 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Particle Modeling on Sets: Towards Self-Supervised High Energy Physics Foundation Models
Jan 25, 2024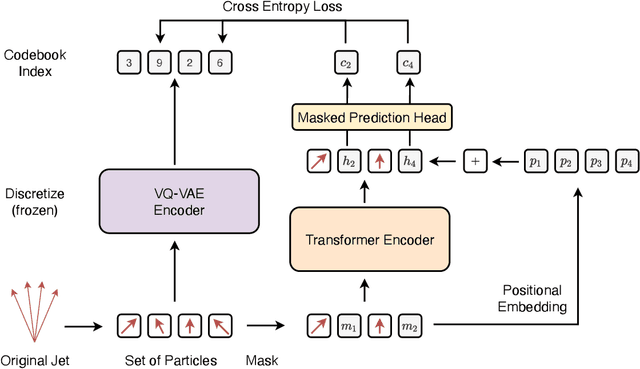
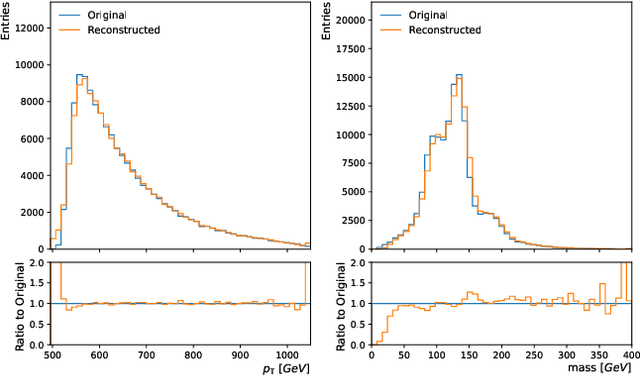
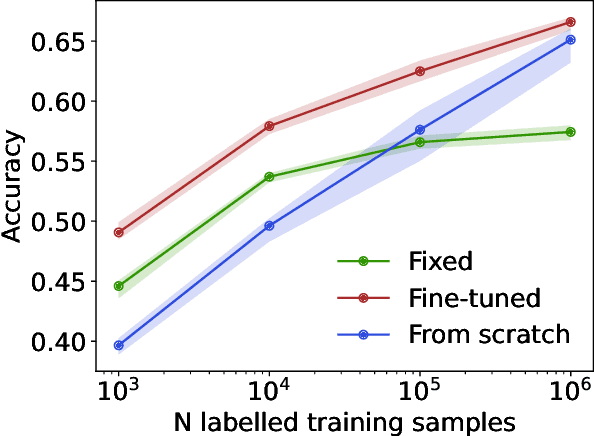
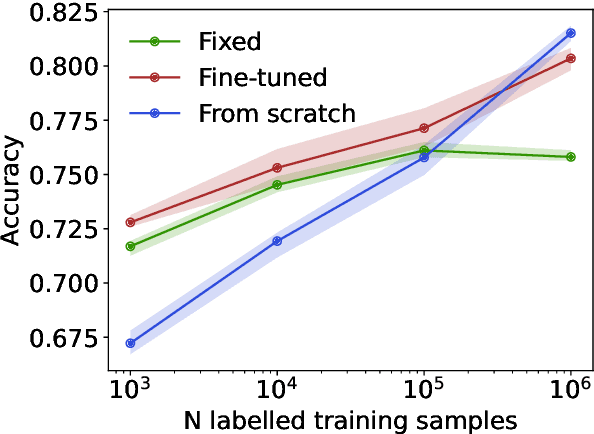
We propose masked particle modeling (MPM) as a self-supervised method for learning generic, transferable, and reusable representations on unordered sets of inputs for use in high energy physics (HEP) scientific data. This work provides a novel scheme to perform masked modeling based pre-training to learn permutation invariant functions on sets. More generally, this work provides a step towards building large foundation models for HEP that can be generically pre-trained with self-supervised learning and later fine-tuned for a variety of down-stream tasks. In MPM, particles in a set are masked and the training objective is to recover their identity, as defined by a discretized token representation of a pre-trained vector quantized variational autoencoder. We study the efficacy of the method in samples of high energy jets at collider physics experiments, including studies on the impact of discretization, permutation invariance, and ordering. We also study the fine-tuning capability of the model, showing that it can be adapted to tasks such as supervised and weakly supervised jet classification, and that the model can transfer efficiently with small fine-tuning data sets to new classes and new data domains.
Dataset Distillation Meets Provable Subset Selection
Jul 16, 2023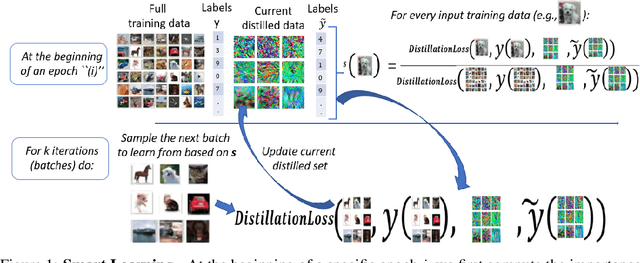
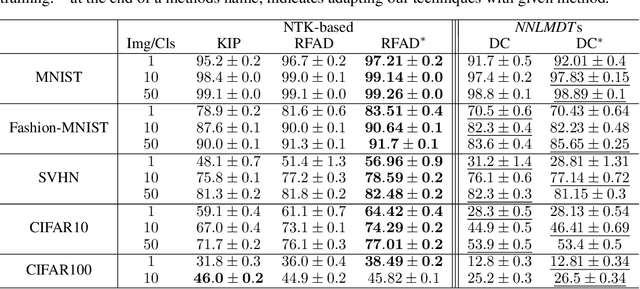
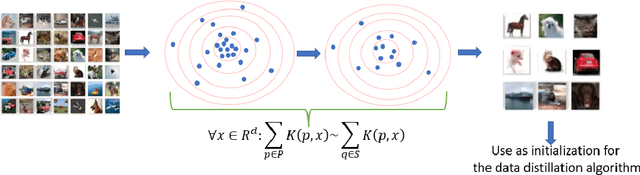
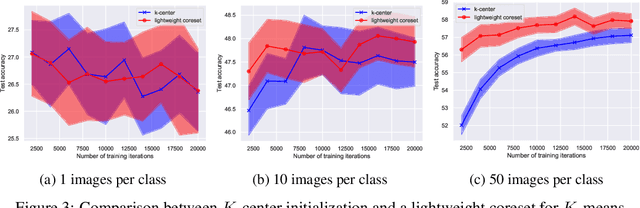
Deep learning has grown tremendously over recent years, yielding state-of-the-art results in various fields. However, training such models requires huge amounts of data, increasing the computational time and cost. To address this, dataset distillation was proposed to compress a large training dataset into a smaller synthetic one that retains its performance -- this is usually done by (1) uniformly initializing a synthetic set and (2) iteratively updating/learning this set according to a predefined loss by uniformly sampling instances from the full data. In this paper, we improve both phases of dataset distillation: (1) we present a provable, sampling-based approach for initializing the distilled set by identifying important and removing redundant points in the data, and (2) we further merge the idea of data subset selection with dataset distillation, by training the distilled set on ``important'' sampled points during the training procedure instead of randomly sampling the next batch. To do so, we define the notion of importance based on the relative contribution of instances with respect to two different loss functions, i.e., one for the initialization phase (a kernel fitting function for kernel ridge regression and $K$-means based loss function for any other distillation method), and the relative cross-entropy loss (or any other predefined loss) function for the training phase. Finally, we provide experimental results showing how our method can latch on to existing dataset distillation techniques and improve their performance.
A Unified Approach to Coreset Learning
Nov 04, 2021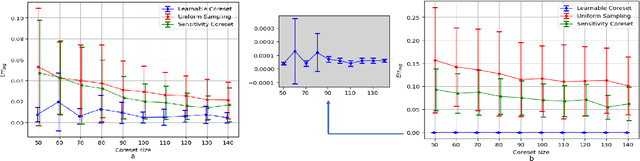
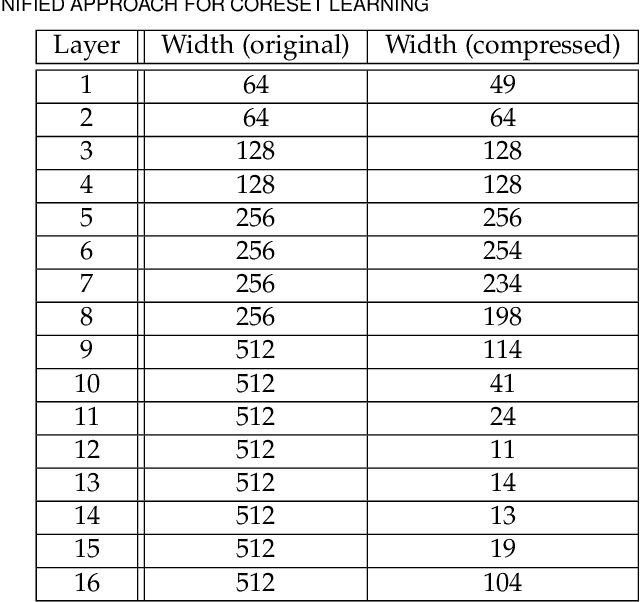
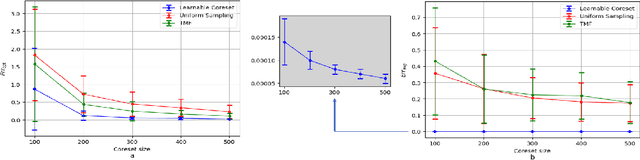
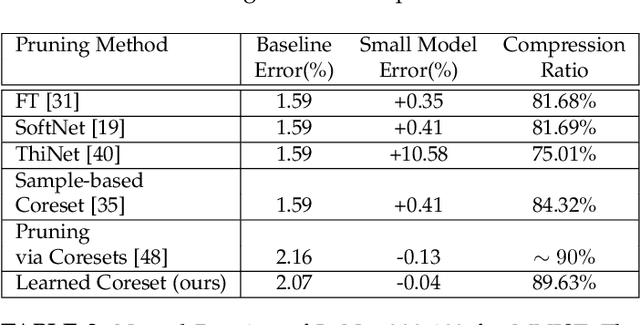
Coreset of a given dataset and loss function is usually a small weighed set that approximates this loss for every query from a given set of queries. Coresets have shown to be very useful in many applications. However, coresets construction is done in a problem dependent manner and it could take years to design and prove the correctness of a coreset for a specific family of queries. This could limit coresets use in practical applications. Moreover, small coresets provably do not exist for many problems. To address these limitations, we propose a generic, learning-based algorithm for construction of coresets. Our approach offers a new definition of coreset, which is a natural relaxation of the standard definition and aims at approximating the \emph{average} loss of the original data over the queries. This allows us to use a learning paradigm to compute a small coreset of a given set of inputs with respect to a given loss function using a training set of queries. We derive formal guarantees for the proposed approach. Experimental evaluation on deep networks and classic machine learning problems show that our learned coresets yield comparable or even better results than the existing algorithms with worst-case theoretical guarantees (that may be too pessimistic in practice). Furthermore, our approach applied to deep network pruning provides the first coreset for a full deep network, i.e., compresses all the network at once, and not layer by layer or similar divide-and-conquer methods.
Fuzzy Commitments Offer Insufficient Protection to Biometric Templates Produced by Deep Learning
Dec 24, 2020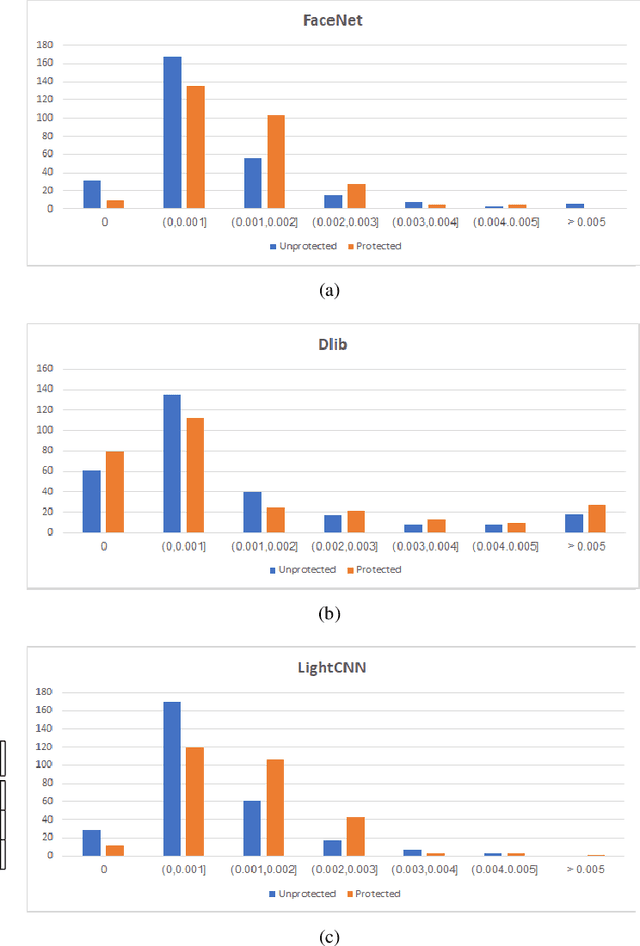

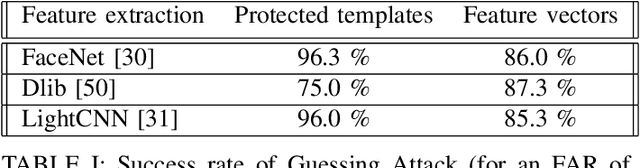
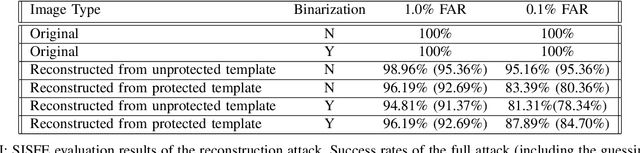
In this work, we study the protection that fuzzy commitments offer when they are applied to facial images, processed by the state of the art deep learning facial recognition systems. We show that while these systems are capable of producing great accuracy, they produce templates of too little entropy. As a result, we present a reconstruction attack that takes a protected template, and reconstructs a facial image. The reconstructed facial images greatly resemble the original ones. In the simplest attack scenario, more than 78% of these reconstructed templates succeed in unlocking an account (when the system is configured to 0.1% FAR). Even in the "hardest" settings (in which we take a reconstructed image from one system and use it in a different system, with different feature extraction process) the reconstructed image offers 50 to 120 times higher success rates than the system's FAR.
Data-Independent Structured Pruning of Neural Networks via Coresets
Aug 19, 2020
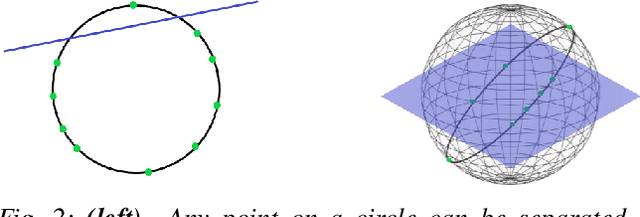
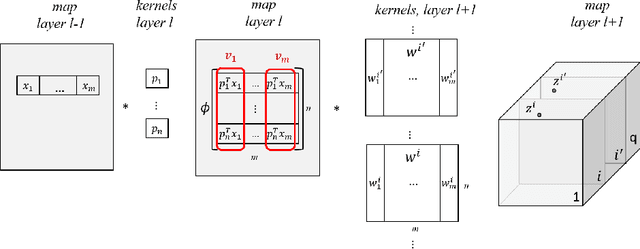
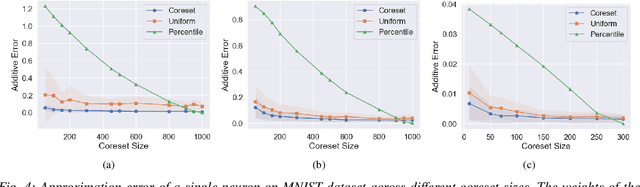
Model compression is crucial for deployment of neural networks on devices with limited computational and memory resources. Many different methods show comparable accuracy of the compressed model and similar compression rates. However, the majority of the compression methods are based on heuristics and offer no worst-case guarantees on the trade-off between the compression rate and the approximation error for an arbitrarily new sample. We propose the first efficient structured pruning algorithm with a provable trade-off between its compression rate and the approximation error for any future test sample. Our method is based on the coreset framework and it approximates the output of a layer of neurons/filters by a coreset of neurons/filters in the previous layer and discards the rest. We apply this framework in a layer-by-layer fashion from the bottom to the top. Unlike previous works, our coreset is data independent, meaning that it provably guarantees the accuracy of the function for any input $x\in \mathbb{R}^d$, including an adversarial one.
LSHR-Net: a hardware-friendly solution for high-resolution computational imaging using a mixed-weights neural network
Apr 27, 2020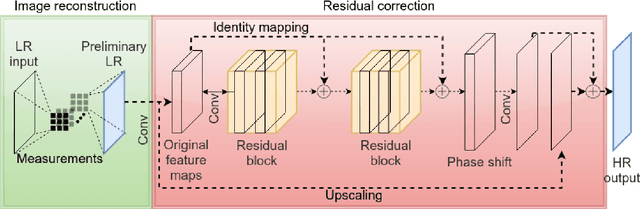

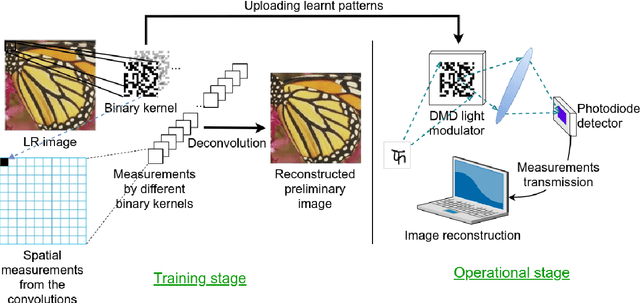
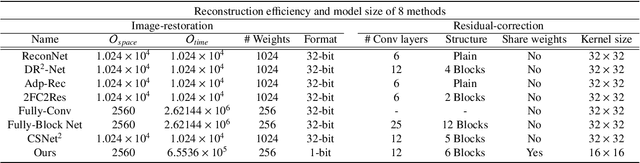
Recent work showed neural-network-based approaches to reconstructing images from compressively sensed measurements offer significant improvements in accuracy and signal compression. Such methods can dramatically boost the capability of computational imaging hardware. However, to date, there have been two major drawbacks: (1) the high-precision real-valued sensing patterns proposed in the majority of existing works can prove problematic when used with computational imaging hardware such as a digital micromirror sampling device and (2) the network structures for image reconstruction involve intensive computation, which is also not suitable for hardware deployment. To address these problems, we propose a novel hardware-friendly solution based on mixed-weights neural networks for computational imaging. In particular, learned binary-weight sensing patterns are tailored to the sampling device. Moreover, we proposed a recursive network structure for low-resolution image sampling and high-resolution reconstruction scheme. It reduces both the required number of measurements and reconstruction computation by operating convolution on small intermediate feature maps. The recursive structure further reduced the model size, making the network more computationally efficient when deployed with the hardware. Our method has been validated on benchmark datasets and achieved the state of the art reconstruction accuracy. We tested our proposed network in conjunction with a proof-of-concept hardware setup.
Learning to Support: Exploiting Structure Information in Support Sets for One-Shot Learning
Aug 22, 2018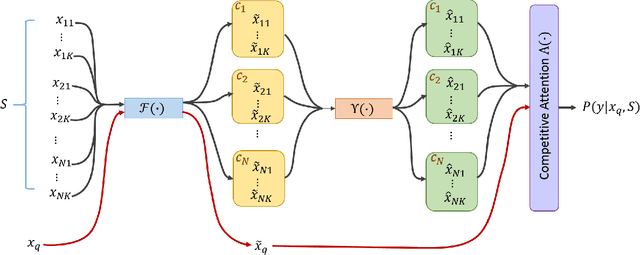
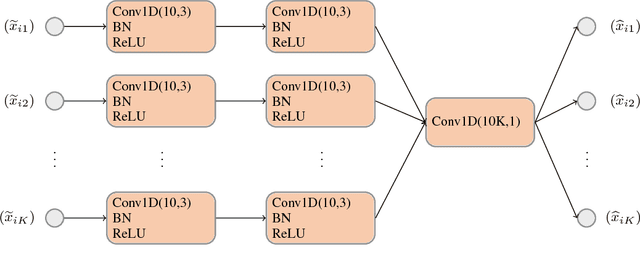
Deep Learning shows very good performance when trained on large labeled data sets. The problem of training a deep net on a few or one sample per class requires a different learning approach which can generalize to unseen classes using only a few representatives of these classes. This problem has previously been approached by meta-learning. Here we propose a novel meta-learner which shows state-of-the-art performance on common benchmarks for one/few shot classification. Our model features three novel components: First is a feed-forward embedding that takes random class support samples (after a customary CNN embedding) and transfers them to a better class representation in terms of a classification problem. Second is a novel attention mechanism, inspired by competitive learning, which causes class representatives to compete with each other to become a temporary class prototype with respect to the query point. This mechanism allows switching between representatives depending on the position of the query point. Once a prototype is chosen for each class, the predicated label is computed using a simple attention mechanism over prototypes of all considered classes. The third feature is the ability of our meta-learner to incorporate deeper CNN embedding, enabling larger capacity. Finally, to ease the training procedure and reduce overfitting, we averages the top $t$ models (evaluated on the validation) over the optimization trajectory. We show that this approach can be viewed as an approximation to an ensemble, which saves the factor of $t$ in training and test times and the factor of of $t$ in the storage of the final model.
Dynamic Spectrum Matching with One-shot Learning
Jun 23, 2018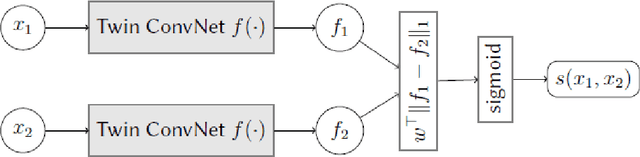

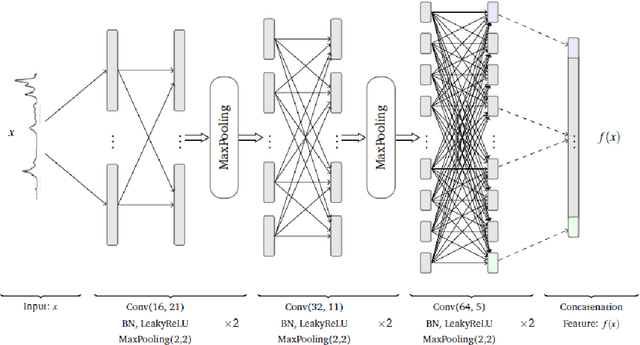
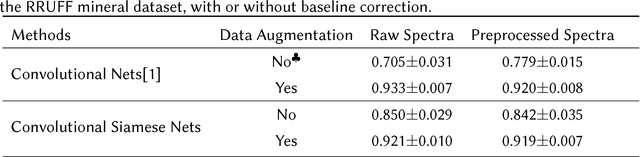
Convolutional neural networks (CNN) have been shown to provide a good solution for classification problems that utilize data obtained from vibrational spectroscopy. Moreover, CNNs are capable of identification from noisy spectra without the need for additional preprocessing. However, their application in practical spectroscopy is limited due to two shortcomings. The effectiveness of the classification using CNNs drops rapidly when only a small number of spectra per substance are available for training (which is a typical situation in real applications). Additionally, to accommodate new, previously unseen substance classes, the network must be retrained which is computationally intensive. Here we address these issues by reformulating a multi-class classification problem with a large number of classes, but a small number of samples per class, to a binary classification problem with sufficient data available for representation learning. Namely, we define the learning task as identifying pairs of inputs as belonging to the same or different classes. We achieve this using a Siamese convolutional neural network. A novel sampling strategy is proposed to address the imbalance problem in training the Siamese Network. The trained network can effectively classify samples of unseen substance classes using just a single reference sample (termed as one-shot learning in the machine learning community). Our results demonstrate better accuracy than other practical systems to date, while allowing effortless updates of the system's database with novel substance classes.
Deep Convolutional Neural Networks for Raman Spectrum Recognition: A Unified Solution
Aug 18, 2017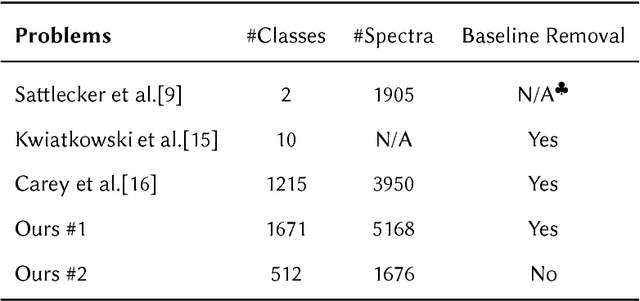
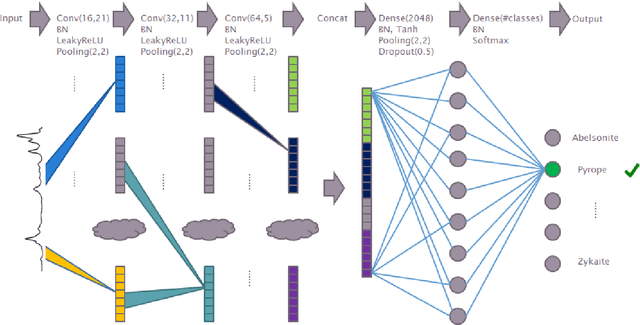

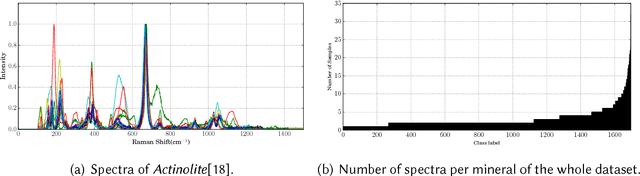
Machine learning methods have found many applications in Raman spectroscopy, especially for the identification of chemical species. However, almost all of these methods require non-trivial preprocessing such as baseline correction and/or PCA as an essential step. Here we describe our unified solution for the identification of chemical species in which a convolutional neural network is trained to automatically identify substances according to their Raman spectrum without the need of ad-hoc preprocessing steps. We evaluated our approach using the RRUFF spectral database, comprising mineral sample data. Superior classification performance is demonstrated compared with other frequently used machine learning algorithms including the popular support vector machine.
Latent Hinge-Minimax Risk Minimization for Inference from a Small Number of Training Samples
Feb 04, 2017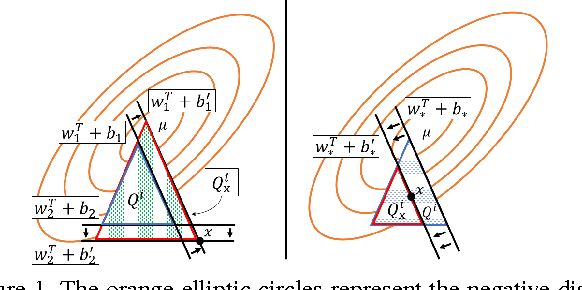

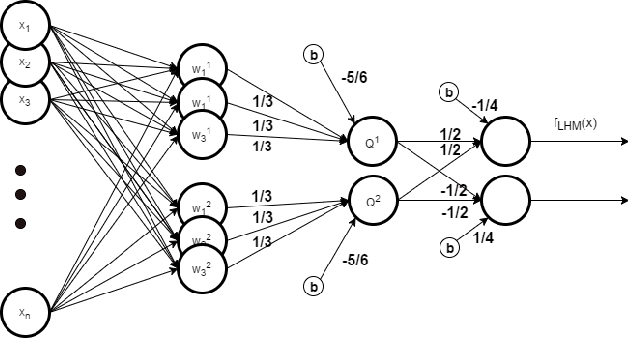

Deep Learning (DL) methods show very good performance when trained on large, balanced data sets. However, many practical problems involve imbalanced data sets, or/and classes with a small number of training samples. The performance of DL methods as well as more traditional classifiers drops significantly in such settings. Most of the existing solutions for imbalanced problems focus on customizing the data for training. A more principled solution is to use mixed Hinge-Minimax risk [19] specifically designed to solve binary problems with imbalanced training sets. Here we propose a Latent Hinge Minimax (LHM) risk and a training algorithm that generalizes this paradigm to an ensemble of hyperplanes that can form arbitrary complex, piecewise linear boundaries. To extract good features, we combine LHM model with CNN via transfer learning. To solve multi-class problem we map pre-trained category-specific LHM classifiers to a multi-class neural network and adjust the weights with very fast tuning. LHM classifier enables the use of unlabeled data in its training and the mapping allows for multi-class inference, resulting in a classifier that performs better than alternatives when trained on a small number of training samples.