 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Continuous-Time Diffusion Models Generate and Solve Globally Constrained Discrete Problems? A Study on Sudoku
Jan 28, 2026Can standard continuous-time generative models represent distributions whose support is an extremely sparse, globally constrained discrete set? We study this question using completed Sudoku grids as a controlled testbed, treating them as a subset of a continuous relaxation space. We train flow-matching and score-based models along a Gaussian probability path and compare deterministic (ODE) sampling, stochastic (SDE) sampling, and DDPM-style discretizations derived from the same continuous-time training. Unconditionally, stochastic sampling substantially outperforms deterministic flows; score-based samplers are the most reliable among continuous-time methods, and DDPM-style ancestral sampling achieves the highest validity overall. We further show that the same models can be repurposed for guided generation: by repeatedly sampling completions under clamped clues and stopping when constraints are satisfied, the model acts as a probabilistic Sudoku solver. Although far less sample-efficient than classical solvers and discrete-geometry-aware diffusion methods, these experiments demonstrate that classic diffusion/flow formulations can assign non-zero probability mass to globally constrained combinatorial structures and can be used for constraint satisfaction via stochastic search.
Semi-Supervised Fine-Tuning of Vision Foundation Models with Content-Style Decomposition
Oct 02, 2024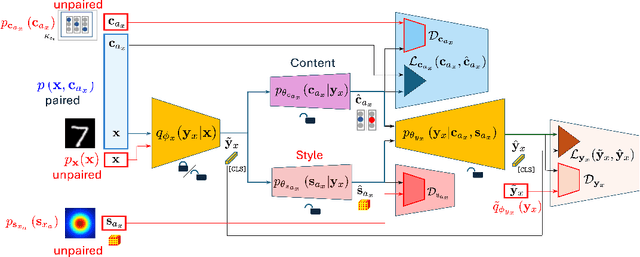



In this paper, we present a semi-supervised fine-tuning approach designed to improve the performance of foundation models on downstream tasks with limited labeled data. By leveraging content-style decomposition within an information-theoretic framework, our method enhances the latent representations of pre-trained vision foundation models, aligning them more effectively with specific task objectives and addressing the problem of distribution shift. We evaluate our approach on multiple datasets, including MNIST, its augmented variations (with yellow and white stripes), CIFAR-10, SVHN, and GalaxyMNIST. The experiments show improvements over purely supervised baselines, particularly in low-labeled data regimes, across both frozen and trainable backbones for the majority of the tested datasets.
Radio-astronomical Image Reconstruction with Conditional Denoising Diffusion Model
Feb 20, 2024Reconstructing sky models from dirty radio images for accurate source localization and flux estimation is crucial for studying galaxy evolution at high redshift, especially in deep fields using instruments like the Atacama Large Millimetre Array (ALMA). With new projects like the Square Kilometre Array (SKA), there's a growing need for better source extraction methods. Current techniques, such as CLEAN and PyBDSF, often fail to detect faint sources, highlighting the need for more accurate methods. This study proposes using stochastic neural networks to rebuild sky models directly from dirty images. This method can pinpoint radio sources and measure their fluxes with related uncertainties, marking a potential improvement in radio source characterization. We tested this approach on 10164 images simulated with the CASA tool simalma, based on ALMA's Cycle 5.3 antenna setup. We applied conditional Denoising Diffusion Probabilistic Models (DDPMs) for sky models reconstruction, then used Photutils to determine source coordinates and fluxes, assessing the model's performance across different water vapor levels. Our method showed excellence in source localization, achieving more than 90% completeness at a signal-to-noise ratio (SNR) as low as 2. It also surpassed PyBDSF in flux estimation, accurately identifying fluxes for 96% of sources in the test set, a significant improvement over CLEAN+ PyBDSF's 57%. Conditional DDPMs is a powerful tool for image-to-image translation, yielding accurate and robust characterisation of radio sources, and outperforming existing methodologies. While this study underscores its significant potential for applications in radio astronomy, we also acknowledge certain limitations that accompany its usage, suggesting directions for further refinement and research.
MV-MR: multi-views and multi-representations for self-supervised learning and knowledge distillation
Mar 21, 2023We present a new method of self-supervised learning and knowledge distillation based on the multi-views and multi-representations (MV-MR). The MV-MR is based on the maximization of dependence between learnable embeddings from augmented and non-augmented views, jointly with the maximization of dependence between learnable embeddings from augmented view and multiple non-learnable representations from non-augmented view. We show that the proposed method can be used for efficient self-supervised classification and model-agnostic knowledge distillation. Unlike other self-supervised techniques, our approach does not use any contrastive learning, clustering, or stop gradients. MV-MR is a generic framework allowing the incorporation of constraints on the learnable embeddings via the usage of image multi-representations as regularizers. Along this line, knowledge distillation is considered a particular case of such a regularization. MV-MR provides the state-of-the-art performance on the STL10 and ImageNet-1K datasets among non-contrastive and clustering-free methods. We show that a lower complexity ResNet50 model pretrained using proposed knowledge distillation based on the CLIP ViT model achieves state-of-the-art performance on STL10 linear evaluation. The code is available at: https://github.com/vkinakh/mv-mr
Turbo-Sim: a generalised generative model with a physical latent space
Dec 21, 2021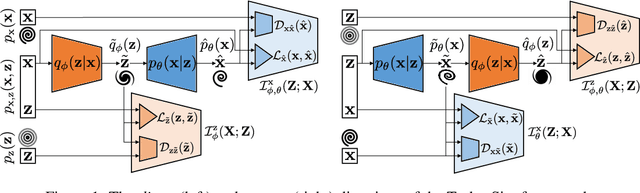


We present Turbo-Sim, a generalised autoencoder framework derived from principles of information theory that can be used as a generative model. By maximising the mutual information between the input and the output of both the encoder and the decoder, we are able to rediscover the loss terms usually found in adversarial autoencoders and generative adversarial networks, as well as various more sophisticated related models. Our generalised framework makes these models mathematically interpretable and allows for a diversity of new ones by setting the weight of each loss term separately. The framework is also independent of the intrinsic architecture of the encoder and the decoder thus leaving a wide choice for the building blocks of the whole network. We apply Turbo-Sim to a collider physics generation problem: the transformation of the properties of several particles from a theory space, right after the collision, to an observation space, right after the detection in an experiment.
Information-theoretic stochastic contrastive conditional GAN: InfoSCC-GAN
Dec 17, 2021
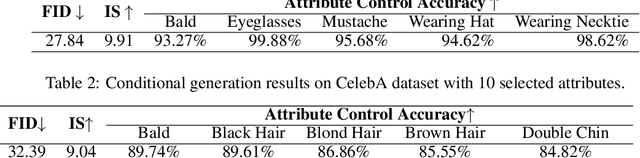
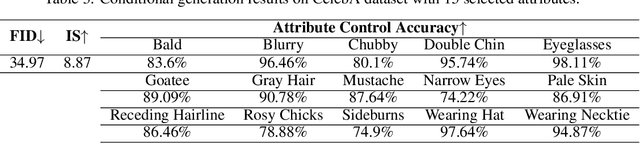
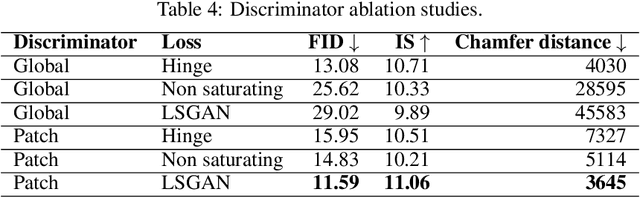
Conditional generation is a subclass of generative problems where the output of the generation is conditioned by the attribute information. In this paper, we present a stochastic contrastive conditional generative adversarial network (InfoSCC-GAN) with an explorable latent space. The InfoSCC-GAN architecture is based on an unsupervised contrastive encoder built on the InfoNCE paradigm, an attribute classifier and an EigenGAN generator. We propose a novel training method, based on generator regularization using external or internal attributes every $n$-th iteration, using a pre-trained contrastive encoder and a pre-trained classifier. The proposed InfoSCC-GAN is derived based on an information-theoretic formulation of mutual information maximization between input data and latent space representation as well as latent space and generated data. Thus, we demonstrate a link between the training objective functions and the above information-theoretic formulation. The experimental results show that InfoSCC-GAN outperforms the "vanilla" EigenGAN in the image generation on AFHQ and CelebA datasets. In addition, we investigate the impact of discriminator architectures and loss functions by performing ablation studies. Finally, we demonstrate that thanks to the EigenGAN generator, the proposed framework enjoys a stochastic generation in contrast to vanilla deterministic GANs yet with the independent training of encoder, classifier, and generator in contrast to existing frameworks. Code, experimental results, and demos are available online at https://github.com/vkinakh/InfoSCC-GAN.
Generation of data on discontinuous manifolds via continuous stochastic non-invertible networks
Dec 17, 2021
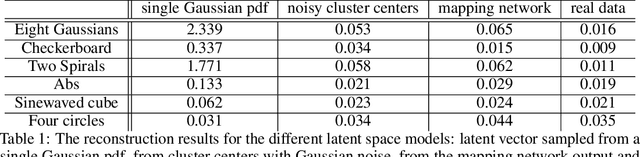

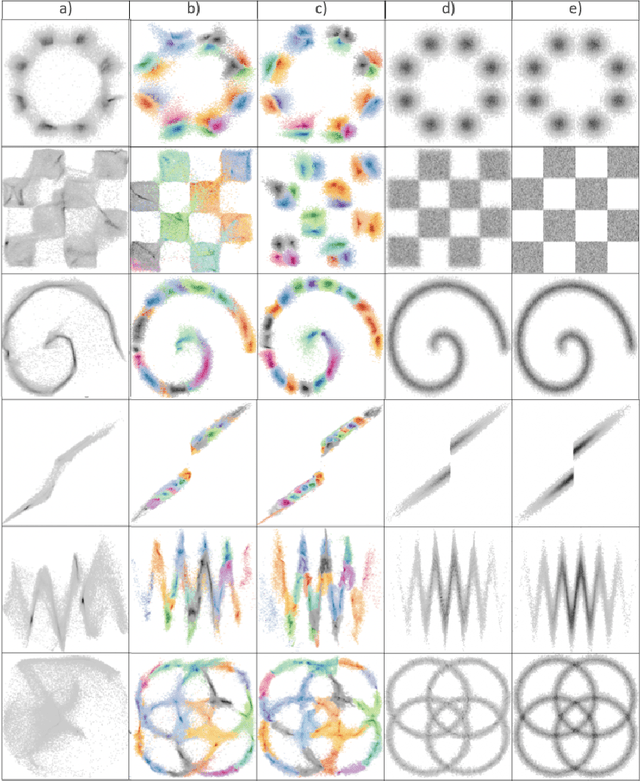
The generation of discontinuous distributions is a difficult task for most known frameworks such as generative autoencoders and generative adversarial networks. Generative non-invertible models are unable to accurately generate such distributions, require long training and often are subject to mode collapse. Variational autoencoders (VAEs), which are based on the idea of keeping the latent space to be Gaussian for the sake of a simple sampling, allow an accurate reconstruction, while they experience significant limitations at generation task. In this work, instead of trying to keep the latent space to be Gaussian, we use a pre-trained contrastive encoder to obtain a clustered latent space. Then, for each cluster, representing a unimodal submanifold, we train a dedicated low complexity network to generate this submanifold from the Gaussian distribution. The proposed framework is based on the information-theoretic formulation of mutual information maximization between the input data and latent space representation. We derive a link between the cost functions and the information-theoretic formulation. We apply our approach to synthetic 2D distributions to demonstrate both reconstruction and generation of discontinuous distributions using continuous stochastic networks.
A study of Neural networks point source extraction on simulated Fermi/LAT Telescope images
Jul 08, 2020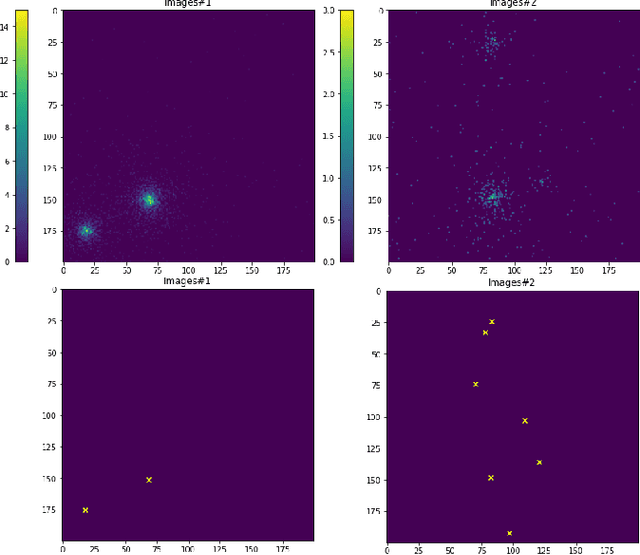
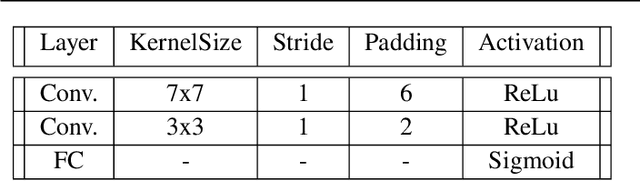
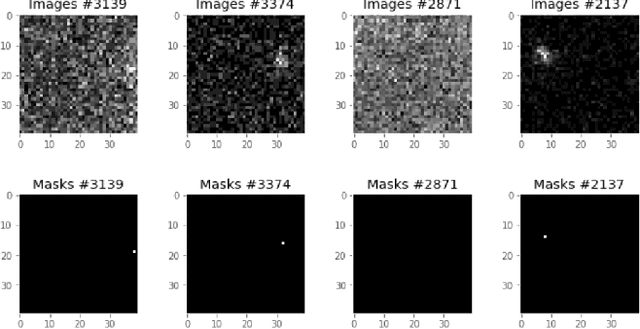
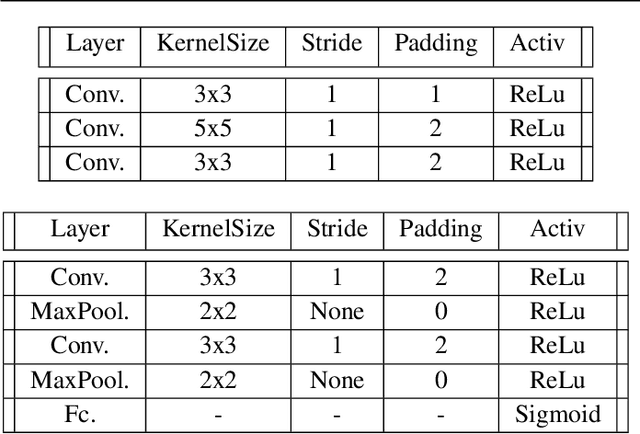
Astrophysical images in the GeV band are challenging to analyze due to the strong contribution of the background and foreground astrophysical diffuse emission and relatively broad point spread function of modern space-based instruments. In certain cases, even finding of point sources on the image becomes a non-trivial task. We present a method for point sources extraction using a convolution neural network (CNN) trained on our own artificial data set which imitates images from the Fermi Large Area Telescope. These images are raw count photon maps of 10x10 degrees covering energies from 1 to 10 GeV. We compare different CNN architectures that demonstrate accuracy increase by ~15% and reduces the inference time by at least the factor of 4 accuracy improvement with respect to a similar state of the art models.