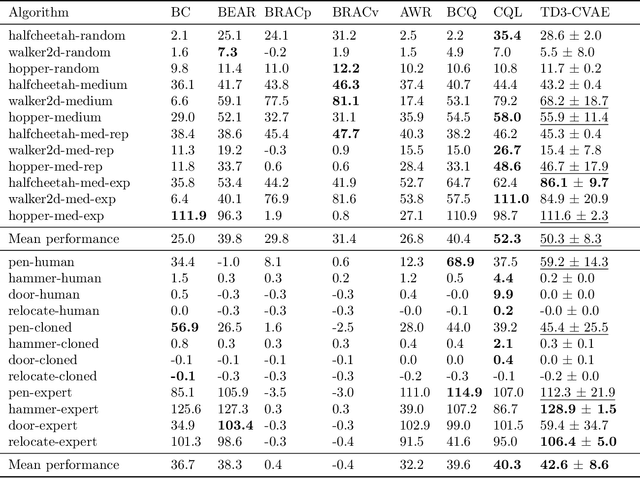
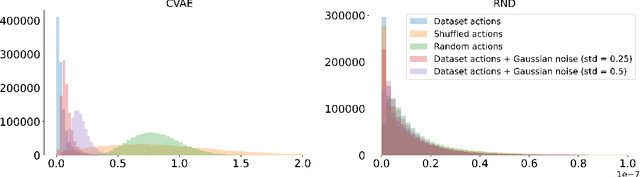
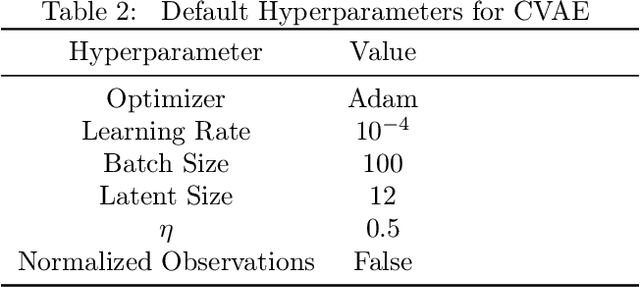
Offline Reinforcement Learning (RL) aims at learning an optimal control from a fixed dataset, without interactions with the system. An agent in this setting should avoid selecting actions whose consequences cannot be predicted from the data. This is the converse of exploration in RL, which favors such actions. We thus take inspiration from the literature on bonus-based exploration to design a new offline RL agent. The core idea is to subtract a prediction-based exploration bonus from the reward, instead of adding it for exploration. This allows the policy to stay close to the support of the dataset. We connect this approach to a more common regularization of the learned policy towards the data. Instantiated with a bonus based on the prediction error of a variational autoencoder, we show that our agent is competitive with the state of the art on a set of continuous control locomotion and manipulation tasks.
Offline Reinforcement Learning with Pseudometric Learning
Mar 02, 2021
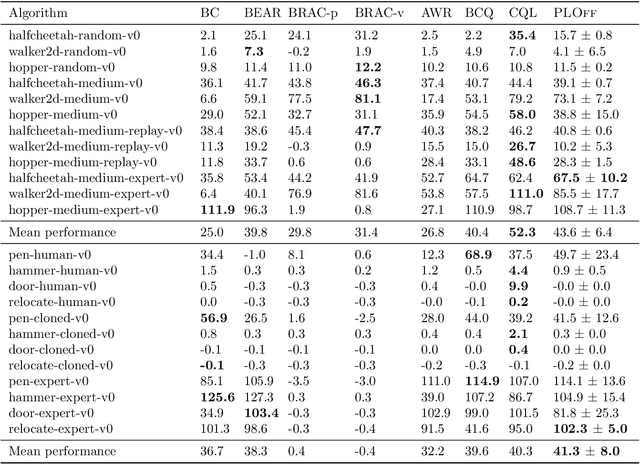

Offline Reinforcement Learning methods seek to learn a policy from logged transitions of an environment, without any interaction. In the presence of function approximation, and under the assumption of limited coverage of the state-action space of the environment, it is necessary to enforce the policy to visit state-action pairs close to the support of logged transitions. In this work, we propose an iterative procedure to learn a pseudometric (closely related to bisimulation metrics) from logged transitions, and use it to define this notion of closeness. We show its convergence and extend it to the function approximation setting. We then use this pseudometric to define a new lookup based bonus in an actor-critic algorithm: PLOff. This bonus encourages the actor to stay close, in terms of the defined pseudometric, to the support of logged transitions. Finally, we evaluate the method on hand manipulation and locomotion tasks.
Information bottleneck through variational glasses
Dec 05, 2019
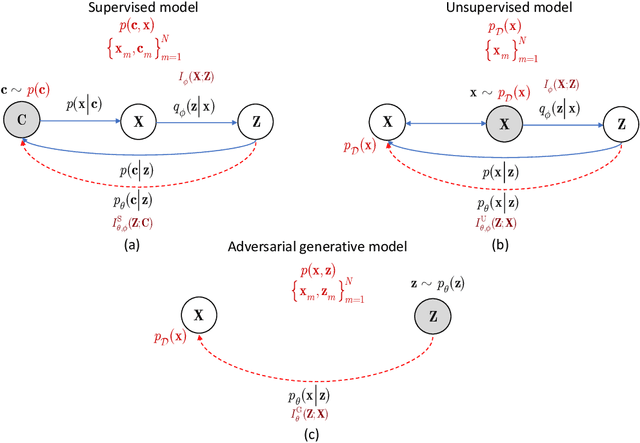
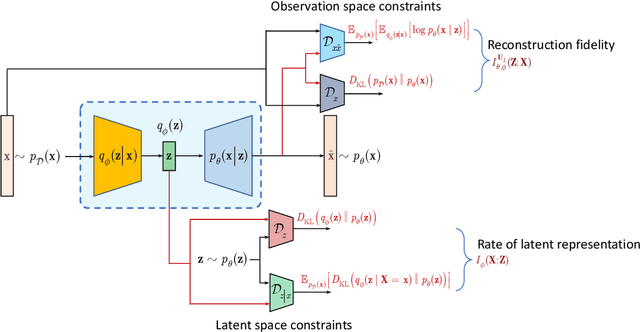
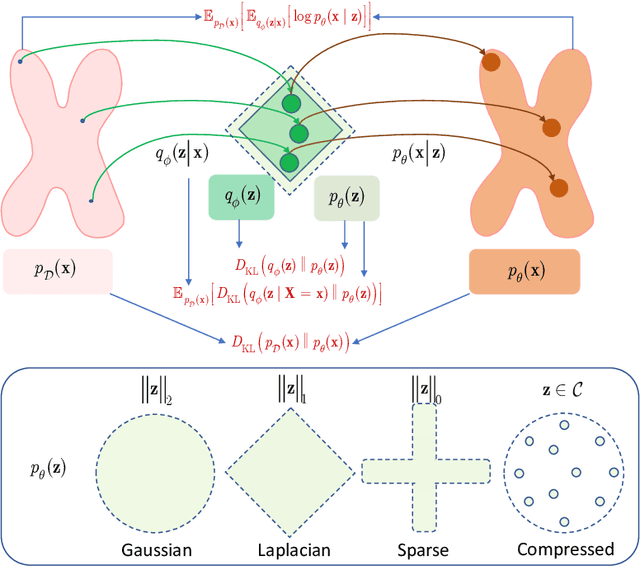
Information bottleneck (IB) principle [1] has become an important element in information-theoretic analysis of deep models. Many state-of-the-art generative models of both Variational Autoencoder (VAE) [2; 3] and Generative Adversarial Networks (GAN) [4] families use various bounds on mutual information terms to introduce certain regularization constraints [5; 6; 7; 8; 9; 10]. Accordingly, the main difference between these models consists in add regularization constraints and targeted objectives. In this work, we will consider the IB framework for three classes of models that include supervised, unsupervised and adversarial generative models. We will apply a variational decomposition leading a common structure and allowing easily establish connections between these models and analyze underlying assumptions. Based on these results, we focus our analysis on unsupervised setup and reconsider the VAE family. In particular, we present a new interpretation of VAE family based on the IB framework using a direct decomposition of mutual information terms and show some interesting connections to existing methods such as VAE [2; 3], beta-VAE [11], AAE [12], InfoVAE [5] and VAE/GAN [13]. Instead of adding regularization constraints to an evidence lower bound (ELBO) [2; 3], which itself is a lower bound, we show that many known methods can be considered as a product of variational decomposition of mutual information terms in the IB framework. The proposed decomposition might also contribute to the interpretability of generative models of both VAE and GAN families and create a new insights to a generative compression [14; 15; 16; 17]. It can also be of interest for the analysis of novelty detection based on one-class classifiers [18] with the IB based discriminators.
$ρ$-VAE: Autoregressive parametrization of the VAE encoder
Sep 13, 2019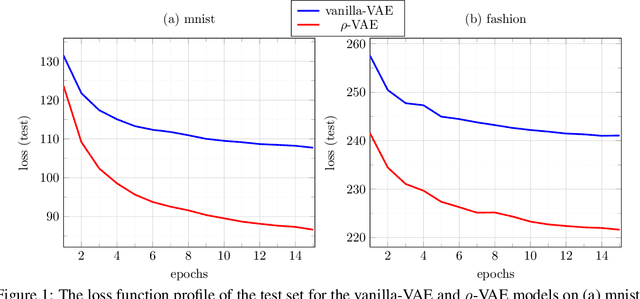

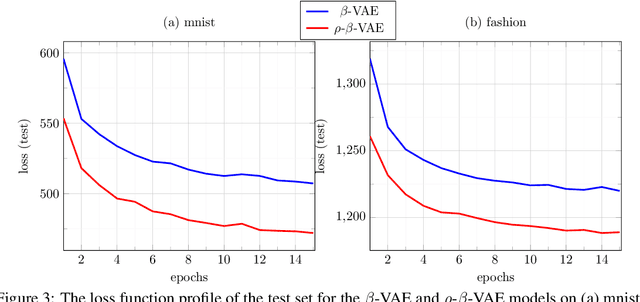
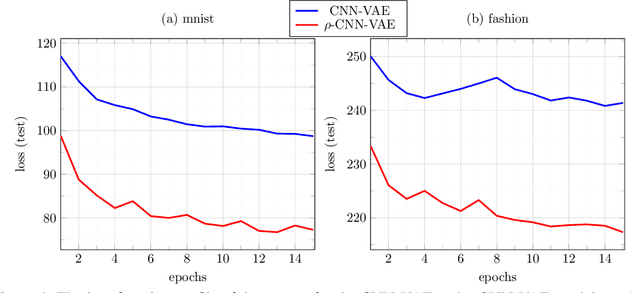
We make a minimal, but very effective alteration to the VAE model. This is about a drop-in replacement for the (sample-dependent) approximate posterior to change it from the standard white Gaussian with diagonal covariance to the first-order autoregressive Gaussian. We argue that this is a more reasonable choice to adopt for natural signals like images, as it does not force the existing correlation in the data to disappear in the posterior. Moreover, it allows more freedom for the approximate posterior to match the true posterior. This allows for the repararametrization trick, as well as the KL-divergence term to still have closed-form expressions, obviating the need for its sample-based estimation. Although providing more freedom to adapt to correlated distributions, our parametrization has even less number of parameters than the diagonal covariance, as it requires only two scalars, $\rho$ and $s$, to characterize correlation and scaling, respectively. As validated by the experiments, our proposition noticeably and consistently improves the quality of image generation in a plug-and-play manner, needing no further parameter tuning, and across all setups. The code to reproduce our experiments is available at \url{https://github.com/sssohrab/rho_VAE/}.
Robustification of deep net classifiers by key based diversified aggregation with pre-filtering
May 14, 2019
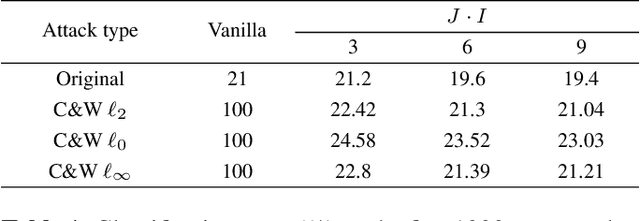

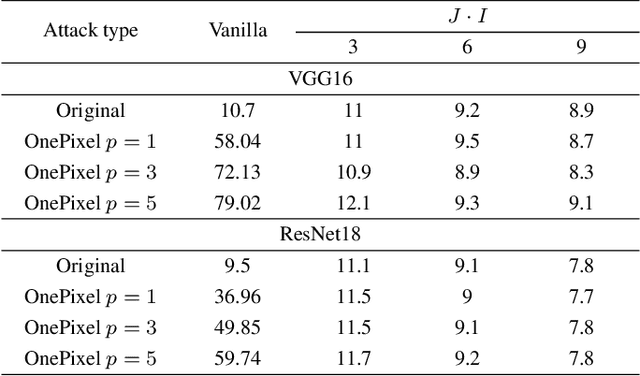
In this paper, we address a problem of machine learning system vulnerability to adversarial attacks. We propose and investigate a Key based Diversified Aggregation (KDA) mechanism as a defense strategy. The KDA assumes that the attacker (i) knows the architecture of classifier and the used defense strategy, (ii) has an access to the training data set but (iii) does not know the secret key. The robustness of the system is achieved by a specially designed key based randomization. The proposed randomization prevents the gradients' back propagation or the creating of a "bypass" system. The randomization is performed simultaneously in several channels and a multi-channel aggregation stabilizes the results of randomization by aggregating soft outputs from each classifier in multi-channel system. The performed experimental evaluation demonstrates a high robustness and universality of the KDA against the most efficient gradient based attacks like those proposed by N. Carlini and D. Wagner and the non-gradient based sparse adversarial perturbations like OnePixel attacks.
Reconstruction of Privacy-Sensitive Data from Protected Templates
May 08, 2019


In this paper, we address the problem of data reconstruction from privacy-protected templates, based on recent concept of sparse ternary coding with ambiguization (STCA). The STCA is a generalization of randomization techniques which includes random projections, lossy quantization, and addition of ambiguization noise to satisfy the privacy-utility trade-off requirements. The theoretical privacy-preserving properties of STCA have been validated on synthetic data. However, the applicability of STCA to real data and potential threats linked to reconstruction based on recent deep reconstruction algorithms are still open problems. Our results demonstrate that STCA still achieves the claimed theoretical performance when facing deep reconstruction attacks for the synthetic i.i.d. data, while for real images special measures are required to guarantee proper protection of the templates.
Defending against adversarial attacks by randomized diversification
Apr 01, 2019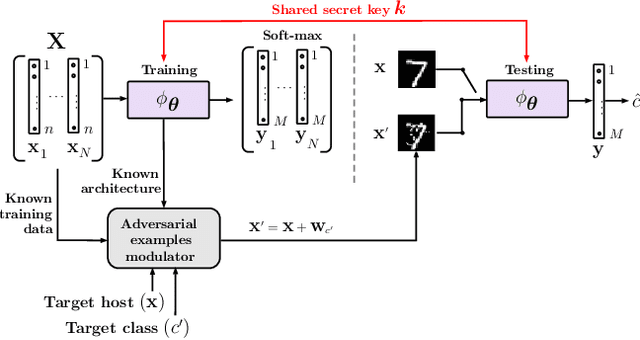
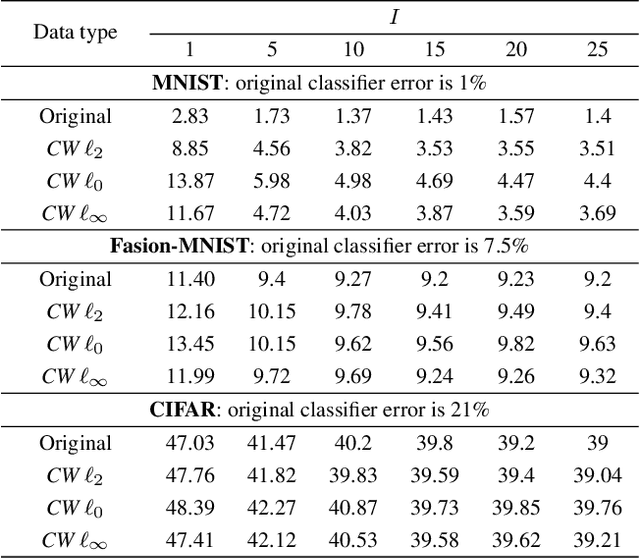

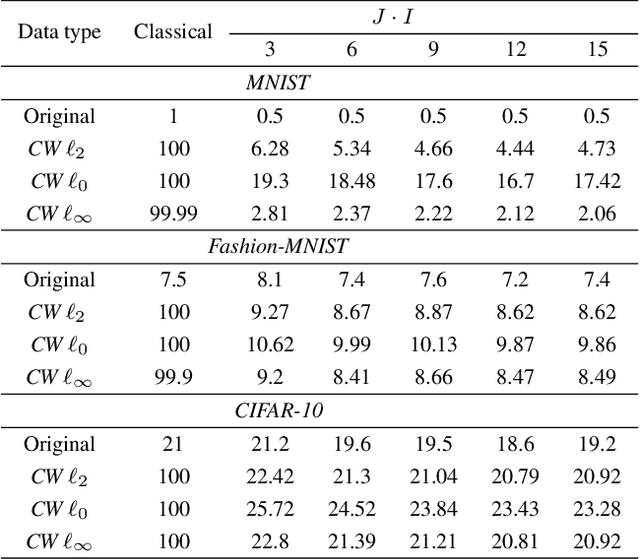
The vulnerability of machine learning systems to adversarial attacks questions their usage in many applications. In this paper, we propose a randomized diversification as a defense strategy. We introduce a multi-channel architecture in a gray-box scenario, which assumes that the architecture of the classifier and the training data set are known to the attacker. The attacker does not only have access to a secret key and to the internal states of the system at the test time. The defender processes an input in multiple channels. Each channel introduces its own randomization in a special transform domain based on a secret key shared between the training and testing stages. Such a transform based randomization with a shared key preserves the gradients in key-defined sub-spaces for the defender but it prevents gradient back propagation and the creation of various bypass systems for the attacker. An additional benefit of multi-channel randomization is the aggregation that fuses soft-outputs from all channels, thus increasing the reliability of the final score. The sharing of a secret key creates an information advantage to the defender. Experimental evaluation demonstrates an increased robustness of the proposed method to a number of known state-of-the-art attacks.
Classification by Re-generation: Towards Classification Based on Variational Inference
Sep 10, 2018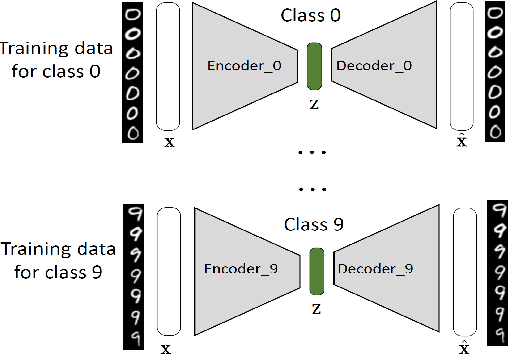
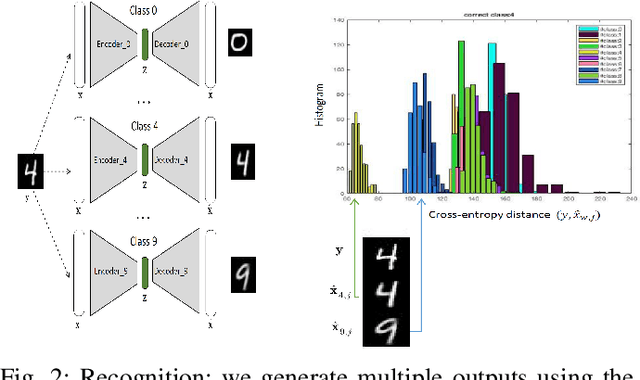
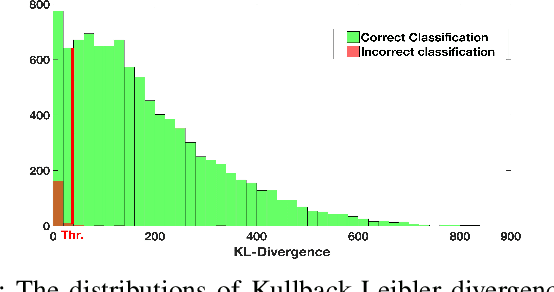
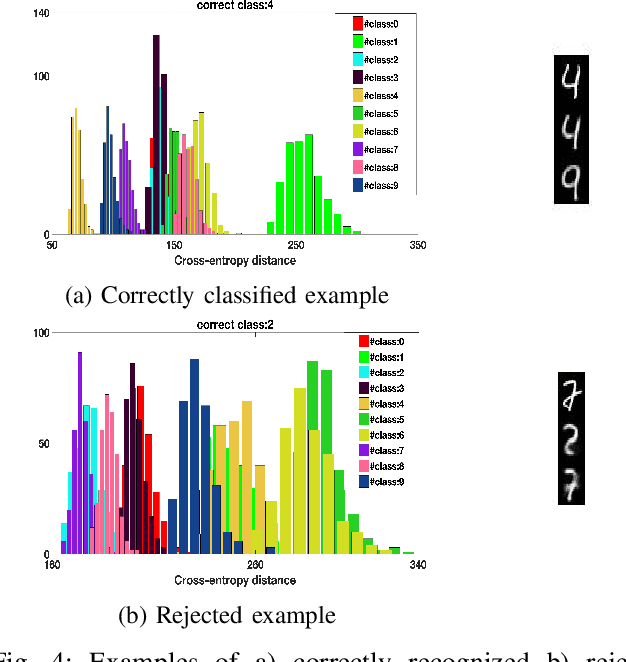
As Deep Neural Networks (DNNs) are considered the state-of-the-art in many classification tasks, the question of their semantic generalizations has been raised. To address semantic interpretability of learned features, we introduce a novel idea of classification by re-generation based on variational autoencoder (VAE) in which a separate encoder-decoder pair of VAE is trained for each class. Moreover, the proposed architecture overcomes the scalability issue in current DNN networks as there is no need to re-train the whole network with the addition of new classes and it can be done for each class separately. We also introduce a criterion based on Kullback-Leibler divergence to reject doubtful examples. This rejection criterion should improve the trust in the obtained results and can be further exploited to reject adversarial examples.