 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Benchmarking 2D Egocentric Hand Pose Datasets
Sep 11, 2024Hand pose estimation from egocentric video has broad implications across various domains, including human-computer interaction, assistive technologies, activity recognition, and robotics, making it a topic of significant research interest. The efficacy of modern machine learning models depends on the quality of data used for their training. Thus, this work is devoted to the analysis of state-of-the-art egocentric datasets suitable for 2D hand pose estimation. We propose a novel protocol for dataset evaluation, which encompasses not only the analysis of stated dataset characteristics and assessment of data quality, but also the identification of dataset shortcomings through the evaluation of state-of-the-art hand pose estimation models. Our study reveals that despite the availability of numerous egocentric databases intended for 2D hand pose estimation, the majority are tailored for specific use cases. There is no ideal benchmark dataset yet; however, H2O and GANerated Hands datasets emerge as the most promising real and synthetic datasets, respectively.
Radio-astronomical Image Reconstruction with Conditional Denoising Diffusion Model
Feb 20, 2024Reconstructing sky models from dirty radio images for accurate source localization and flux estimation is crucial for studying galaxy evolution at high redshift, especially in deep fields using instruments like the Atacama Large Millimetre Array (ALMA). With new projects like the Square Kilometre Array (SKA), there's a growing need for better source extraction methods. Current techniques, such as CLEAN and PyBDSF, often fail to detect faint sources, highlighting the need for more accurate methods. This study proposes using stochastic neural networks to rebuild sky models directly from dirty images. This method can pinpoint radio sources and measure their fluxes with related uncertainties, marking a potential improvement in radio source characterization. We tested this approach on 10164 images simulated with the CASA tool simalma, based on ALMA's Cycle 5.3 antenna setup. We applied conditional Denoising Diffusion Probabilistic Models (DDPMs) for sky models reconstruction, then used Photutils to determine source coordinates and fluxes, assessing the model's performance across different water vapor levels. Our method showed excellence in source localization, achieving more than 90% completeness at a signal-to-noise ratio (SNR) as low as 2. It also surpassed PyBDSF in flux estimation, accurately identifying fluxes for 96% of sources in the test set, a significant improvement over CLEAN+ PyBDSF's 57%. Conditional DDPMs is a powerful tool for image-to-image translation, yielding accurate and robust characterisation of radio sources, and outperforming existing methodologies. While this study underscores its significant potential for applications in radio astronomy, we also acknowledge certain limitations that accompany its usage, suggesting directions for further refinement and research.
Stochastic Digital Twin for Copy Detection Patterns
Sep 28, 2023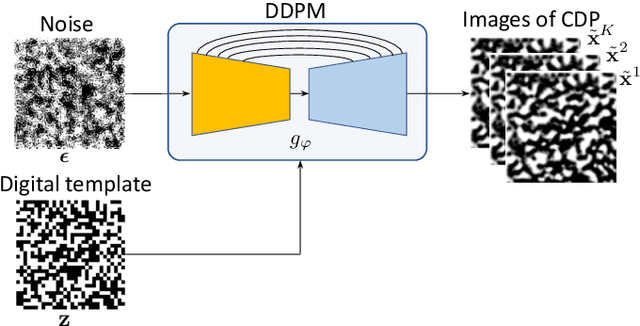


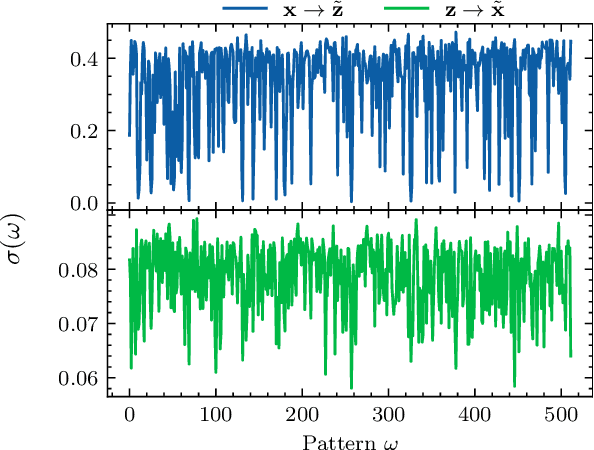
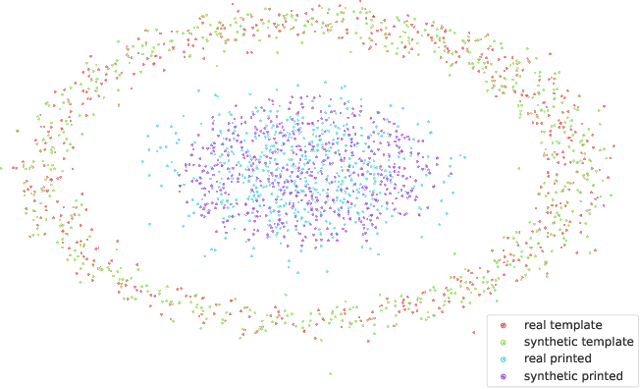
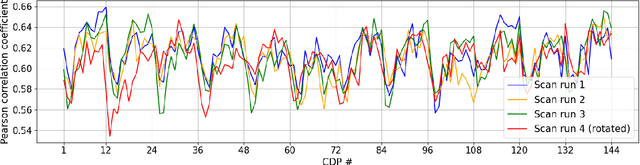
Copy detection patterns (CDP) present an efficient technique for product protection against counterfeiting. However, the complexity of studying CDP production variability often results in time-consuming and costly procedures, limiting CDP scalability. Recent advancements in computer modelling, notably the concept of a "digital twin" for printing-imaging channels, allow for enhanced scalability and the optimization of authentication systems. Yet, the development of an accurate digital twin is far from trivial. This paper extends previous research which modelled a printing-imaging channel using a machine learning-based digital twin for CDP. This model, built upon an information-theoretic framework known as "Turbo", demonstrated superior performance over traditional generative models such as CycleGAN and pix2pix. However, the emerging field of Denoising Diffusion Probabilistic Models (DDPM) presents a potential advancement in generative models due to its ability to stochastically model the inherent randomness of the printing-imaging process, and its impressive performance in image-to-image translation tasks. This study aims at comparing the capabilities of the Turbo framework and DDPM on the same CDP datasets, with the goal of establishing the real-world benefits of DDPM models for digital twin applications in CDP security. Furthermore, the paper seeks to evaluate the generative potential of the studied models in the context of mobile phone data acquisition. Despite the increased complexity of DDPM methods when compared to traditional approaches, our study highlights their advantages and explores their potential for future applications.
Mathematical model of printing-imaging channel for blind detection of fake copy detection patterns
Dec 14, 2022



Nowadays, copy detection patterns (CDP) appear as a very promising anti-counterfeiting technology for physical object protection. However, the advent of deep learning as a powerful attacking tool has shown that the general authentication schemes are unable to compete and fail against such attacks. In this paper, we propose a new mathematical model of printing-imaging channel for the authentication of CDP together with a new detection scheme based on it. The results show that even deep learning created copy fakes unknown at the training stage can be reliably authenticated based on the proposed approach and using only digital references of CDP during authentication.
Digital twins of physical printing-imaging channel
Oct 28, 2022


In this paper, we address the problem of modeling a printing-imaging channel built on a machine learning approach a.k.a. digital twin for anti-counterfeiting applications based on copy detection patterns (CDP). The digital twin is formulated on an information-theoretic framework called Turbo that uses variational approximations of mutual information developed for both encoder and decoder in a two-directional information passage. The proposed model generalizes several state-of-the-art architectures such as adversarial autoencoder (AAE), CycleGAN and adversarial latent space autoencoder (ALAE). This model can be applied to any type of printing and imaging and it only requires training data consisting of digital templates or artworks that are sent to a printing device and data acquired by an imaging device. Moreover, these data can be paired, unpaired or hybrid paired-unpaired which makes the proposed architecture very flexible and scalable to many practical setups. We demonstrate the impact of various architectural factors, metrics and discriminators on the overall system performance in the task of generation/prediction of printed CDP from their digital counterparts and vice versa. We also compare the proposed system with several state-of-the-art methods used for image-to-image translation applications.
Printing variability of copy detection patterns
Oct 11, 2022


Copy detection pattern (CDP) is a novel solution for products' protection against counterfeiting, which gains its popularity in recent years. CDP attracts the anti-counterfeiting industry due to its numerous benefits in comparison to alternative protection techniques. Besides its attractiveness, there is an essential gap in the fundamental analysis of CDP authentication performance in large-scale industrial applications. It concerns variability of CDP parameters under different production conditions that include a type of printer, substrate, printing resolution, etc. Since digital off-set printing represents great flexibility in terms of product personalized in comparison with traditional off-set printing, it looks very interesting to address the above concerns for digital off-set printers that are used by several companies for the CDP protection of physical objects. In this paper, we thoroughly investigate certain factors impacting CDP. The experimental results obtained during our study reveal some previously unknown results and raise new and even more challenging questions. The results prove that it is a matter of great importance to choose carefully the substrate or printer for CDP production. This paper presents a new dataset produced by two industrial HP Indigo printers. The similarity between printed CDP and the digital templates, from which they have been produced, is chosen as a simple measure in our study. We found several particularities that might be of interest for large-scale industrial applications.
Anomaly localization for copy detection patterns through print estimations
Sep 29, 2022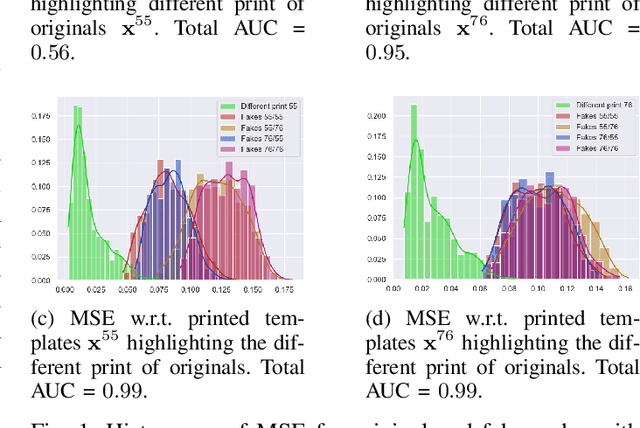
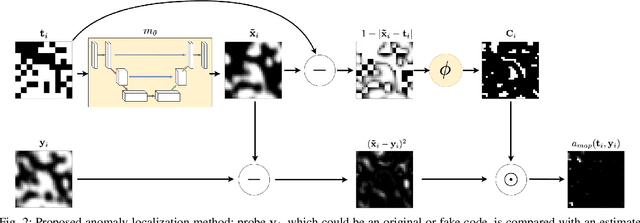
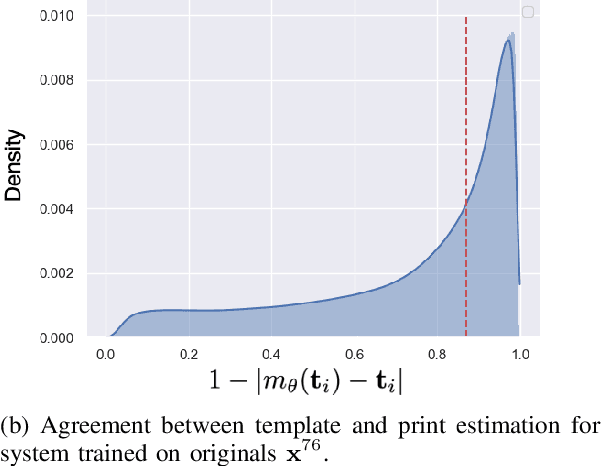
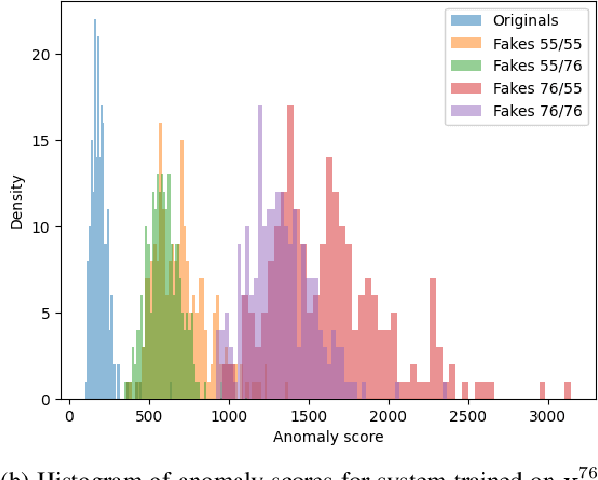
Copy detection patterns (CDP) are recent technologies for protecting products from counterfeiting. However, in contrast to traditional copy fakes, deep learning-based fakes have shown to be hardly distinguishable from originals by traditional authentication systems. Systems based on classical supervised learning and digital templates assume knowledge of fake CDP at training time and cannot generalize to unseen types of fakes. Authentication based on printed copies of originals is an alternative that yields better results even for unseen fakes and simple authentication metrics but comes at the impractical cost of acquisition and storage of printed copies. In this work, to overcome these shortcomings, we design a machine learning (ML) based authentication system that only requires digital templates and printed original CDP for training, whereas authentication is based solely on digital templates, which are used to estimate original printed codes. The obtained results show that the proposed system can efficiently authenticate original and detect fake CDP by accurately locating the anomalies in the fake CDP. The empirical evaluation of the authentication system under investigation is performed on the original and ML-based fakes CDP printed on two industrial printers.
Authentication of Copy Detection Patterns under Machine Learning Attacks: A Supervised Approach
Jun 25, 2022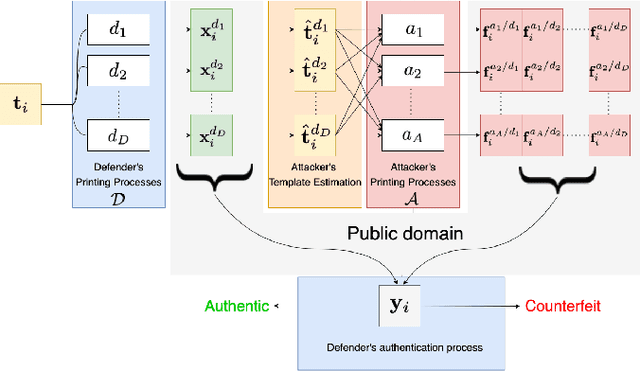
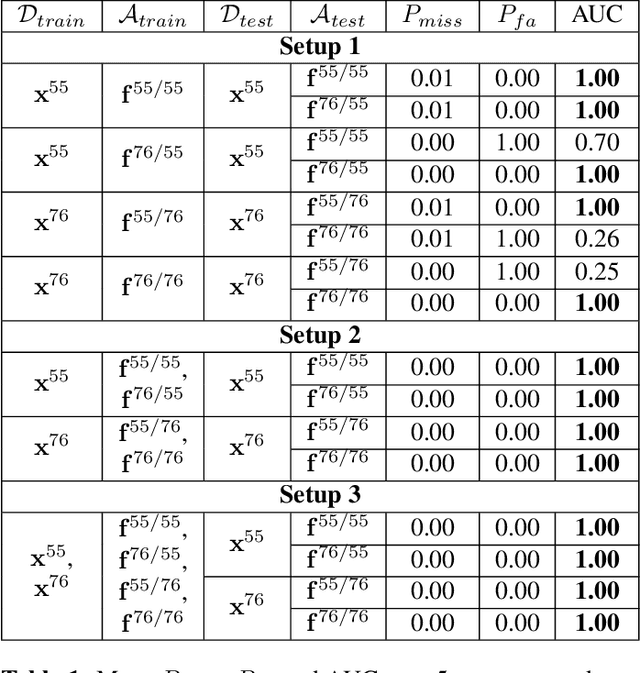
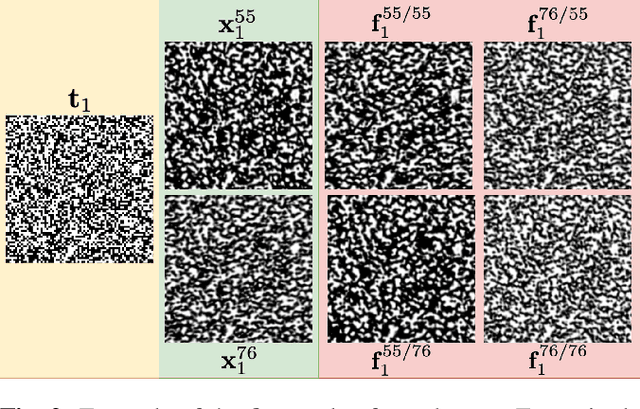
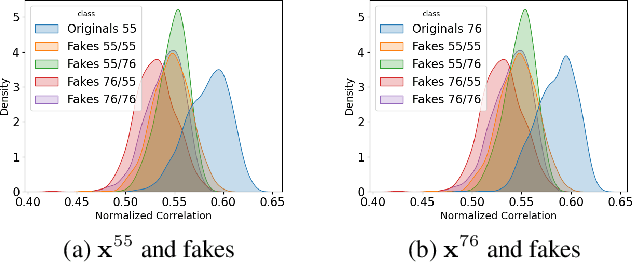
Copy detection patterns (CDP) are an attractive technology that allows manufacturers to defend their products against counterfeiting. The main assumption behind the protection mechanism of CDP is that these codes printed with the smallest symbol size (1x1) on an industrial printer cannot be copied or cloned with sufficient accuracy due to data processing inequality. However, previous works have shown that Machine Learning (ML) based attacks can produce high-quality fakes, resulting in decreased accuracy of authentication based on traditional feature-based authentication systems. While Deep Learning (DL) can be used as a part of the authentication system, to the best of our knowledge, none of the previous works has studied the performance of a DL-based authentication system against ML-based attacks on CDP with 1x1 symbol size. In this work, we study such a performance assuming a supervised learning (SL) setting.
Mobile authentication of copy detection patterns
Mar 04, 2022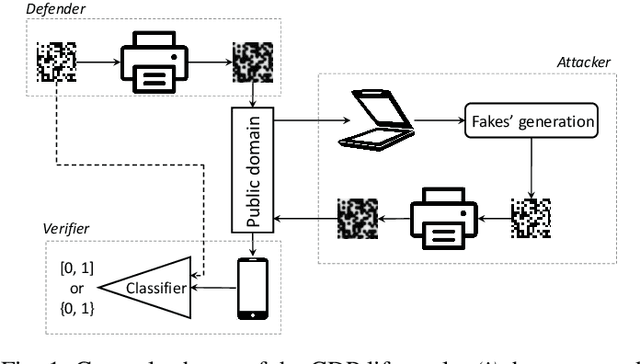

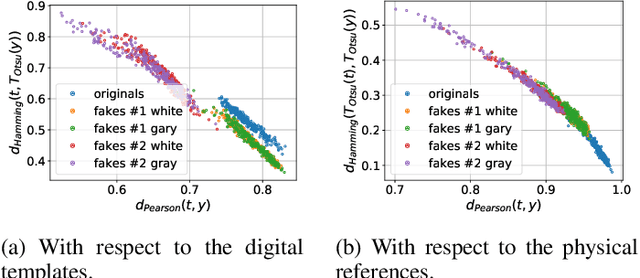
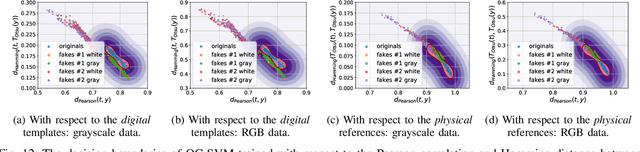
In the recent years, the copy detection patterns (CDP) attracted a lot of attention as a link between the physical and digital worlds, which is of great interest for the internet of things and brand protection applications. However, the security of CDP in terms of their reproducibility by unauthorized parties or clonability remains largely unexplored. In this respect this paper addresses a problem of anti-counterfeiting of physical objects and aims at investigating the authentication aspects and the resistances to illegal copying of the modern CDP from machine learning perspectives. A special attention is paid to a reliable authentication under the real life verification conditions when the codes are printed on an industrial printer and enrolled via modern mobile phones under regular light conditions. The theoretical and empirical investigation of authentication aspects of CDP is performed with respect to four types of copy fakes from the point of view of (i) multi-class supervised classification as a baseline approach and (ii) one-class classification as a real-life application case. The obtained results show that the modern machine-learning approaches and the technical capacities of modern mobile phones allow to reliably authenticate CDP on end-user mobile phones under the considered classes of fakes.