 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSLAU-Net: A Hybird CNN-Transformer Network for Medical Image Segmentation
May 24, 2025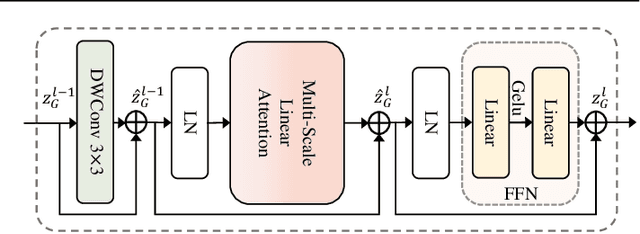
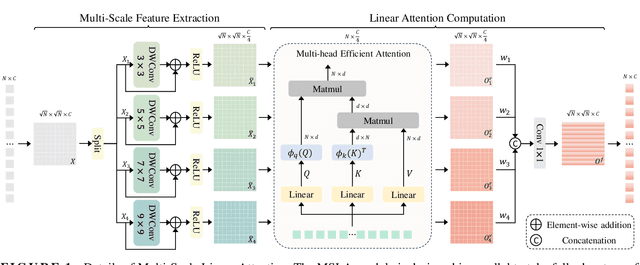
Both CNN-based and Transformer-based methods have achieved remarkable success in medical image segmentation tasks. However, CNN-based methods struggle to effectively capture global contextual information due to the inherent limitations of convolution operations. Meanwhile, Transformer-based methods suffer from insufficient local feature modeling and face challenges related to the high computational complexity caused by the self-attention mechanism. To address these limitations, we propose a novel hybrid CNN-Transformer architecture, named MSLAU-Net, which integrates the strengths of both paradigms. The proposed MSLAU-Net incorporates two key ideas. First, it introduces Multi-Scale Linear Attention, designed to efficiently extract multi-scale features from medical images while modeling long-range dependencies with low computational complexity. Second, it adopts a top-down feature aggregation mechanism, which performs multi-level feature aggregation and restores spatial resolution using a lightweight structure. Extensive experiments conducted on benchmark datasets covering three imaging modalities demonstrate that the proposed MSLAU-Net outperforms other state-of-the-art methods on nearly all evaluation metrics, validating the superiority, effectiveness, and robustness of our approach. Our code is available at https://github.com/Monsoon49/MSLAU-Net.
FullTransNet: Full Transformer with Local-Global Attention for Video Summarization
Jan 01, 2025Video summarization mainly aims to produce a compact, short, informative, and representative synopsis of raw videos, which is of great importance for browsing, analyzing, and understanding video content. Dominant video summarization approaches are generally based on recurrent or convolutional neural networks, even recent encoder-only transformers. We propose using full transformer as an alternative architecture to perform video summarization. The full transformer with an encoder-decoder structure, specifically designed for handling sequence transduction problems, is naturally suitable for video summarization tasks. This work considers supervised video summarization and casts it as a sequence-to-sequence learning problem. Our key idea is to directly apply the full transformer to the video summarization task, which is intuitively sound and effective. Also, considering the efficiency problem, we replace full attention with the combination of local and global sparse attention, which enables modeling long-range dependencies while reducing computational costs. Based on this, we propose a transformer-like architecture, named FullTransNet, which has a full encoder-decoder structure with local-global sparse attention for video summarization. Specifically, both the encoder and decoder in FullTransNet are stacked the same way as ones in the vanilla transformer, and the local-global sparse attention is used only at the encoder side. Extensive experiments on two public multimedia benchmark datasets SumMe and TVSum demonstrate that our proposed model can outperform other video summarization approaches, achieving F-Measures of 54.4% on SumMe and 63.9% on TVSum with relatively lower compute and memory requirements, verifying its effectiveness and efficiency. The code and models are publicly available on GitHub.
Pubic Symphysis-Fetal Head Segmentation Network Using BiFormer Attention Mechanism and Multipath Dilated Convolution
Oct 15, 2024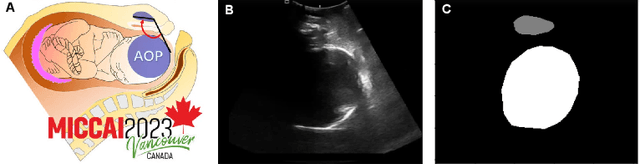

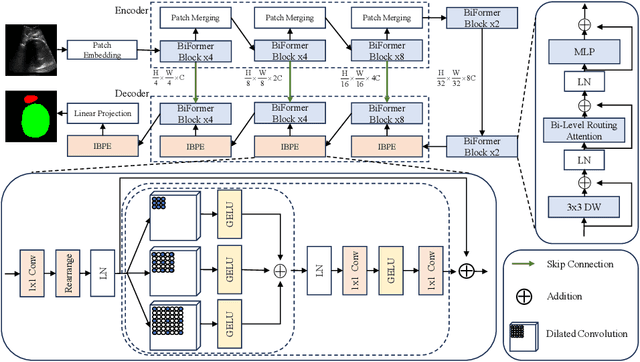

Pubic symphysis-fetal head segmentation in transperineal ultrasound images plays a critical role for the assessment of fetal head descent and progression. Existing transformer segmentation methods based on sparse attention mechanism use handcrafted static patterns, which leads to great differences in terms of segmentation performance on specific datasets. To address this issue, we introduce a dynamic, query-aware sparse attention mechanism for ultrasound image segmentation. Specifically, we propose a novel method, named BRAU-Net to solve the pubic symphysis-fetal head segmentation task in this paper. The method adopts a U-Net-like encoder-decoder architecture with bi-level routing attention and skip connections, which effectively learns local-global semantic information. In addition, we propose an inverted bottleneck patch expanding (IBPE) module to reduce information loss while performing up-sampling operations. The proposed BRAU-Net is evaluated on FH-PS-AoP and HC18 datasets. The results demonstrate that our method could achieve excellent segmentation results. The code is available on GitHub.
BRAU-Net++: U-Shaped Hybrid CNN-Transformer Network for Medical Image Segmentation
Jan 01, 2024



Accurate medical image segmentation is essential for clinical quantification, disease diagnosis, treatment planning and many other applications. Both convolution-based and transformer-based u-shaped architectures have made significant success in various medical image segmentation tasks. The former can efficiently learn local information of images while requiring much more image-specific inductive biases inherent to convolution operation. The latter can effectively capture long-range dependency at different feature scales using self-attention, whereas it typically encounters the challenges of quadratic compute and memory requirements with sequence length increasing. To address this problem, through integrating the merits of these two paradigms in a well-designed u-shaped architecture, we propose a hybrid yet effective CNN-Transformer network, named BRAU-Net++, for an accurate medical image segmentation task. Specifically, BRAU-Net++ uses bi-level routing attention as the core building block to design our u-shaped encoder-decoder structure, in which both encoder and decoder are hierarchically constructed, so as to learn global semantic information while reducing computational complexity. Furthermore, this network restructures skip connection by incorporating channel-spatial attention which adopts convolution operations, aiming to minimize local spatial information loss and amplify global dimension-interaction of multi-scale features. Extensive experiments on three public benchmark datasets demonstrate that our proposed approach surpasses other state-of-the-art methods including its baseline: BRAU-Net under almost all evaluation metrics. We achieve the average Dice-Similarity Coefficient (DSC) of 82.47, 90.10, and 92.94 on Synapse multi-organ segmentation, ISIC-2018 Challenge, and CVC-ClinicDB, as well as the mIoU of 84.01 and 88.17 on ISIC-2018 Challenge and CVC-ClinicDB, respectively.
A machine-learning-based tool for last closed magnetic flux surface reconstruction on tokamak
Jul 12, 2022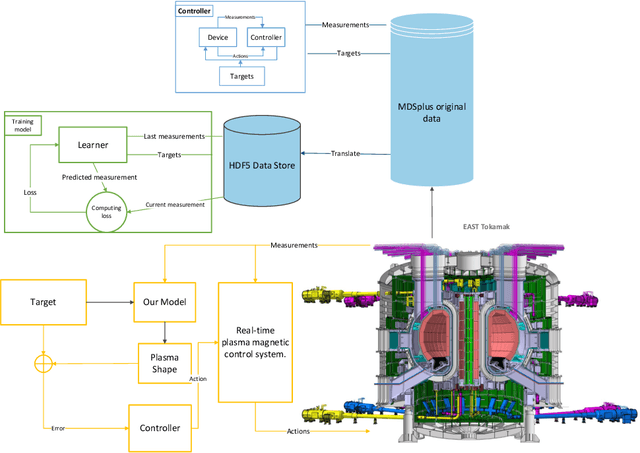

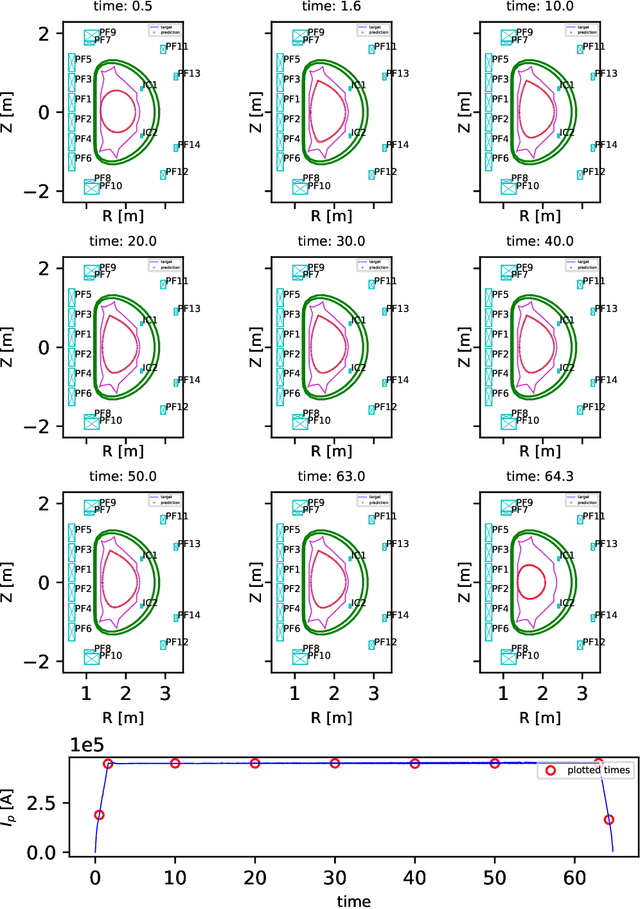
Nuclear fusion power created by tokamak devices holds one of the most promising ways as a sustainable source of clean energy. One main challenge research field of tokamak is to predict the last closed magnetic flux surface (LCFS) determined by the interaction of the actuator coils and the internal tokamak plasma. This work requires high-dimensional, high-frequency, high-fidelity, real-time tools, further complicated by the wide range of actuator coils input interact with internal tokamak plasma states. In this work, we present a new machine learning model for reconstructing the LCFS from the Experimental Advanced Superconducting Tokamak (EAST) that learns automatically from the experimental data of EAST. This architecture can check the control strategy design and integrate it with the tokamak control system for real-time magnetic prediction. In the real-time modeling test, our approach achieves over 99% average similarity in LCFS reconstruction of the entire discharge process. In the offline magnetic reconstruction, our approach reaches over 93% average similarity.
Experiment data-driven modeling of tokamak discharge in EAST
Jul 21, 2020
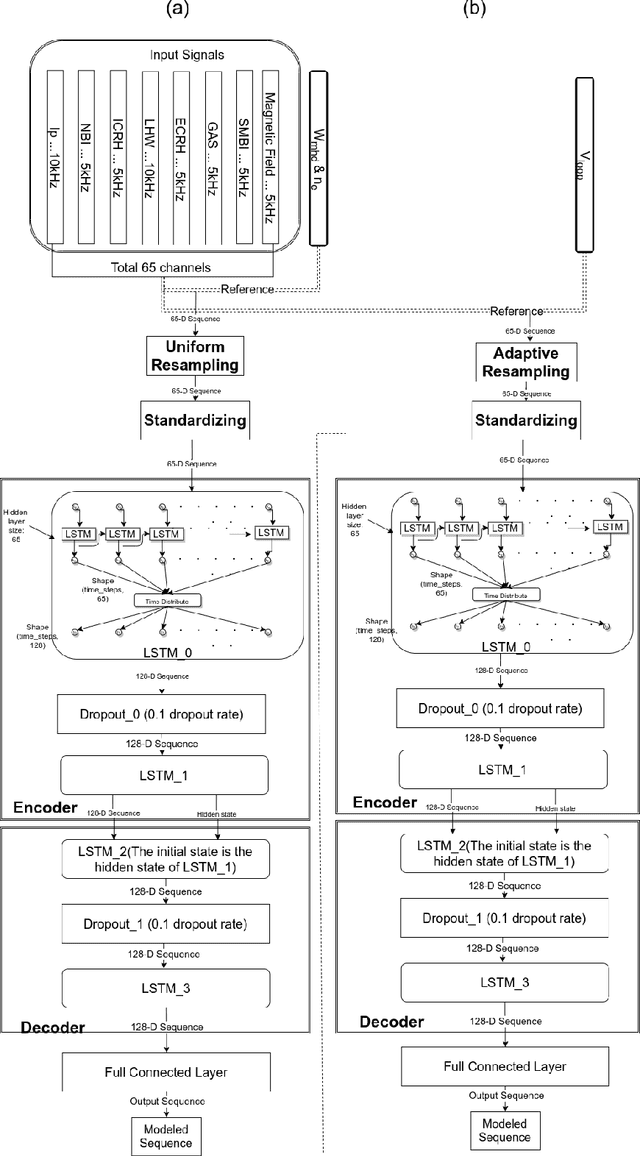
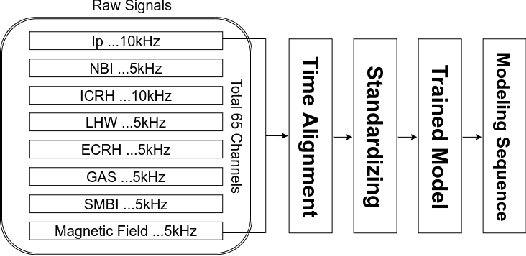

A model for tokamak discharge through deep learning has been done on EAST tokamak. This model can use the controlled input signals (i.e. NBI, ICRH, etc) to model normal discharge without the need for doing real experiments. By using the data-driven methodology, we exploit the temporal sequence of controlled input signals for a large set of EAST discharges to develop a deep learning model for modeling discharge diagnose signals, such as electron density n_{e}, store energy W_{mhd} and loop voltage V_{loop}. Comparing the similar methodology, we pioneered a state-of-the-art Machine Learning techniques to develop the data-driven model for discharge modeling. Up to 95% similarity was achieved for W_{mhd}. The first try showed very promising results for modeling of tokamak discharge by using data-driven methodology. This is a very good tool for the ultimate goal of machine learning applied in fusion experiments for plasma discharge modeling and discharge planning in the future.
LSHR-Net: a hardware-friendly solution for high-resolution computational imaging using a mixed-weights neural network
Apr 27, 2020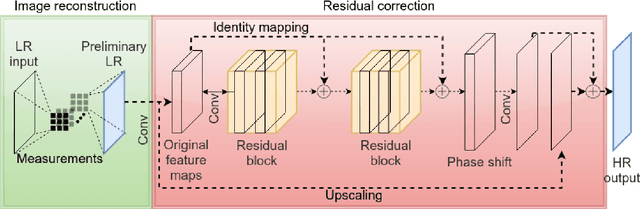

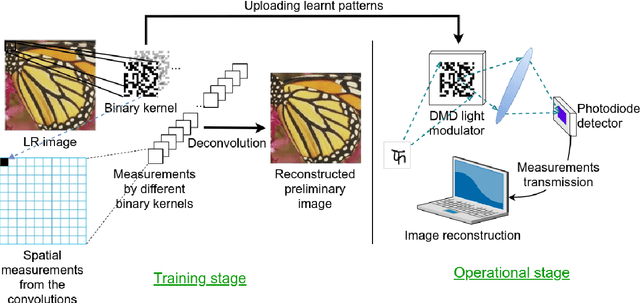
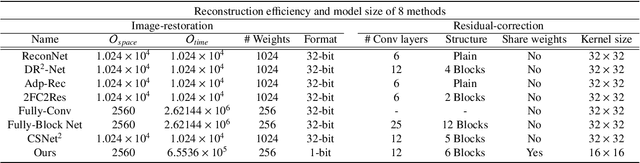
Recent work showed neural-network-based approaches to reconstructing images from compressively sensed measurements offer significant improvements in accuracy and signal compression. Such methods can dramatically boost the capability of computational imaging hardware. However, to date, there have been two major drawbacks: (1) the high-precision real-valued sensing patterns proposed in the majority of existing works can prove problematic when used with computational imaging hardware such as a digital micromirror sampling device and (2) the network structures for image reconstruction involve intensive computation, which is also not suitable for hardware deployment. To address these problems, we propose a novel hardware-friendly solution based on mixed-weights neural networks for computational imaging. In particular, learned binary-weight sensing patterns are tailored to the sampling device. Moreover, we proposed a recursive network structure for low-resolution image sampling and high-resolution reconstruction scheme. It reduces both the required number of measurements and reconstruction computation by operating convolution on small intermediate feature maps. The recursive structure further reduced the model size, making the network more computationally efficient when deployed with the hardware. Our method has been validated on benchmark datasets and achieved the state of the art reconstruction accuracy. We tested our proposed network in conjunction with a proof-of-concept hardware setup.