 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Inspired Context-Selective Multimodal Memory for Social Robots
Apr 13, 2026Memory is fundamental to social interaction, enabling humans to recall meaningful past experiences and adapt their behavior accordingly based on the context. However, most current social robots and embodied agents rely on non-selective, text-based memory, limiting their ability to support personalized, context-aware interactions. Drawing inspiration from cognitive neuroscience, we propose a context-selective, multimodal memory architecture for social robots that captures and retrieves both textual and visual episodic traces, prioritizing moments characterized by high emotional salience or scene novelty. By associating these memories with individual users, our system enables socially personalized recall and more natural, grounded dialogue. We evaluate the selective storage mechanism using a curated dataset of social scenarios, achieving a Spearman correlation of 0.506, surpassing human consistency ($ρ=0.415$) and outperforming existing image memorability models. In multimodal retrieval experiments, our fusion approach improves Recall@1 by up to 13\% over unimodal text or image retrieval. Runtime evaluations confirm that the system maintains real-time performance. Qualitative analyses further demonstrate that the proposed framework produces richer and more socially relevant responses than baseline models. This work advances memory design for social robots by bridging human-inspired selectivity and multimodal retrieval to enhance long-term, personalized human-robot interaction.
Beyond Classification: Evaluating Diffusion Denoised Smoothing for Security-Utility Trade off
May 21, 2025While foundation models demonstrate impressive performance across various tasks, they remain vulnerable to adversarial inputs. Current research explores various approaches to enhance model robustness, with Diffusion Denoised Smoothing emerging as a particularly promising technique. This method employs a pretrained diffusion model to preprocess inputs before model inference. Yet, its effectiveness remains largely unexplored beyond classification. We aim to address this gap by analyzing three datasets with four distinct downstream tasks under three different adversarial attack algorithms. Our findings reveal that while foundation models maintain resilience against conventional transformations, applying high-noise diffusion denoising to clean images without any distortions significantly degrades performance by as high as 57%. Low-noise diffusion settings preserve performance but fail to provide adequate protection across all attack types. Moreover, we introduce a novel attack strategy specifically targeting the diffusion process itself, capable of circumventing defenses in the low-noise regime. Our results suggest that the trade-off between adversarial robustness and performance remains a challenge to be addressed.
Enhancing Image Resolution of Solar Magnetograms: A Latent Diffusion Model Approach
Mar 31, 2025The spatial properties of the solar magnetic field are crucial to decoding the physical processes in the solar interior and their interplanetary effects. However, observations from older instruments, such as the Michelson Doppler Imager (MDI), have limited spatial or temporal resolution, which hinders the ability to study small-scale solar features in detail. Super resolving these older datasets is essential for uniform analysis across different solar cycles, enabling better characterization of solar flares, active regions, and magnetic network dynamics. In this work, we introduce a novel diffusion model approach for Super-Resolution and we apply it to MDI magnetograms to match the higher-resolution capabilities of the Helioseismic and Magnetic Imager (HMI). By training a Latent Diffusion Model (LDM) with residuals on downscaled HMI data and fine-tuning it with paired MDI/HMI data, we can enhance the resolution of MDI observations from 2"/pixel to 0.5"/pixel. We evaluate the quality of the reconstructed images by means of classical metrics (e.g., PSNR, SSIM, FID and LPIPS) and we check if physical properties, such as the unsigned magnetic flux or the size of an active region, are preserved. We compare our model with different variations of LDM and Denoising Diffusion Probabilistic models (DDPMs), but also with two deterministic architectures already used in the past for performing the Super-Resolution task. Furthermore, we show with an analysis in the Fourier domain that the LDM with residuals can resolve features smaller than 2", and due to the probabilistic nature of the LDM, we can asses their reliability, in contrast with the deterministic models. Future studies aim to super-resolve the temporal scale of the solar MDI instrument so that we can also have a better overview of the dynamics of the old events.
Robustness Tokens: Towards Adversarial Robustness of Transformers
Mar 13, 2025Recently, large pre-trained foundation models have become widely adopted by machine learning practitioners for a multitude of tasks. Given that such models are publicly available, relying on their use as backbone models for downstream tasks might result in high vulnerability to adversarial attacks crafted with the same public model. In this work, we propose Robustness Tokens, a novel approach specific to the transformer architecture that fine-tunes a few additional private tokens with low computational requirements instead of tuning model parameters as done in traditional adversarial training. We show that Robustness Tokens make Vision Transformer models significantly more robust to white-box adversarial attacks while also retaining the original downstream performances.
* This paper has been accepted for publication at the European Conference on Computer Vision (ECCV), 2024
TwinTURBO: Semi-Supervised Fine-Tuning of Foundation Models via Mutual Information Decompositions for Downstream Task and Latent Spaces
Mar 10, 2025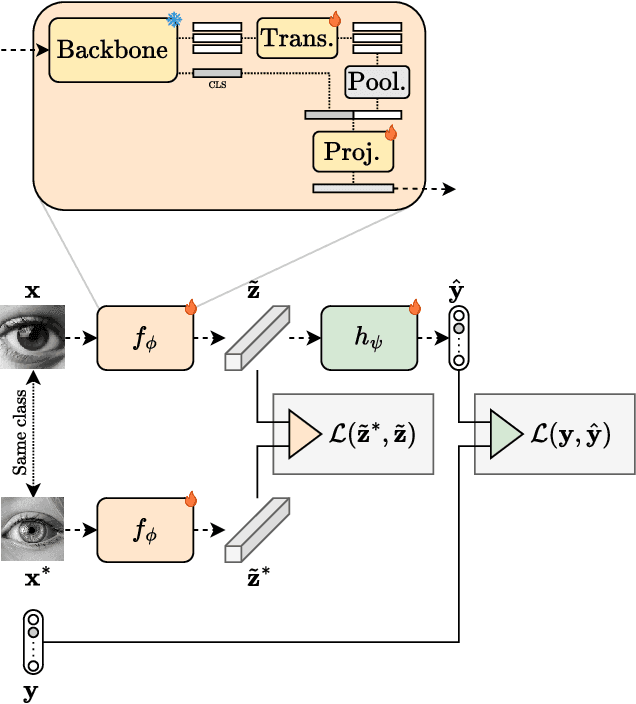
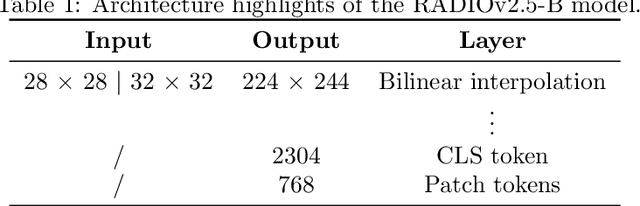

We present a semi-supervised fine-tuning framework for foundation models that utilises mutual information decomposition to address the challenges of training for a limited amount of labelled data. Our approach derives two distinct lower bounds: i) for the downstream task space, such as classification, optimised using conditional and marginal cross-entropy alongside Kullback-Leibler divergence, and ii) for the latent space representation, regularised and aligned using a contrastive-like decomposition. This fine-tuning strategy retains the pre-trained structure of the foundation model, modifying only a specialised projector module comprising a small transformer and a token aggregation technique. Experiments on several datasets demonstrate significant improvements in classification tasks under extremely low-labelled conditions by effectively leveraging unlabelled data.
Task-Agnostic Attacks Against Vision Foundation Models
Mar 05, 2025
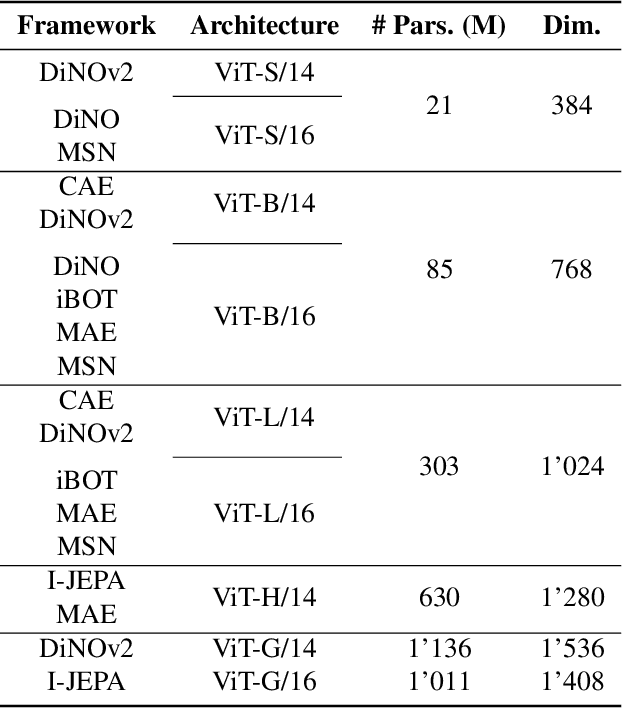
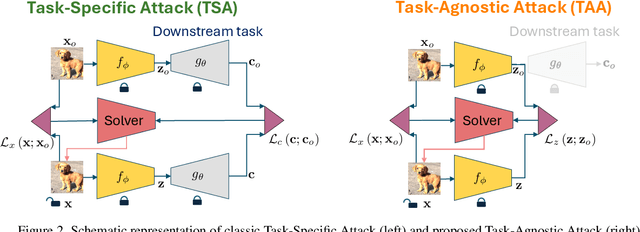
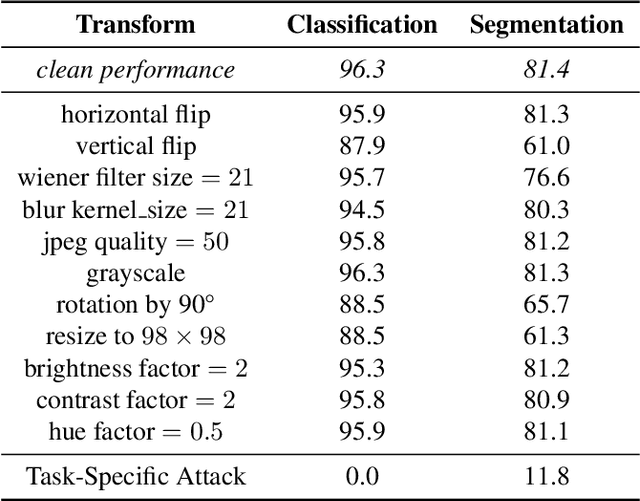
The study of security in machine learning mainly focuses on downstream task-specific attacks, where the adversarial example is obtained by optimizing a loss function specific to the downstream task. At the same time, it has become standard practice for machine learning practitioners to adopt publicly available pre-trained vision foundation models, effectively sharing a common backbone architecture across a multitude of applications such as classification, segmentation, depth estimation, retrieval, question-answering and more. The study of attacks on such foundation models and their impact to multiple downstream tasks remains vastly unexplored. This work proposes a general framework that forges task-agnostic adversarial examples by maximally disrupting the feature representation obtained with foundation models. We extensively evaluate the security of the feature representations obtained by popular vision foundation models by measuring the impact of this attack on multiple downstream tasks and its transferability between models.
Binary Diffusion Probabilistic Model
Jan 23, 2025



We introduce the Binary Diffusion Probabilistic Model (BDPM), a novel generative model optimized for binary data representations. While denoising diffusion probabilistic models (DDPMs) have demonstrated notable success in tasks like image synthesis and restoration, traditional DDPMs rely on continuous data representations and mean squared error (MSE) loss for training, applying Gaussian noise models that may not be optimal for discrete or binary data structures. BDPM addresses this by decomposing images into bitplanes and employing XOR-based noise transformations, with a denoising model trained using binary cross-entropy loss. This approach enables precise noise control and computationally efficient inference, significantly lowering computational costs and improving model convergence. When evaluated on image restoration tasks such as image super-resolution, inpainting, and blind image restoration, BDPM outperforms state-of-the-art methods on the FFHQ, CelebA, and CelebA-HQ datasets. Notably, BDPM requires fewer inference steps than traditional DDPM models to reach optimal results, showcasing enhanced inference efficiency.
Semi-Supervised Fine-Tuning of Vision Foundation Models with Content-Style Decomposition
Oct 02, 2024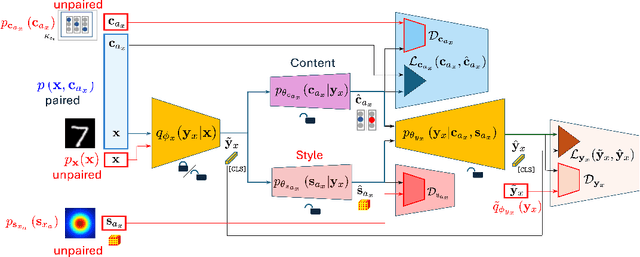



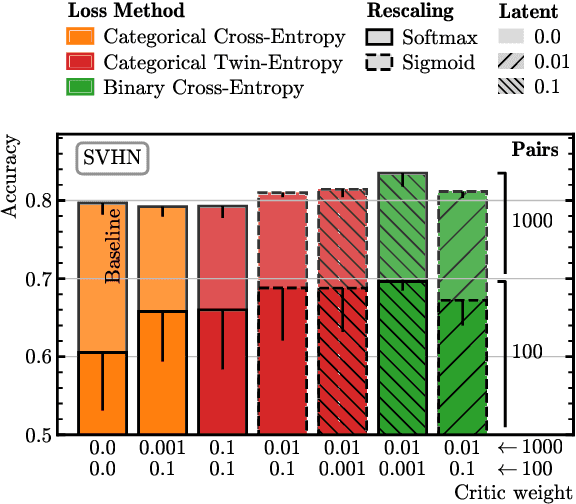
In this paper, we present a semi-supervised fine-tuning approach designed to improve the performance of foundation models on downstream tasks with limited labeled data. By leveraging content-style decomposition within an information-theoretic framework, our method enhances the latent representations of pre-trained vision foundation models, aligning them more effectively with specific task objectives and addressing the problem of distribution shift. We evaluate our approach on multiple datasets, including MNIST, its augmented variations (with yellow and white stripes), CIFAR-10, SVHN, and GalaxyMNIST. The experiments show improvements over purely supervised baselines, particularly in low-labeled data regimes, across both frozen and trainable backbones for the majority of the tested datasets.
Evaluation of Security of ML-based Watermarking: Copy and Removal Attacks
Sep 26, 2024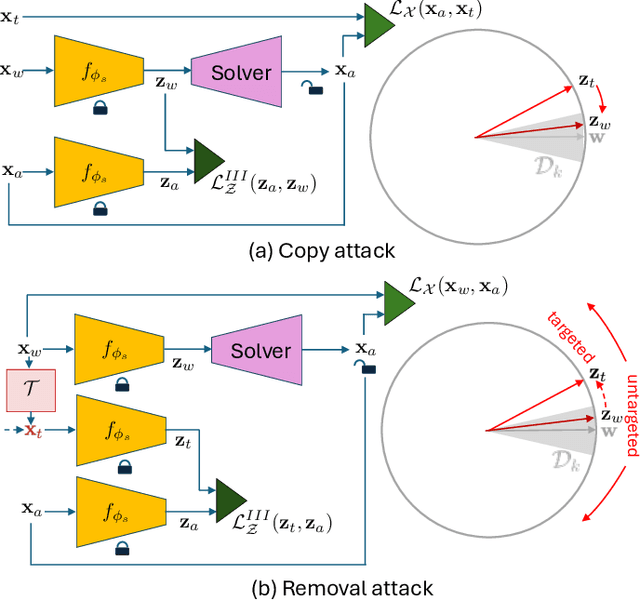
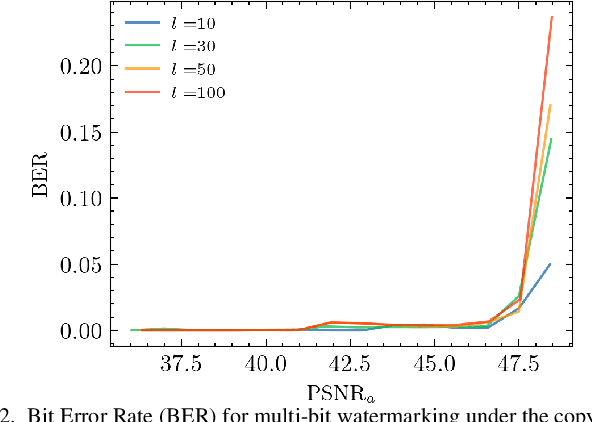
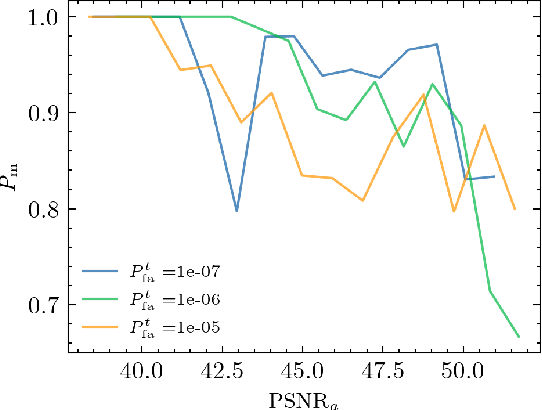
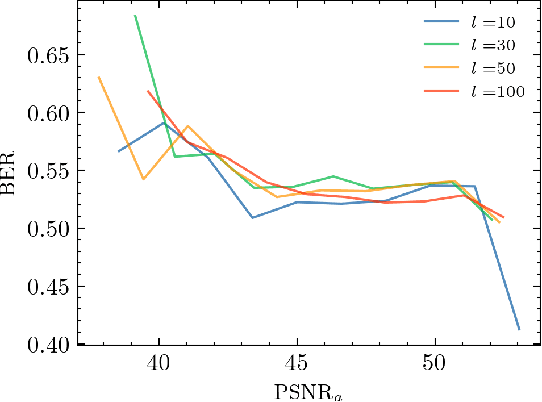
The vast amounts of digital content captured from the real world or AI-generated media necessitate methods for copyright protection, traceability, or data provenance verification. Digital watermarking serves as a crucial approach to address these challenges. Its evolution spans three generations: handcrafted, autoencoder-based, and foundation model based methods. %Its evolution spans three generations: handcrafted methods, autoencoder-based schemes, and methods based on foundation models. While the robustness of these systems is well-documented, the security against adversarial attacks remains underexplored. This paper evaluates the security of foundation models' latent space digital watermarking systems that utilize adversarial embedding techniques. A series of experiments investigate the security dimensions under copy and removal attacks, providing empirical insights into these systems' vulnerabilities. All experimental codes and results are available at https://github.com/vkinakh/ssl-watermarking-attacks}{repository
Provable Performance Guarantees of Copy Detection Patterns
Sep 26, 2024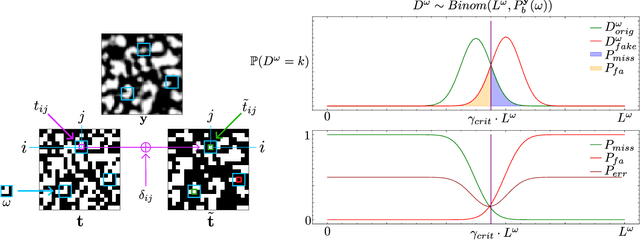
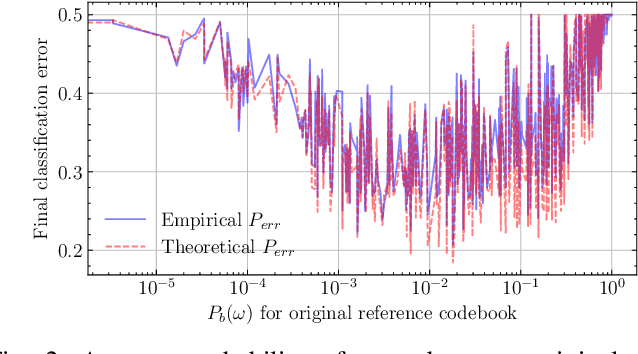
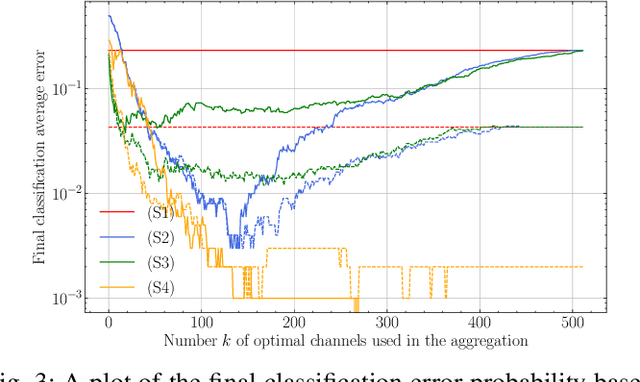
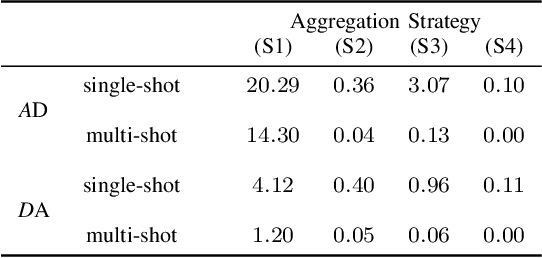
Copy Detection Patterns (CDPs) are crucial elements in modern security applications, playing a vital role in safeguarding industries such as food, pharmaceuticals, and cosmetics. Current performance evaluations of CDPs predominantly rely on empirical setups using simplistic metrics like Hamming distances or Pearson correlation. These methods are often inadequate due to their sensitivity to distortions, degradation, and their limitations to stationary statistics of printing and imaging. Additionally, machine learning-based approaches suffer from distribution biases and fail to generalize to unseen counterfeit samples. Given the critical importance of CDPs in preventing counterfeiting, including the counterfeit vaccines issue highlighted during the COVID-19 pandemic, there is an urgent need for provable performance guarantees across various criteria. This paper aims to establish a theoretical framework to derive optimal criteria for the analysis, optimization, and future development of CDP authentication technologies, ensuring their reliability and effectiveness in diverse security scenarios.