 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinTURBO: Semi-Supervised Fine-Tuning of Foundation Models via Mutual Information Decompositions for Downstream Task and Latent Spaces
Mar 10, 2025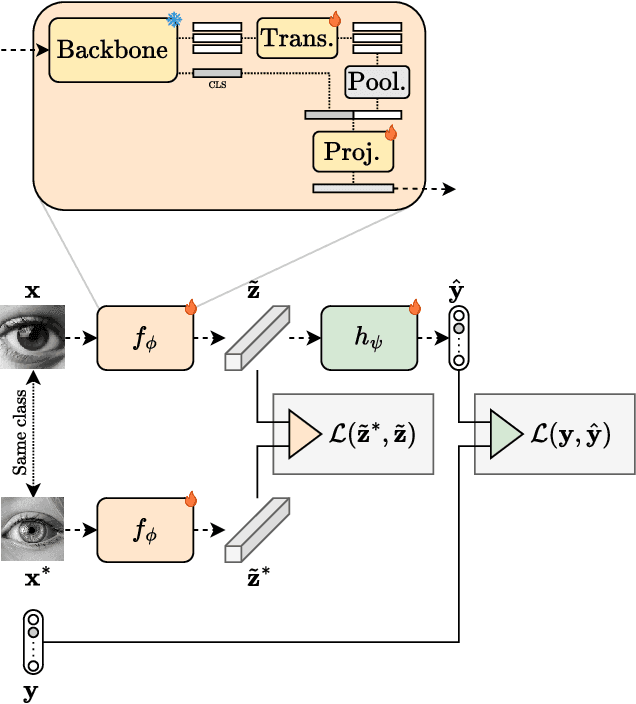
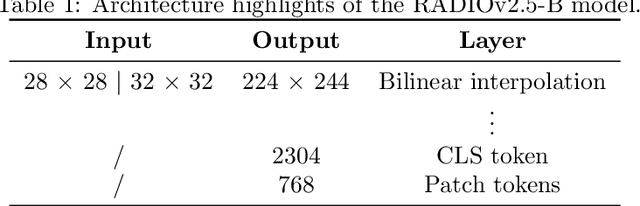
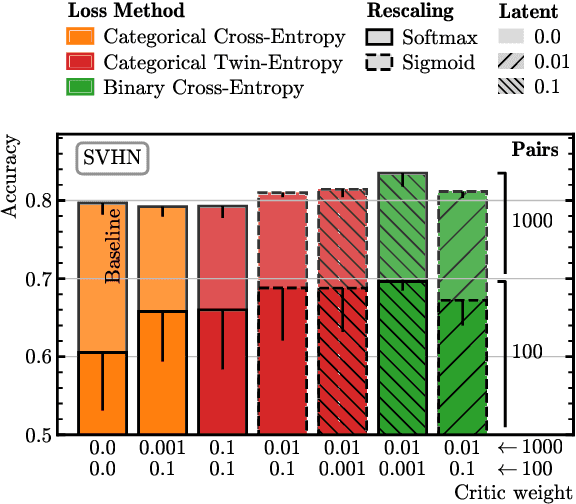

We present a semi-supervised fine-tuning framework for foundation models that utilises mutual information decomposition to address the challenges of training for a limited amount of labelled data. Our approach derives two distinct lower bounds: i) for the downstream task space, such as classification, optimised using conditional and marginal cross-entropy alongside Kullback-Leibler divergence, and ii) for the latent space representation, regularised and aligned using a contrastive-like decomposition. This fine-tuning strategy retains the pre-trained structure of the foundation model, modifying only a specialised projector module comprising a small transformer and a token aggregation technique. Experiments on several datasets demonstrate significant improvements in classification tasks under extremely low-labelled conditions by effectively leveraging unlabelled data.
PIPPIN: Generating variable length full events from partons
Jun 18, 2024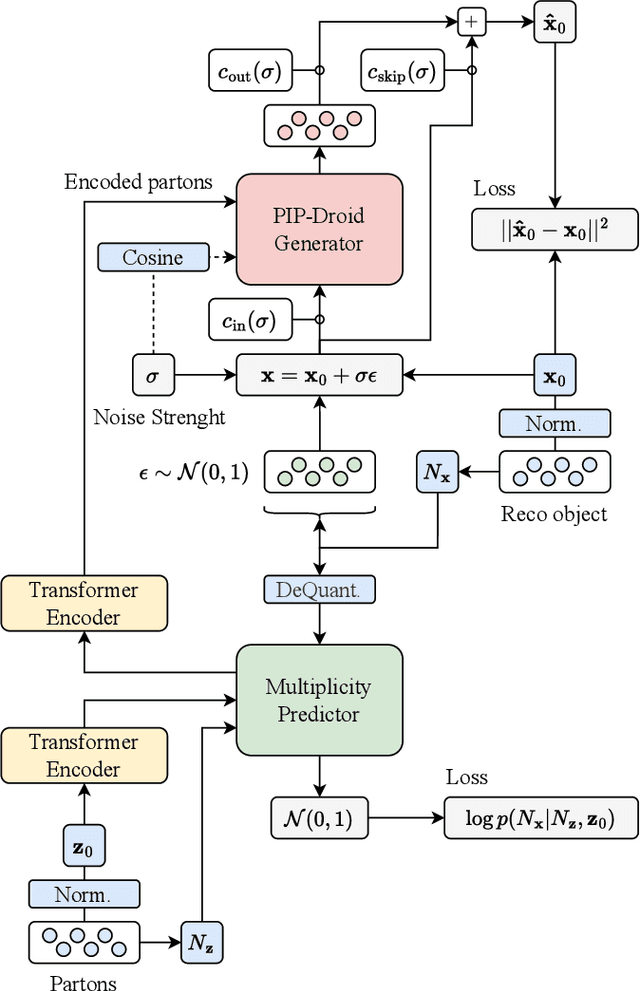
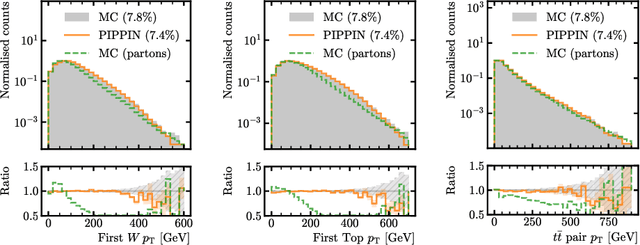
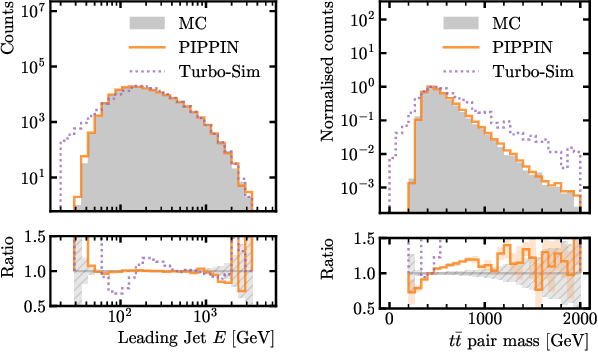
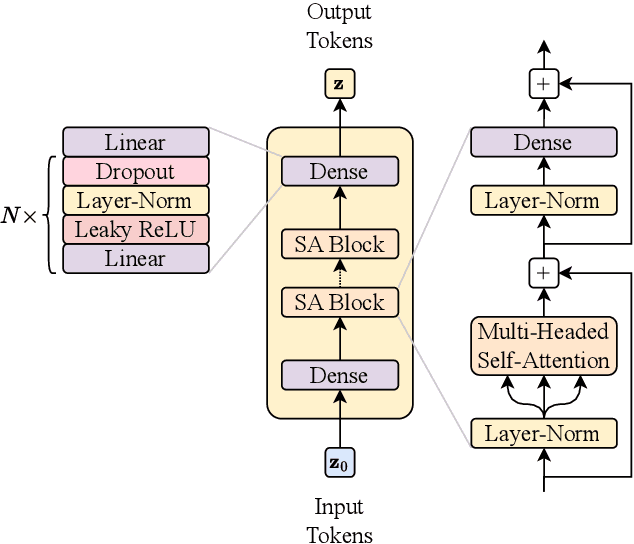
This paper presents a novel approach for directly generating full events at detector-level from parton-level information, leveraging cutting-edge machine learning techniques. To address the challenge of multiplicity variations between parton and reconstructed object spaces, we employ transformers, score-based models and normalizing flows. Our method tackles the inherent complexities of the stochastic transition between these two spaces and achieves remarkably accurate results. The combination of innovative techniques and the achieved accuracy demonstrates the potential of our approach in advancing the field and opens avenues for further exploration. This research contributes to the ongoing efforts in high-energy physics and generative modelling, providing a promising direction for enhanced precision in fast detector simulation.
TURBO: The Swiss Knife of Auto-Encoders
Nov 11, 2023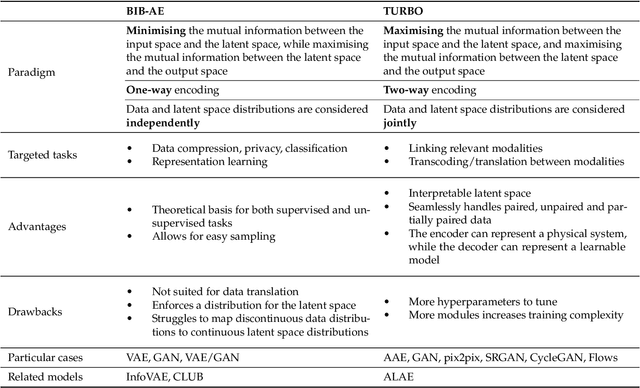
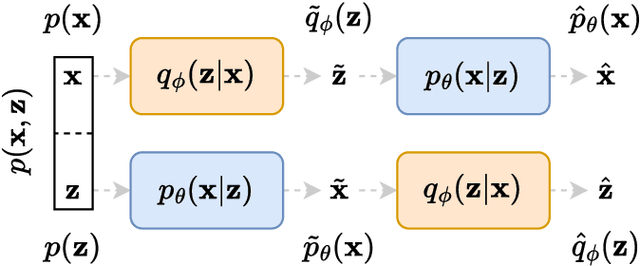
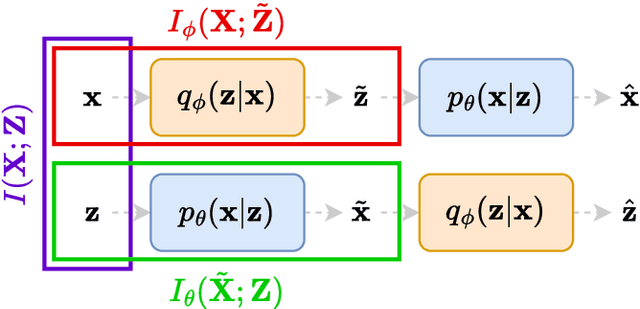

We present a novel information-theoretic framework, termed as TURBO, designed to systematically analyse and generalise auto-encoding methods. We start by examining the principles of information bottleneck and bottleneck-based networks in the auto-encoding setting and identifying their inherent limitations, which become more prominent for data with multiple relevant, physics-related representations. The TURBO framework is then introduced, providing a comprehensive derivation of its core concept consisting of the maximisation of mutual information between various data representations expressed in two directions reflecting the information flows. We illustrate that numerous prevalent neural network models are encompassed within this framework. The paper underscores the insufficiency of the information bottleneck concept in elucidating all such models, thereby establishing TURBO as a preferable theoretical reference. The introduction of TURBO contributes to a richer understanding of data representation and the structure of neural network models, enabling more efficient and versatile applications.
EPiC-ly Fast Particle Cloud Generation with Flow-Matching and Diffusion
Sep 29, 2023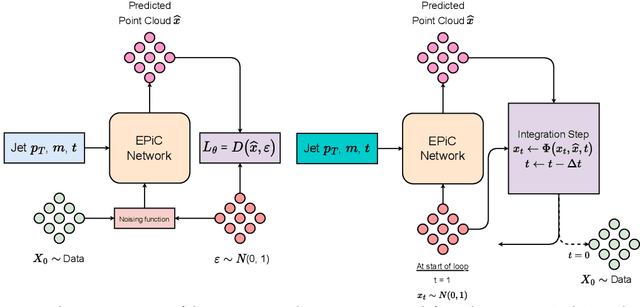
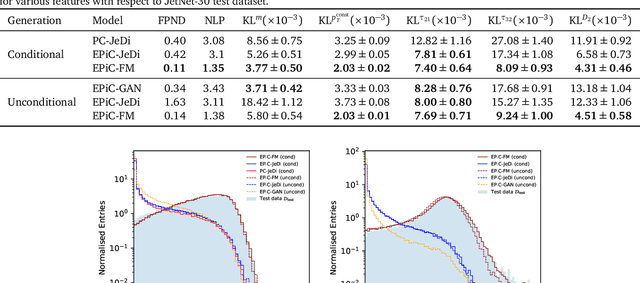
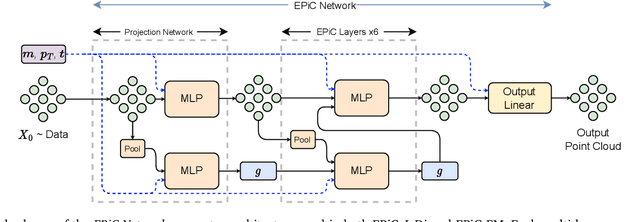

Jets at the LHC, typically consisting of a large number of highly correlated particles, are a fascinating laboratory for deep generative modeling. In this paper, we present two novel methods that generate LHC jets as point clouds efficiently and accurately. We introduce \epcjedi, which combines score-matching diffusion models with the Equivariant Point Cloud (EPiC) architecture based on the deep sets framework. This model offers a much faster alternative to previous transformer-based diffusion models without reducing the quality of the generated jets. In addition, we introduce \epcfm, the first permutation equivariant continuous normalizing flow (CNF) for particle cloud generation. This model is trained with {\it flow-matching}, a scalable and easy-to-train objective based on optimal transport that directly regresses the vector fields connecting the Gaussian noise prior to the data distribution. Our experiments demonstrate that \epcjedi and \epcfm both achieve state-of-the-art performance on the top-quark JetNet datasets whilst maintaining fast generation speed. Most notably, we find that the \epcfm model consistently outperforms all the other generative models considered here across every metric. Finally, we also introduce two new particle cloud performance metrics: the first based on the Kullback-Leibler divergence between feature distributions, the second is the negative log-posterior of a multi-model ParticleNet classifier.
PC-Droid: Faster diffusion and improved quality for particle cloud generation
Jul 14, 2023Building on the success of PC-JeDi we introduce PC-Droid, a substantially improved diffusion model for the generation of jet particle clouds. By leveraging a new diffusion formulation, studying more recent integration solvers, and training on all jet types simultaneously, we are able to achieve state-of-the-art performance for all types of jets across all evaluation metrics. We study the trade-off between generation speed and quality by comparing two attention based architectures, as well as the potential of consistency distillation to reduce the number of diffusion steps. Both the faster architecture and consistency models demonstrate performance surpassing many competing models, with generation time up to two orders of magnitude faster than PC-JeDi.
PC-JeDi: Diffusion for Particle Cloud Generation in High Energy Physics
Mar 09, 2023



In this paper, we present a new method to efficiently generate jets in High Energy Physics called PC-JeDi. This method utilises score-based diffusion models in conjunction with transformers which are well suited to the task of generating jets as particle clouds due to their permutation equivariance. PC-JeDi achieves competitive performance with current state-of-the-art methods across several metrics that evaluate the quality of the generated jets. Although slower than other models, due to the large number of forward passes required by diffusion models, it is still substantially faster than traditional detailed simulation. Furthermore, PC-JeDi uses conditional generation to produce jets with a desired mass and transverse momentum for two different particles, top quarks and gluons.
Turbo-Sim: a generalised generative model with a physical latent space
Dec 21, 2021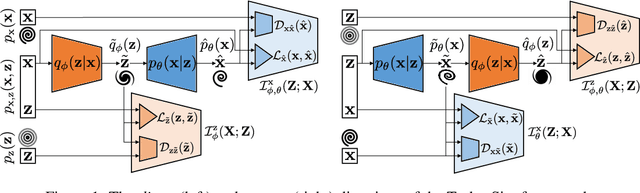


We present Turbo-Sim, a generalised autoencoder framework derived from principles of information theory that can be used as a generative model. By maximising the mutual information between the input and the output of both the encoder and the decoder, we are able to rediscover the loss terms usually found in adversarial autoencoders and generative adversarial networks, as well as various more sophisticated related models. Our generalised framework makes these models mathematically interpretable and allows for a diversity of new ones by setting the weight of each loss term separately. The framework is also independent of the intrinsic architecture of the encoder and the decoder thus leaving a wide choice for the building blocks of the whole network. We apply Turbo-Sim to a collider physics generation problem: the transformation of the properties of several particles from a theory space, right after the collision, to an observation space, right after the detection in an experiment.
Information-theoretic stochastic contrastive conditional GAN: InfoSCC-GAN
Dec 17, 2021
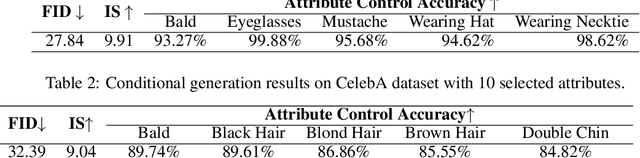
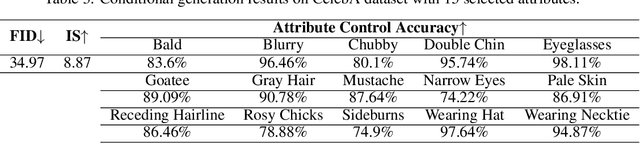
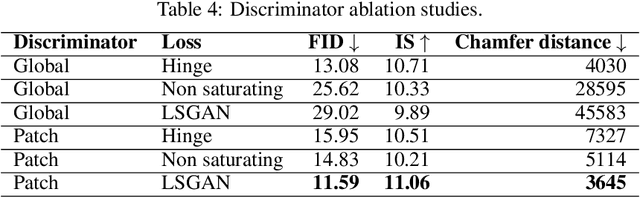
Conditional generation is a subclass of generative problems where the output of the generation is conditioned by the attribute information. In this paper, we present a stochastic contrastive conditional generative adversarial network (InfoSCC-GAN) with an explorable latent space. The InfoSCC-GAN architecture is based on an unsupervised contrastive encoder built on the InfoNCE paradigm, an attribute classifier and an EigenGAN generator. We propose a novel training method, based on generator regularization using external or internal attributes every $n$-th iteration, using a pre-trained contrastive encoder and a pre-trained classifier. The proposed InfoSCC-GAN is derived based on an information-theoretic formulation of mutual information maximization between input data and latent space representation as well as latent space and generated data. Thus, we demonstrate a link between the training objective functions and the above information-theoretic formulation. The experimental results show that InfoSCC-GAN outperforms the "vanilla" EigenGAN in the image generation on AFHQ and CelebA datasets. In addition, we investigate the impact of discriminator architectures and loss functions by performing ablation studies. Finally, we demonstrate that thanks to the EigenGAN generator, the proposed framework enjoys a stochastic generation in contrast to vanilla deterministic GANs yet with the independent training of encoder, classifier, and generator in contrast to existing frameworks. Code, experimental results, and demos are available online at https://github.com/vkinakh/InfoSCC-GAN.
Generation of data on discontinuous manifolds via continuous stochastic non-invertible networks
Dec 17, 2021
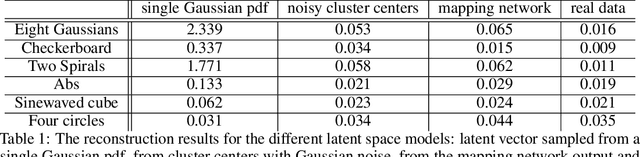

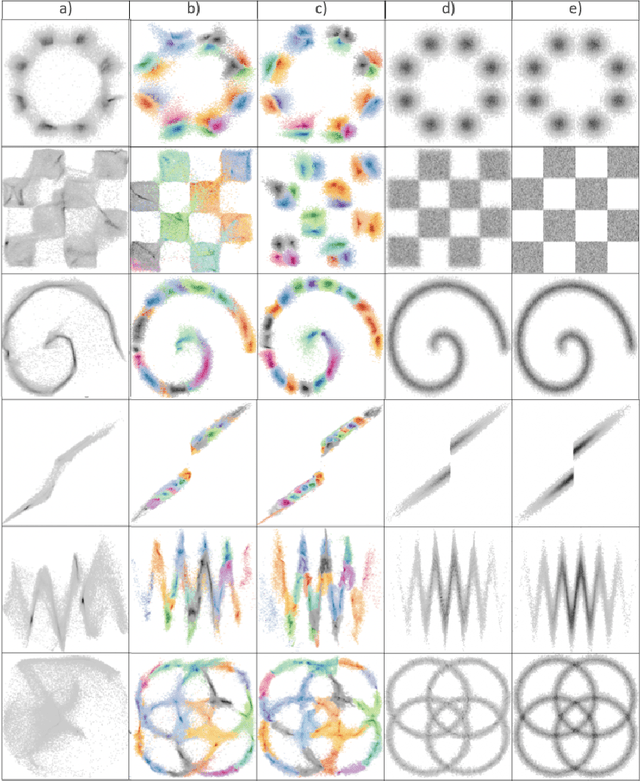
The generation of discontinuous distributions is a difficult task for most known frameworks such as generative autoencoders and generative adversarial networks. Generative non-invertible models are unable to accurately generate such distributions, require long training and often are subject to mode collapse. Variational autoencoders (VAEs), which are based on the idea of keeping the latent space to be Gaussian for the sake of a simple sampling, allow an accurate reconstruction, while they experience significant limitations at generation task. In this work, instead of trying to keep the latent space to be Gaussian, we use a pre-trained contrastive encoder to obtain a clustered latent space. Then, for each cluster, representing a unimodal submanifold, we train a dedicated low complexity network to generate this submanifold from the Gaussian distribution. The proposed framework is based on the information-theoretic formulation of mutual information maximization between the input data and latent space representation. We derive a link between the cost functions and the information-theoretic formulation. We apply our approach to synthetic 2D distributions to demonstrate both reconstruction and generation of discontinuous distributions using continuous stochastic networks.