 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Classification: Evaluating Diffusion Denoised Smoothing for Security-Utility Trade off
May 21, 2025While foundation models demonstrate impressive performance across various tasks, they remain vulnerable to adversarial inputs. Current research explores various approaches to enhance model robustness, with Diffusion Denoised Smoothing emerging as a particularly promising technique. This method employs a pretrained diffusion model to preprocess inputs before model inference. Yet, its effectiveness remains largely unexplored beyond classification. We aim to address this gap by analyzing three datasets with four distinct downstream tasks under three different adversarial attack algorithms. Our findings reveal that while foundation models maintain resilience against conventional transformations, applying high-noise diffusion denoising to clean images without any distortions significantly degrades performance by as high as 57%. Low-noise diffusion settings preserve performance but fail to provide adequate protection across all attack types. Moreover, we introduce a novel attack strategy specifically targeting the diffusion process itself, capable of circumventing defenses in the low-noise regime. Our results suggest that the trade-off between adversarial robustness and performance remains a challenge to be addressed.
Robustness Tokens: Towards Adversarial Robustness of Transformers
Mar 13, 2025Recently, large pre-trained foundation models have become widely adopted by machine learning practitioners for a multitude of tasks. Given that such models are publicly available, relying on their use as backbone models for downstream tasks might result in high vulnerability to adversarial attacks crafted with the same public model. In this work, we propose Robustness Tokens, a novel approach specific to the transformer architecture that fine-tunes a few additional private tokens with low computational requirements instead of tuning model parameters as done in traditional adversarial training. We show that Robustness Tokens make Vision Transformer models significantly more robust to white-box adversarial attacks while also retaining the original downstream performances.
* This paper has been accepted for publication at the European Conference on Computer Vision (ECCV), 2024
Task-Agnostic Attacks Against Vision Foundation Models
Mar 05, 2025
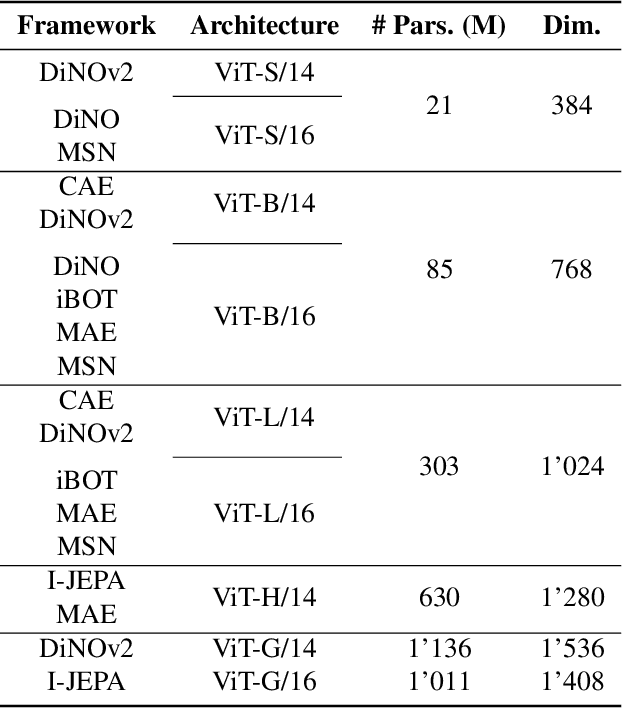
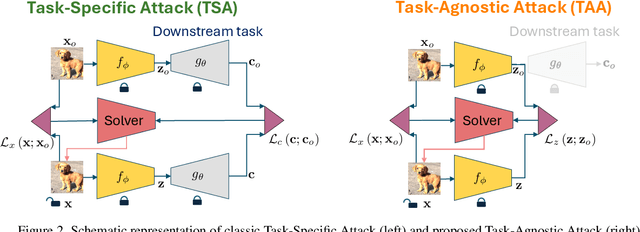
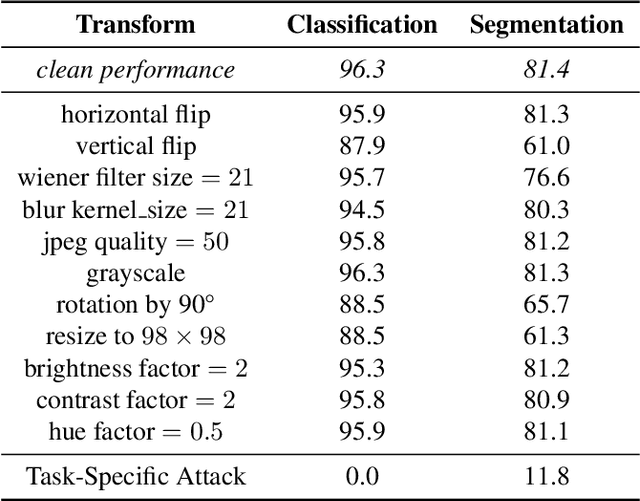
The study of security in machine learning mainly focuses on downstream task-specific attacks, where the adversarial example is obtained by optimizing a loss function specific to the downstream task. At the same time, it has become standard practice for machine learning practitioners to adopt publicly available pre-trained vision foundation models, effectively sharing a common backbone architecture across a multitude of applications such as classification, segmentation, depth estimation, retrieval, question-answering and more. The study of attacks on such foundation models and their impact to multiple downstream tasks remains vastly unexplored. This work proposes a general framework that forges task-agnostic adversarial examples by maximally disrupting the feature representation obtained with foundation models. We extensively evaluate the security of the feature representations obtained by popular vision foundation models by measuring the impact of this attack on multiple downstream tasks and its transferability between models.
Semi-Supervised Fine-Tuning of Vision Foundation Models with Content-Style Decomposition
Oct 02, 2024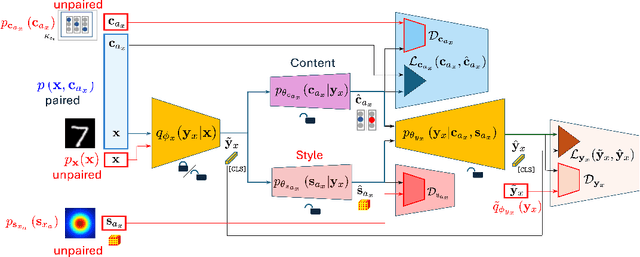



In this paper, we present a semi-supervised fine-tuning approach designed to improve the performance of foundation models on downstream tasks with limited labeled data. By leveraging content-style decomposition within an information-theoretic framework, our method enhances the latent representations of pre-trained vision foundation models, aligning them more effectively with specific task objectives and addressing the problem of distribution shift. We evaluate our approach on multiple datasets, including MNIST, its augmented variations (with yellow and white stripes), CIFAR-10, SVHN, and GalaxyMNIST. The experiments show improvements over purely supervised baselines, particularly in low-labeled data regimes, across both frozen and trainable backbones for the majority of the tested datasets.
Evaluation of Security of ML-based Watermarking: Copy and Removal Attacks
Sep 26, 2024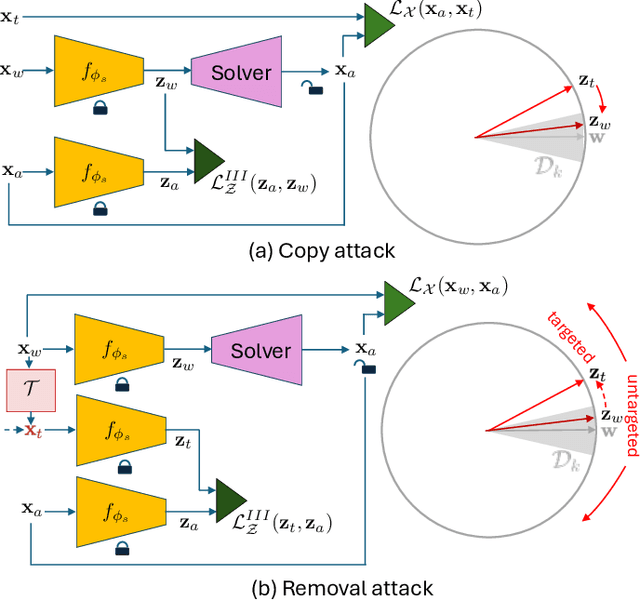
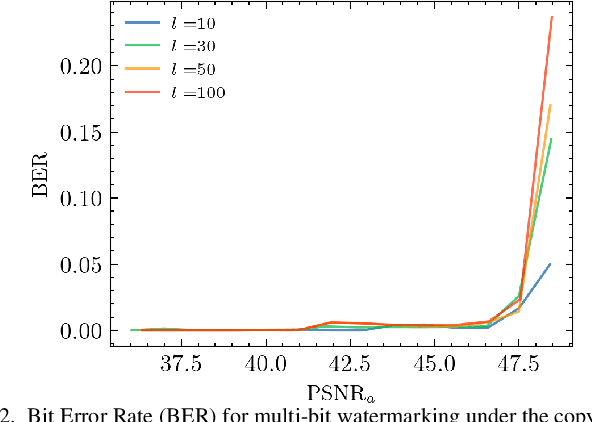
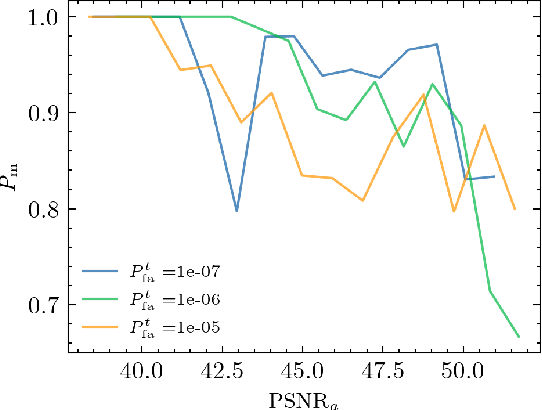
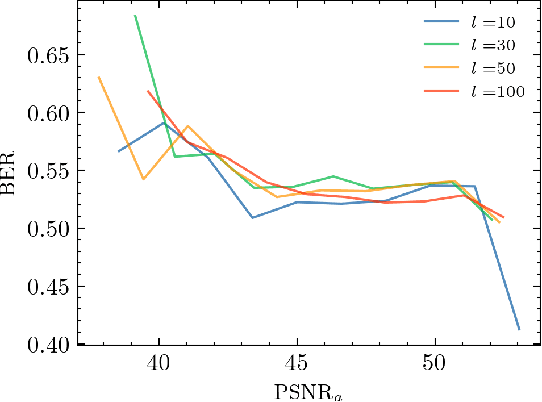
The vast amounts of digital content captured from the real world or AI-generated media necessitate methods for copyright protection, traceability, or data provenance verification. Digital watermarking serves as a crucial approach to address these challenges. Its evolution spans three generations: handcrafted, autoencoder-based, and foundation model based methods. %Its evolution spans three generations: handcrafted methods, autoencoder-based schemes, and methods based on foundation models. While the robustness of these systems is well-documented, the security against adversarial attacks remains underexplored. This paper evaluates the security of foundation models' latent space digital watermarking systems that utilize adversarial embedding techniques. A series of experiments investigate the security dimensions under copy and removal attacks, providing empirical insights into these systems' vulnerabilities. All experimental codes and results are available at https://github.com/vkinakh/ssl-watermarking-attacks}{repository
TURBO: The Swiss Knife of Auto-Encoders
Nov 11, 2023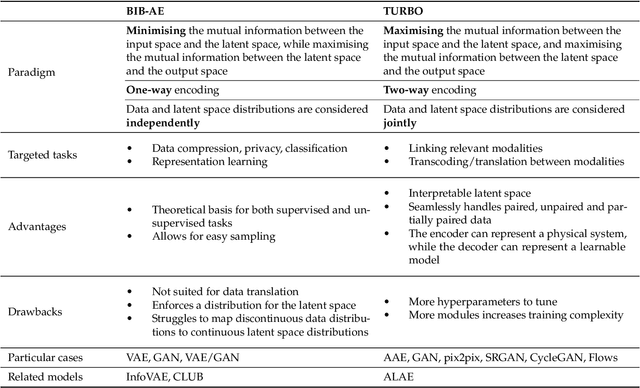
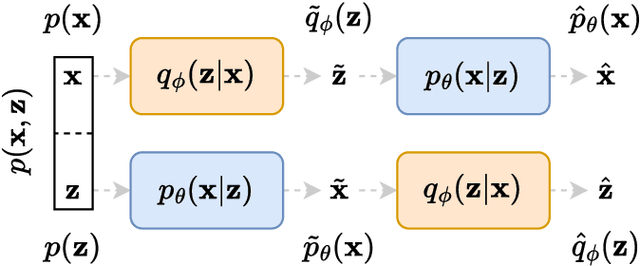
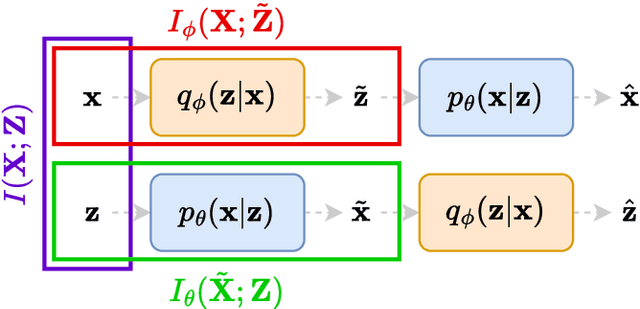

We present a novel information-theoretic framework, termed as TURBO, designed to systematically analyse and generalise auto-encoding methods. We start by examining the principles of information bottleneck and bottleneck-based networks in the auto-encoding setting and identifying their inherent limitations, which become more prominent for data with multiple relevant, physics-related representations. The TURBO framework is then introduced, providing a comprehensive derivation of its core concept consisting of the maximisation of mutual information between various data representations expressed in two directions reflecting the information flows. We illustrate that numerous prevalent neural network models are encompassed within this framework. The paper underscores the insufficiency of the information bottleneck concept in elucidating all such models, thereby establishing TURBO as a preferable theoretical reference. The introduction of TURBO contributes to a richer understanding of data representation and the structure of neural network models, enabling more efficient and versatile applications.
Stochastic Digital Twin for Copy Detection Patterns
Sep 28, 2023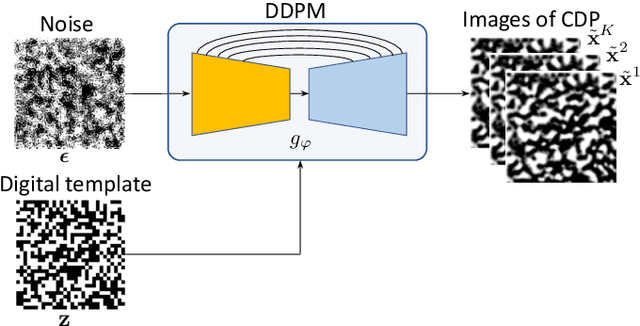


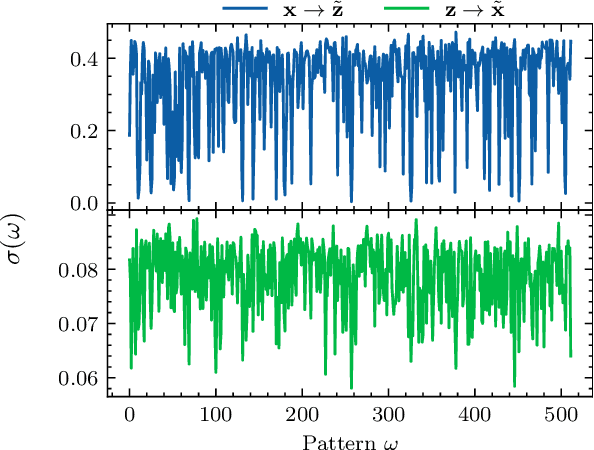
Copy detection patterns (CDP) present an efficient technique for product protection against counterfeiting. However, the complexity of studying CDP production variability often results in time-consuming and costly procedures, limiting CDP scalability. Recent advancements in computer modelling, notably the concept of a "digital twin" for printing-imaging channels, allow for enhanced scalability and the optimization of authentication systems. Yet, the development of an accurate digital twin is far from trivial. This paper extends previous research which modelled a printing-imaging channel using a machine learning-based digital twin for CDP. This model, built upon an information-theoretic framework known as "Turbo", demonstrated superior performance over traditional generative models such as CycleGAN and pix2pix. However, the emerging field of Denoising Diffusion Probabilistic Models (DDPM) presents a potential advancement in generative models due to its ability to stochastically model the inherent randomness of the printing-imaging process, and its impressive performance in image-to-image translation tasks. This study aims at comparing the capabilities of the Turbo framework and DDPM on the same CDP datasets, with the goal of establishing the real-world benefits of DDPM models for digital twin applications in CDP security. Furthermore, the paper seeks to evaluate the generative potential of the studied models in the context of mobile phone data acquisition. Despite the increased complexity of DDPM methods when compared to traditional approaches, our study highlights their advantages and explores their potential for future applications.
Mathematical model of printing-imaging channel for blind detection of fake copy detection patterns
Dec 14, 2022



Nowadays, copy detection patterns (CDP) appear as a very promising anti-counterfeiting technology for physical object protection. However, the advent of deep learning as a powerful attacking tool has shown that the general authentication schemes are unable to compete and fail against such attacks. In this paper, we propose a new mathematical model of printing-imaging channel for the authentication of CDP together with a new detection scheme based on it. The results show that even deep learning created copy fakes unknown at the training stage can be reliably authenticated based on the proposed approach and using only digital references of CDP during authentication.
Solving the Weather4cast Challenge via Visual Transformers for 3D Images
Dec 05, 2022Accurately forecasting the weather is an important task, as many real-world processes and decisions depend on future meteorological conditions. The NeurIPS 2022 challenge entitled Weather4cast poses the problem of predicting rainfall events for the next eight hours given the preceding hour of satellite observations as a context. Motivated by the recent success of transformer-based architectures in computer vision, we implement and propose two methodologies based on this architecture to tackle this challenge. We find that ensembling different transformers with some baseline models achieves the best performance we could measure on the unseen test data. Our approach has been ranked 3rd in the competition.
Digital twins of physical printing-imaging channel
Oct 28, 2022
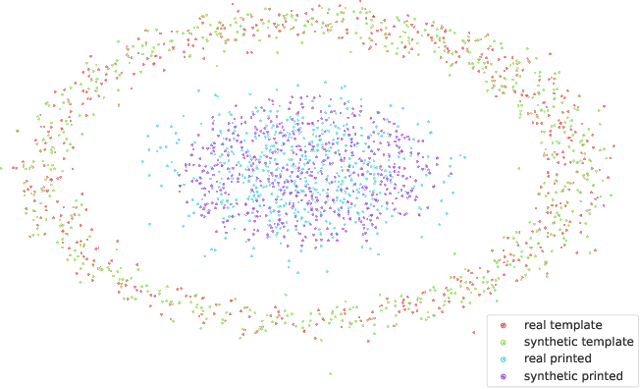


In this paper, we address the problem of modeling a printing-imaging channel built on a machine learning approach a.k.a. digital twin for anti-counterfeiting applications based on copy detection patterns (CDP). The digital twin is formulated on an information-theoretic framework called Turbo that uses variational approximations of mutual information developed for both encoder and decoder in a two-directional information passage. The proposed model generalizes several state-of-the-art architectures such as adversarial autoencoder (AAE), CycleGAN and adversarial latent space autoencoder (ALAE). This model can be applied to any type of printing and imaging and it only requires training data consisting of digital templates or artworks that are sent to a printing device and data acquired by an imaging device. Moreover, these data can be paired, unpaired or hybrid paired-unpaired which makes the proposed architecture very flexible and scalable to many practical setups. We demonstrate the impact of various architectural factors, metrics and discriminators on the overall system performance in the task of generation/prediction of printed CDP from their digital counterparts and vice versa. We also compare the proposed system with several state-of-the-art methods used for image-to-image translation applications.