 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSHR-Net: a hardware-friendly solution for high-resolution computational imaging using a mixed-weights neural network
Apr 27, 2020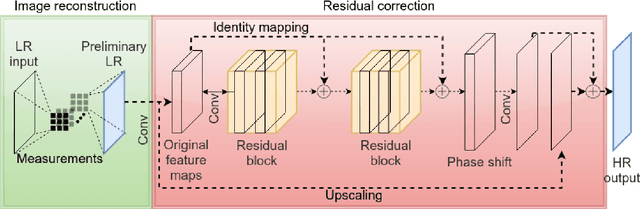

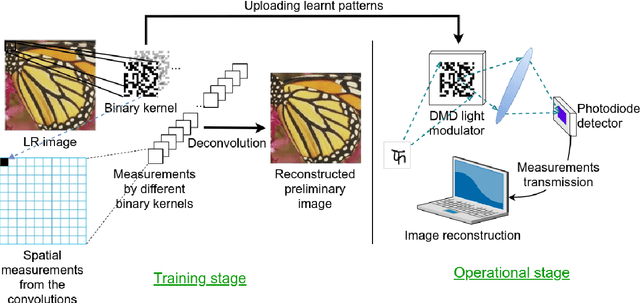
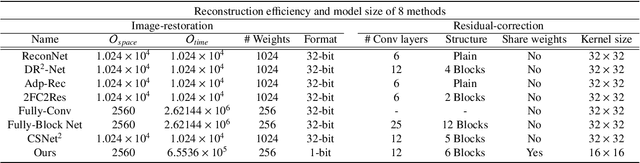
Recent work showed neural-network-based approaches to reconstructing images from compressively sensed measurements offer significant improvements in accuracy and signal compression. Such methods can dramatically boost the capability of computational imaging hardware. However, to date, there have been two major drawbacks: (1) the high-precision real-valued sensing patterns proposed in the majority of existing works can prove problematic when used with computational imaging hardware such as a digital micromirror sampling device and (2) the network structures for image reconstruction involve intensive computation, which is also not suitable for hardware deployment. To address these problems, we propose a novel hardware-friendly solution based on mixed-weights neural networks for computational imaging. In particular, learned binary-weight sensing patterns are tailored to the sampling device. Moreover, we proposed a recursive network structure for low-resolution image sampling and high-resolution reconstruction scheme. It reduces both the required number of measurements and reconstruction computation by operating convolution on small intermediate feature maps. The recursive structure further reduced the model size, making the network more computationally efficient when deployed with the hardware. Our method has been validated on benchmark datasets and achieved the state of the art reconstruction accuracy. We tested our proposed network in conjunction with a proof-of-concept hardware setup.
Learning to Support: Exploiting Structure Information in Support Sets for One-Shot Learning
Aug 22, 2018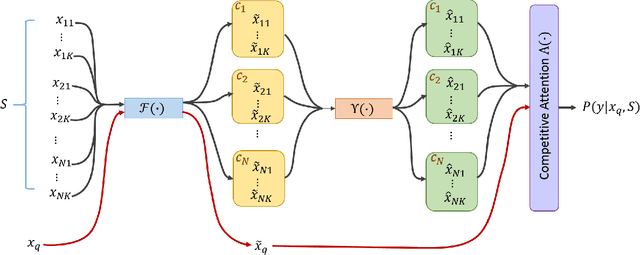
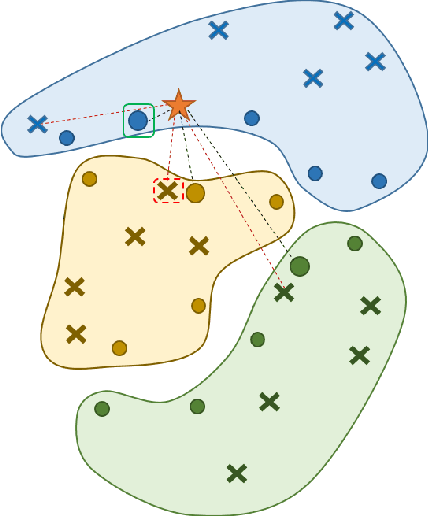
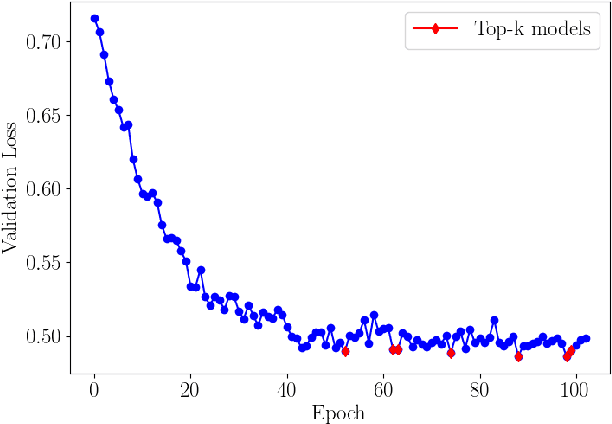
Deep Learning shows very good performance when trained on large labeled data sets. The problem of training a deep net on a few or one sample per class requires a different learning approach which can generalize to unseen classes using only a few representatives of these classes. This problem has previously been approached by meta-learning. Here we propose a novel meta-learner which shows state-of-the-art performance on common benchmarks for one/few shot classification. Our model features three novel components: First is a feed-forward embedding that takes random class support samples (after a customary CNN embedding) and transfers them to a better class representation in terms of a classification problem. Second is a novel attention mechanism, inspired by competitive learning, which causes class representatives to compete with each other to become a temporary class prototype with respect to the query point. This mechanism allows switching between representatives depending on the position of the query point. Once a prototype is chosen for each class, the predicated label is computed using a simple attention mechanism over prototypes of all considered classes. The third feature is the ability of our meta-learner to incorporate deeper CNN embedding, enabling larger capacity. Finally, to ease the training procedure and reduce overfitting, we averages the top $t$ models (evaluated on the validation) over the optimization trajectory. We show that this approach can be viewed as an approximation to an ensemble, which saves the factor of $t$ in training and test times and the factor of of $t$ in the storage of the final model.
Dynamic Spectrum Matching with One-shot Learning
Jun 23, 2018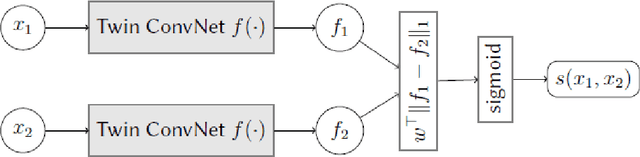

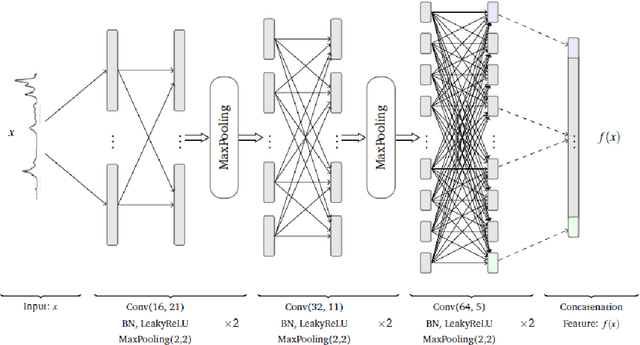
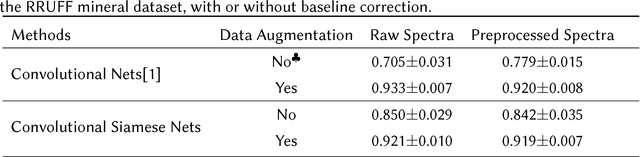
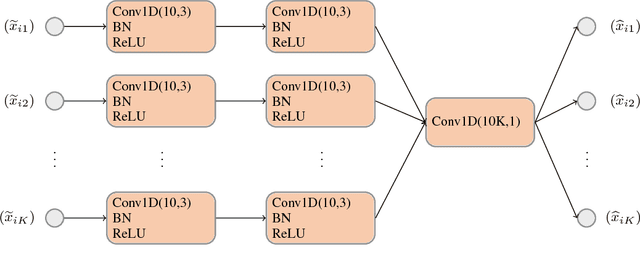
Convolutional neural networks (CNN) have been shown to provide a good solution for classification problems that utilize data obtained from vibrational spectroscopy. Moreover, CNNs are capable of identification from noisy spectra without the need for additional preprocessing. However, their application in practical spectroscopy is limited due to two shortcomings. The effectiveness of the classification using CNNs drops rapidly when only a small number of spectra per substance are available for training (which is a typical situation in real applications). Additionally, to accommodate new, previously unseen substance classes, the network must be retrained which is computationally intensive. Here we address these issues by reformulating a multi-class classification problem with a large number of classes, but a small number of samples per class, to a binary classification problem with sufficient data available for representation learning. Namely, we define the learning task as identifying pairs of inputs as belonging to the same or different classes. We achieve this using a Siamese convolutional neural network. A novel sampling strategy is proposed to address the imbalance problem in training the Siamese Network. The trained network can effectively classify samples of unseen substance classes using just a single reference sample (termed as one-shot learning in the machine learning community). Our results demonstrate better accuracy than other practical systems to date, while allowing effortless updates of the system's database with novel substance classes.
Deep Convolutional Neural Networks for Raman Spectrum Recognition: A Unified Solution
Aug 18, 2017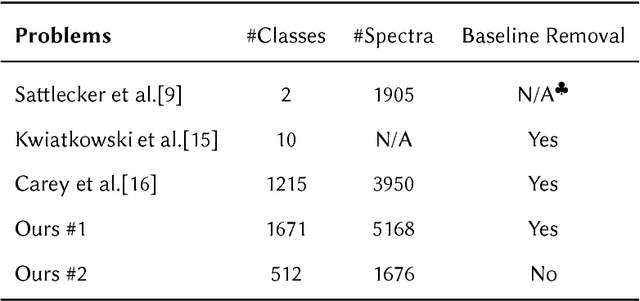
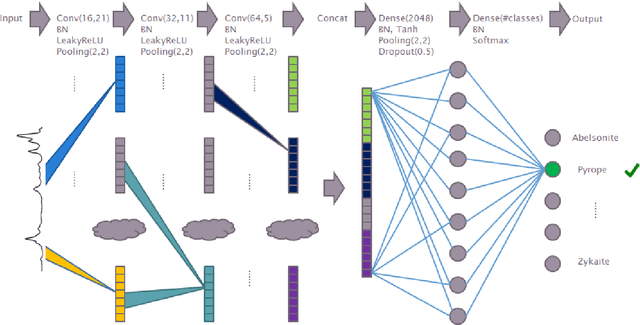

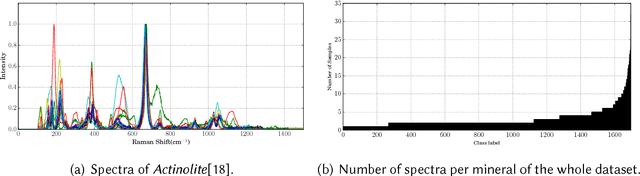
Machine learning methods have found many applications in Raman spectroscopy, especially for the identification of chemical species. However, almost all of these methods require non-trivial preprocessing such as baseline correction and/or PCA as an essential step. Here we describe our unified solution for the identification of chemical species in which a convolutional neural network is trained to automatically identify substances according to their Raman spectrum without the need of ad-hoc preprocessing steps. We evaluated our approach using the RRUFF spectral database, comprising mineral sample data. Superior classification performance is demonstrated compared with other frequently used machine learning algorithms including the popular support vector machine.