 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational inference for pile-up removal at hadron colliders with diffusion models
Oct 29, 2024In this paper, we present a novel method for pile-up removal of pp interactions using variational inference with diffusion models, called Vipr. Instead of using classification methods to identify which particles are from the primary collision, a generative model is trained to predict the constituents of the hard-scatter particle jets with pile-up removed. This results in an estimate of the full posterior over hard-scatter jet constituents, which has not yet been explored in the context of pile-up removal. We evaluate the performance of Vipr in a sample of jets from simulated $t\bar{t}$ events overlain with pile-up contamination. Vipr outperforms SoftDrop in predicting the substructure of the hard-scatter jets over a wide range of pile-up scenarios.
PIPPIN: Generating variable length full events from partons
Jun 18, 2024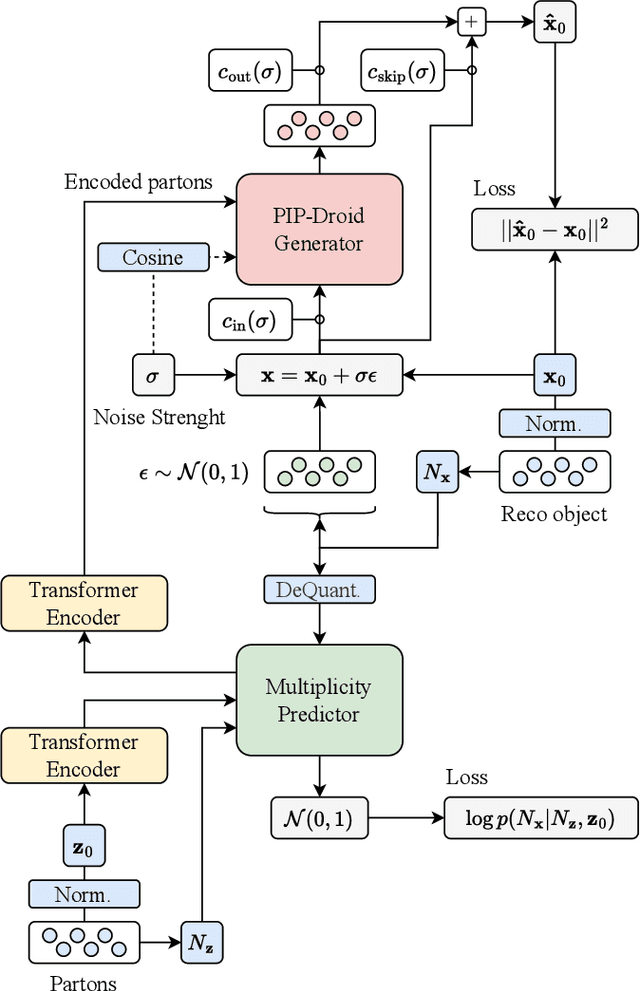
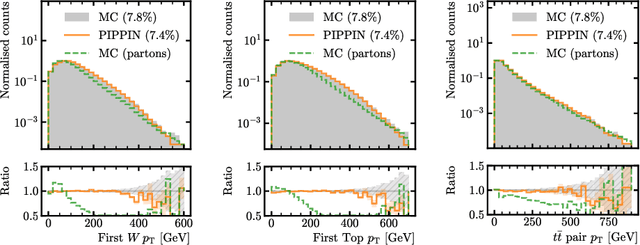
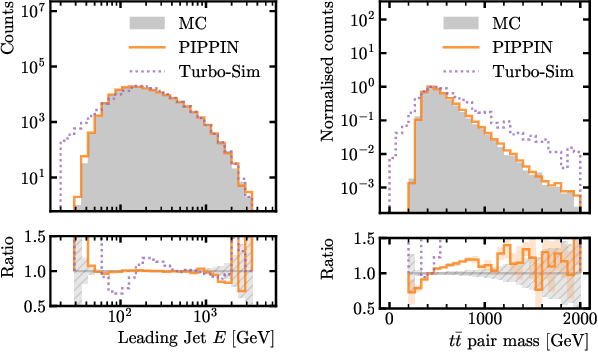
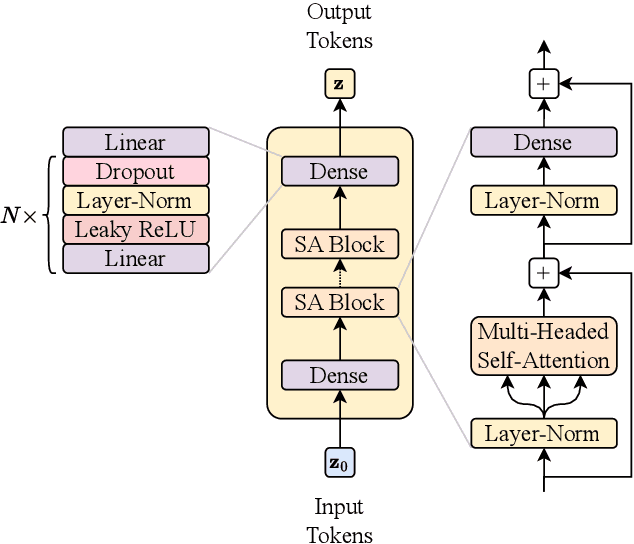
This paper presents a novel approach for directly generating full events at detector-level from parton-level information, leveraging cutting-edge machine learning techniques. To address the challenge of multiplicity variations between parton and reconstructed object spaces, we employ transformers, score-based models and normalizing flows. Our method tackles the inherent complexities of the stochastic transition between these two spaces and achieves remarkably accurate results. The combination of innovative techniques and the achieved accuracy demonstrates the potential of our approach in advancing the field and opens avenues for further exploration. This research contributes to the ongoing efforts in high-energy physics and generative modelling, providing a promising direction for enhanced precision in fast detector simulation.
Masked Particle Modeling on Sets: Towards Self-Supervised High Energy Physics Foundation Models
Jan 25, 2024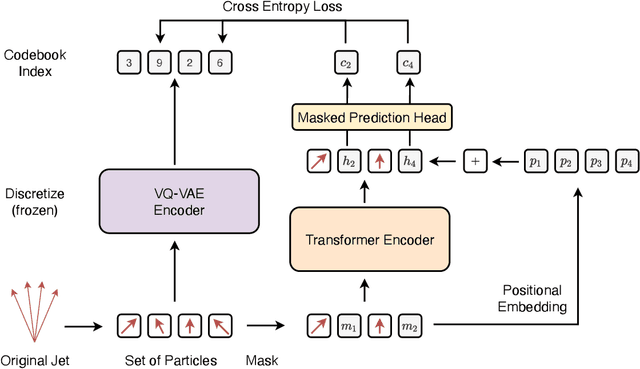
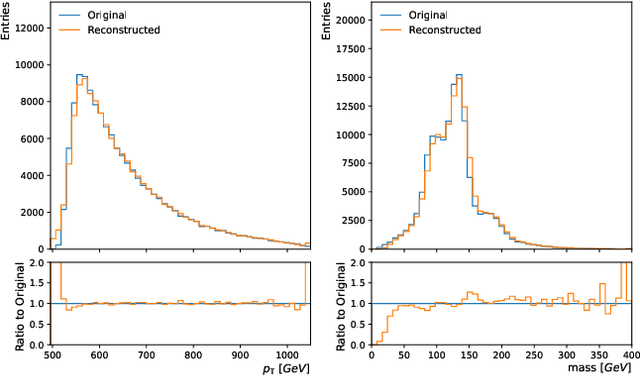
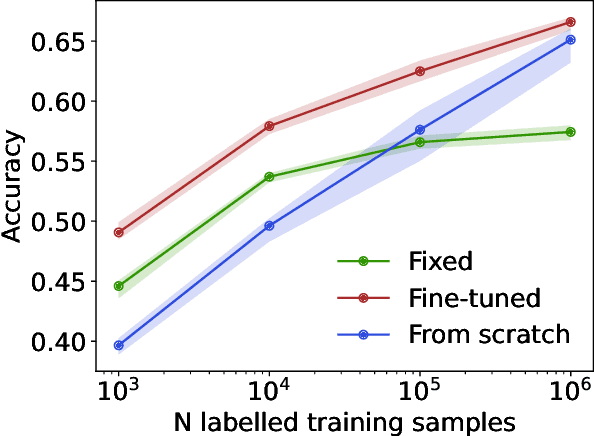
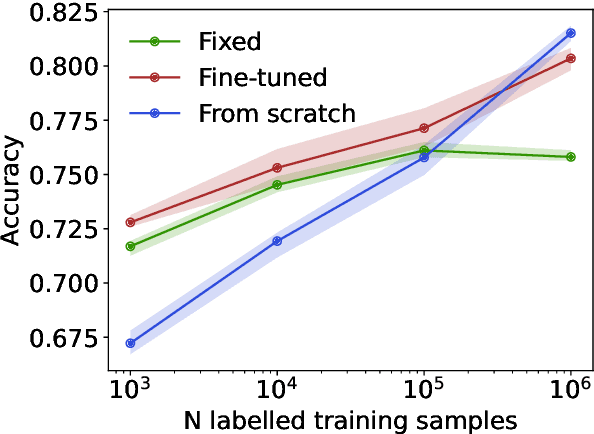
We propose masked particle modeling (MPM) as a self-supervised method for learning generic, transferable, and reusable representations on unordered sets of inputs for use in high energy physics (HEP) scientific data. This work provides a novel scheme to perform masked modeling based pre-training to learn permutation invariant functions on sets. More generally, this work provides a step towards building large foundation models for HEP that can be generically pre-trained with self-supervised learning and later fine-tuned for a variety of down-stream tasks. In MPM, particles in a set are masked and the training objective is to recover their identity, as defined by a discretized token representation of a pre-trained vector quantized variational autoencoder. We study the efficacy of the method in samples of high energy jets at collider physics experiments, including studies on the impact of discretization, permutation invariance, and ordering. We also study the fine-tuning capability of the model, showing that it can be adapted to tasks such as supervised and weakly supervised jet classification, and that the model can transfer efficiently with small fine-tuning data sets to new classes and new data domains.
Improving new physics searches with diffusion models for event observables and jet constituents
Dec 19, 2023



We introduce a new technique called Drapes to enhance the sensitivity in searches for new physics at the LHC. By training diffusion models on side-band data, we show how background templates for the signal region can be generated either directly from noise, or by partially applying the diffusion process to existing data. In the partial diffusion case, data can be drawn from side-band regions, with the inverse diffusion performed for new target conditional values, or from the signal region, preserving the distribution over the conditional property that defines the signal region. We apply this technique to the hunt for resonances using the LHCO di-jet dataset, and achieve state-of-the-art performance for background template generation using high level input features. We also show how Drapes can be applied to low level inputs with jet constituents, reducing the model dependence on the choice of input observables. Using jet constituents we can further improve sensitivity to the signal process, but observe a loss in performance where the signal significance before applying any selection is below 4$\sigma$.
EPiC-ly Fast Particle Cloud Generation with Flow-Matching and Diffusion
Sep 29, 2023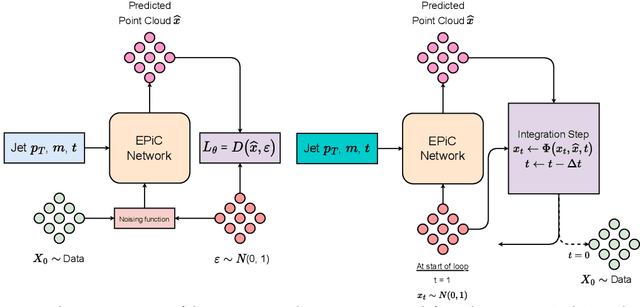
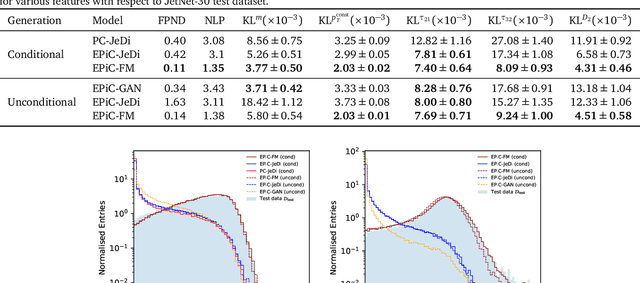
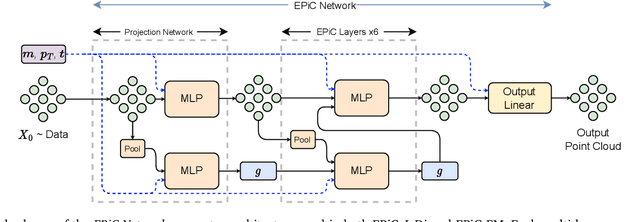

Jets at the LHC, typically consisting of a large number of highly correlated particles, are a fascinating laboratory for deep generative modeling. In this paper, we present two novel methods that generate LHC jets as point clouds efficiently and accurately. We introduce \epcjedi, which combines score-matching diffusion models with the Equivariant Point Cloud (EPiC) architecture based on the deep sets framework. This model offers a much faster alternative to previous transformer-based diffusion models without reducing the quality of the generated jets. In addition, we introduce \epcfm, the first permutation equivariant continuous normalizing flow (CNF) for particle cloud generation. This model is trained with {\it flow-matching}, a scalable and easy-to-train objective based on optimal transport that directly regresses the vector fields connecting the Gaussian noise prior to the data distribution. Our experiments demonstrate that \epcjedi and \epcfm both achieve state-of-the-art performance on the top-quark JetNet datasets whilst maintaining fast generation speed. Most notably, we find that the \epcfm model consistently outperforms all the other generative models considered here across every metric. Finally, we also introduce two new particle cloud performance metrics: the first based on the Kullback-Leibler divergence between feature distributions, the second is the negative log-posterior of a multi-model ParticleNet classifier.
Flows for Flows: Morphing one Dataset into another with Maximum Likelihood Estimation
Sep 12, 2023



Many components of data analysis in high energy physics and beyond require morphing one dataset into another. This is commonly solved via reweighting, but there are many advantages of preserving weights and shifting the data points instead. Normalizing flows are machine learning models with impressive precision on a variety of particle physics tasks. Naively, normalizing flows cannot be used for morphing because they require knowledge of the probability density of the starting dataset. In most cases in particle physics, we can generate more examples, but we do not know densities explicitly. We propose a protocol called flows for flows for training normalizing flows to morph one dataset into another even if the underlying probability density of neither dataset is known explicitly. This enables a morphing strategy trained with maximum likelihood estimation, a setup that has been shown to be highly effective in related tasks. We study variations on this protocol to explore how far the data points are moved to statistically match the two datasets. Furthermore, we show how to condition the learned flows on particular features in order to create a morphing function for every value of the conditioning feature. For illustration, we demonstrate flows for flows for toy examples as well as a collider physics example involving dijet events
SuperCalo: Calorimeter shower super-resolution
Aug 22, 2023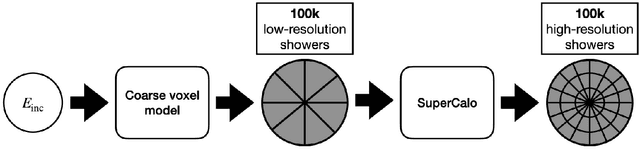



Calorimeter shower simulation is a major bottleneck in the Large Hadron Collider computational pipeline. There have been recent efforts to employ deep-generative surrogate models to overcome this challenge. However, many of best performing models have training and generation times that do not scale well to high-dimensional calorimeter showers. In this work, we introduce SuperCalo, a flow-based super-resolution model, and demonstrate that high-dimensional fine-grained calorimeter showers can be quickly upsampled from coarse-grained showers. This novel approach presents a way to reduce computational cost, memory requirements and generation time associated with fast calorimeter simulation models. Additionally, we show that the showers upsampled by SuperCalo possess a high degree of variation. This allows a large number of high-dimensional calorimeter showers to be upsampled from much fewer coarse showers with high-fidelity, which results in additional reduction in generation time.
$ν^2$-Flows: Fast and improved neutrino reconstruction in multi-neutrino final states with conditional normalizing flows
Jul 20, 2023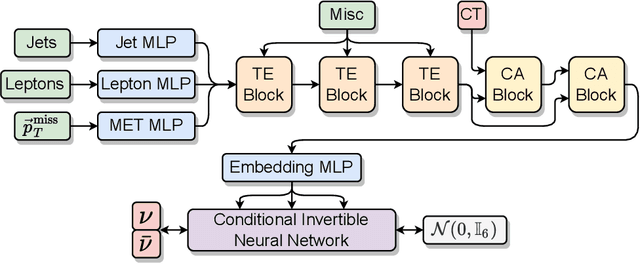

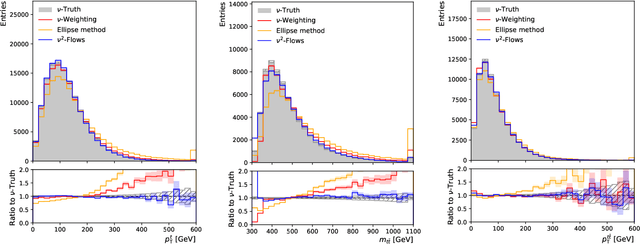
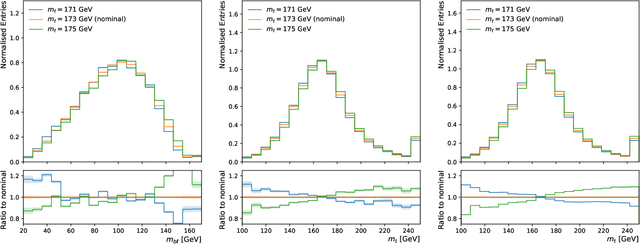
In this work we introduce $\nu^2$-Flows, an extension of the $\nu$-Flows method to final states containing multiple neutrinos. The architecture can natively scale for all combinations of object types and multiplicities in the final state for any desired neutrino multiplicities. In $t\bar{t}$ dilepton events, the momenta of both neutrinos and correlations between them are reconstructed more accurately than when using the most popular standard analytical techniques, and solutions are found for all events. Inference time is significantly faster than competing methods, and can be reduced further by evaluating in parallel on graphics processing units. We apply $\nu^2$-Flows to $t\bar{t}$ dilepton events and show that the per-bin uncertainties in unfolded distributions is much closer to the limit of performance set by perfect neutrino reconstruction than standard techniques. For the chosen double differential observables $\nu^2$-Flows results in improved statistical precision for each bin by a factor of 1.5 to 2 in comparison to the Neutrino Weighting method and up to a factor of four in comparison to the Ellipse approach.
Decorrelation using Optimal Transport
Jul 14, 2023Being able to decorrelate a feature space from protected attributes is an area of active research and study in ethics, fairness, and also natural sciences. We introduce a novel decorrelation method using Convex Neural Optimal Transport Solvers (Cnots) that is able to decorrelate a continuous feature space against protected attributes with optimal transport. We demonstrate how well it performs in the context of jet classification in high energy physics, where classifier scores are desired to be decorrelated from the mass of a jet. The decorrelation achieved in binary classification approaches the levels achieved by the state-of-the-art using conditional normalising flows. When moving to multiclass outputs the optimal transport approach performs significantly better than the state-of-the-art, suggesting substantial gains at decorrelating multidimensional feature spaces.
PC-Droid: Faster diffusion and improved quality for particle cloud generation
Jul 14, 2023Building on the success of PC-JeDi we introduce PC-Droid, a substantially improved diffusion model for the generation of jet particle clouds. By leveraging a new diffusion formulation, studying more recent integration solvers, and training on all jet types simultaneously, we are able to achieve state-of-the-art performance for all types of jets across all evaluation metrics. We study the trade-off between generation speed and quality by comparing two attention based architectures, as well as the potential of consistency distillation to reduce the number of diffusion steps. Both the faster architecture and consistency models demonstrate performance surpassing many competing models, with generation time up to two orders of magnitude faster than PC-JeDi.