 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback
Jul 28, 2025



Multimodal Large Language Models (MLLMs) have exhibited impressive performance across various visual tasks. Subsequent investigations into enhancing their visual reasoning abilities have significantly expanded their performance envelope. However, a critical bottleneck in the advancement of MLLMs toward deep visual reasoning is their heavy reliance on curated image-text supervision. To solve this problem, we introduce a novel framework termed ``Reasoning-Rendering-Visual-Feedback'' (RRVF), which enables MLLMs to learn complex visual reasoning from only raw images. This framework builds on the ``Asymmetry of Verification'' principle to train MLLMs, i.e., verifying the rendered output against a source image is easier than generating it. We demonstrate that this relative ease provides an ideal reward signal for optimization via Reinforcement Learning (RL) training, reducing the reliance on the image-text supervision. Guided by the above principle, RRVF implements a closed-loop iterative process encompassing reasoning, rendering, and visual feedback components, enabling the model to perform self-correction through multi-turn interactions and tool invocation, while this pipeline can be optimized by the GRPO algorithm in an end-to-end manner. Extensive experiments on image-to-code generation for data charts and web interfaces show that RRVF substantially outperforms existing open-source MLLMs and surpasses supervised fine-tuning baselines. Our findings demonstrate that systems driven by purely visual feedback present a viable path toward more robust and generalizable reasoning models without requiring explicit supervision. Code will be available at https://github.com/L-O-I/RRVF.
One Head Eight Arms: Block Matrix based Low Rank Adaptation for CLIP-based Few-Shot Learning
Jan 28, 2025



Recent advancements in fine-tuning Vision-Language Foundation Models (VLMs) have garnered significant attention for their effectiveness in downstream few-shot learning tasks.While these recent approaches exhibits some performance improvements, they often suffer from excessive training parameters and high computational costs. To address these challenges, we propose a novel Block matrix-based low-rank adaptation framework, called Block-LoRA, for fine-tuning VLMs on downstream few-shot tasks. Inspired by recent work on Low-Rank Adaptation (LoRA), Block-LoRA partitions the original low-rank decomposition matrix of LoRA into a series of sub-matrices while sharing all down-projection sub-matrices. This structure not only reduces the number of training parameters, but also transforms certain complex matrix multiplication operations into simpler matrix addition, significantly lowering the computational cost of fine-tuning. Notably, Block-LoRA enables fine-tuning CLIP on the ImageNet few-shot benchmark using a single 24GB GPU. We also show that Block-LoRA has the more tighter bound of generalization error than vanilla LoRA. Without bells and whistles, extensive experiments demonstrate that Block-LoRA achieves competitive performance compared to state-of-the-art CLIP-based few-shot methods, while maintaining a low training parameters count and reduced computational overhead.
Wireless Communication with Flexible Reflector: Joint Placement and Rotation Optimization for Coverage Enhancement
Dec 25, 2024



Passive metal reflectors for communication enhancement have appealing advantages such as ultra low cost, zero energy expenditure, maintenance-free operation, long life span, and full compatibility with legacy wireless systems. To unleash the full potential of passive reflectors for wireless communications, this paper proposes a new passive reflector architecture, termed flexible reflector (FR), for enabling the flexible adjustment of beamforming direction via the FR placement and rotation optimization. We consider the multi-FR aided area coverage enhancement and aim to maximize the minimum expected receive power over all locations within the target coverage area, by jointly optimizing the placement positions and rotation angles of multiple FRs. To gain useful insights, the special case of movable reflector (MR) with fixed rotation is first studied to maximize the expected receive power at a target location, where the optimal single-MR placement positions for electrically large and small reflectors are derived in closed-form, respectively. It is shown that the reflector should be placed at the specular reflection point for electrically large reflector. While for area coverage enhancement, the optimal placement is obtained for the single-MR case and a sequential placement algorithm is proposed for the multi-MR case. Moreover, for the general case of FR, joint placement and rotation design is considered for the single-/multi-FR aided coverage enhancement, respectively. Numerical results are presented which demonstrate significant performance gains of FRs over various benchmark schemes under different practical setups in terms of receive power enhancement.
Is Cognition consistent with Perception? Assessing and Mitigating Multimodal Knowledge Conflicts in Document Understanding
Nov 12, 2024



Multimodal large language models (MLLMs) have shown impressive capabilities in document understanding, a rapidly growing research area with significant industrial demand in recent years. As a multimodal task, document understanding requires models to possess both perceptual and cognitive abilities. However, current MLLMs often face conflicts between perception and cognition. Taking a document VQA task (cognition) as an example, an MLLM might generate answers that do not match the corresponding visual content identified by its OCR (perception). This conflict suggests that the MLLM might struggle to establish an intrinsic connection between the information it "sees" and what it "understands." Such conflicts challenge the intuitive notion that cognition is consistent with perception, hindering the performance and explainability of MLLMs. In this paper, we define the conflicts between cognition and perception as Cognition and Perception (C&P) knowledge conflicts, a form of multimodal knowledge conflicts, and systematically assess them with a focus on document understanding. Our analysis reveals that even GPT-4o, a leading MLLM, achieves only 68.6% C&P consistency. To mitigate the C&P knowledge conflicts, we propose a novel method called Multimodal Knowledge Consistency Fine-tuning. This method first ensures task-specific consistency and then connects the cognitive and perceptual knowledge. Our method significantly reduces C&P knowledge conflicts across all tested MLLMs and enhances their performance in both cognitive and perceptual tasks in most scenarios.
SAM-SP: Self-Prompting Makes SAM Great Again
Aug 22, 2024



The recently introduced Segment Anything Model (SAM), a Visual Foundation Model (VFM), has demonstrated impressive capabilities in zero-shot segmentation tasks across diverse natural image datasets. Despite its success, SAM encounters noticeably performance degradation when applied to specific domains, such as medical images. Current efforts to address this issue have involved fine-tuning strategies, intended to bolster the generalizability of the vanilla SAM. However, these approaches still predominantly necessitate the utilization of domain specific expert-level prompts during the evaluation phase, which severely constrains the model's practicality. To overcome this limitation, we introduce a novel self-prompting based fine-tuning approach, called SAM-SP, tailored for extending the vanilla SAM model. Specifically, SAM-SP leverages the output from the previous iteration of the model itself as prompts to guide subsequent iteration of the model. This self-prompting module endeavors to learn how to generate useful prompts autonomously and alleviates the dependence on expert prompts during the evaluation phase, significantly broadening SAM's applicability. Additionally, we integrate a self-distillation module to enhance the self-prompting process further. Extensive experiments across various domain specific datasets validate the effectiveness of the proposed SAM-SP. Our SAM-SP not only alleviates the reliance on expert prompts but also exhibits superior segmentation performance comparing to the state-of-the-art task-specific segmentation approaches, the vanilla SAM, and SAM-based approaches.
WebRPG: Automatic Web Rendering Parameters Generation for Visual Presentation
Jul 22, 2024
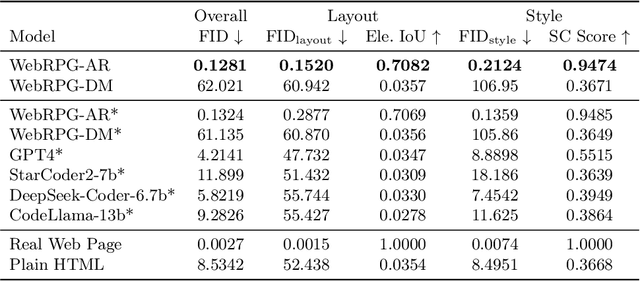


In the era of content creation revolution propelled by advancements in generative models, the field of web design remains unexplored despite its critical role in modern digital communication. The web design process is complex and often time-consuming, especially for those with limited expertise. In this paper, we introduce Web Rendering Parameters Generation (WebRPG), a new task that aims at automating the generation for visual presentation of web pages based on their HTML code. WebRPG would contribute to a faster web development workflow. Since there is no existing benchmark available, we develop a new dataset for WebRPG through an automated pipeline. Moreover, we present baseline models, utilizing VAE to manage numerous elements and rendering parameters, along with custom HTML embedding for capturing essential semantic and hierarchical information from HTML. Extensive experiments, including customized quantitative evaluations for this specific task, are conducted to evaluate the quality of the generated results.
ProcTag: Process Tagging for Assessing the Efficacy of Document Instruction Data
Jul 17, 2024

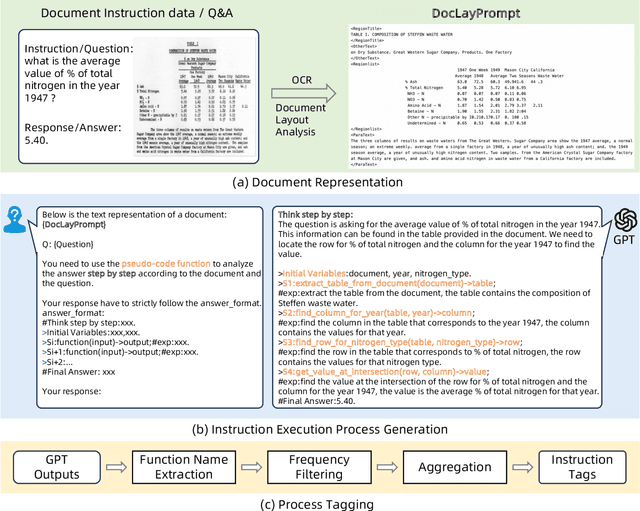

Recently, large language models (LLMs) and multimodal large language models (MLLMs) have demonstrated promising results on document visual question answering (VQA) task, particularly after training on document instruction datasets. An effective evaluation method for document instruction data is crucial in constructing instruction data with high efficacy, which, in turn, facilitates the training of LLMs and MLLMs for document VQA. However, most existing evaluation methods for instruction data are limited to the textual content of the instructions themselves, thereby hindering the effective assessment of document instruction datasets and constraining their construction. In this paper, we propose ProcTag, a data-oriented method that assesses the efficacy of document instruction data. ProcTag innovatively performs tagging on the execution process of instructions rather than the instruction text itself. By leveraging the diversity and complexity of these tags to assess the efficacy of the given dataset, ProcTag enables selective sampling or filtering of document instructions. Furthermore, DocLayPrompt, a novel semi-structured layout-aware document prompting strategy, is proposed for effectively representing documents. Experiments demonstrate that sampling existing open-sourced and generated document VQA/instruction datasets with ProcTag significantly outperforms current methods for evaluating instruction data. Impressively, with ProcTag-based sampling in the generated document datasets, only 30.5\% of the document instructions are required to achieve 100\% efficacy compared to the complete dataset. The code is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/ProcTag.
LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
Apr 08, 2024Recently, leveraging large language models (LLMs) or multimodal large language models (MLLMs) for document understanding has been proven very promising. However, previous works that employ LLMs/MLLMs for document understanding have not fully explored and utilized the document layout information, which is vital for precise document understanding. In this paper, we propose LayoutLLM, an LLM/MLLM based method for document understanding. The core of LayoutLLM is a layout instruction tuning strategy, which is specially designed to enhance the comprehension and utilization of document layouts. The proposed layout instruction tuning strategy consists of two components: Layout-aware Pre-training and Layout-aware Supervised Fine-tuning. To capture the characteristics of document layout in Layout-aware Pre-training, three groups of pre-training tasks, corresponding to document-level, region-level and segment-level information, are introduced. Furthermore, a novel module called layout chain-of-thought (LayoutCoT) is devised to enable LayoutLLM to focus on regions relevant to the question and generate accurate answers. LayoutCoT is effective for boosting the performance of document understanding. Meanwhile, it brings a certain degree of interpretability, which could facilitate manual inspection and correction. Experiments on standard benchmarks show that the proposed LayoutLLM significantly outperforms existing methods that adopt open-source 7B LLMs/MLLMs for document understanding. The training data of the LayoutLLM is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LayoutLLM
Less is More : A Closer Look at Multi-Modal Few-Shot Learning
Jan 10, 2024Few-shot Learning aims to learn and distinguish new categories with a very limited number of available images, presenting a significant challenge in the realm of deep learning. Recent researchers have sought to leverage the additional textual or linguistic information of these rare categories with a pre-trained language model to facilitate learning, thus partially alleviating the problem of insufficient supervision signals. However, the full potential of the textual information and pre-trained language model have been underestimated in the few-shot learning till now, resulting in limited performance enhancements. To address this, we propose a simple but effective framework for few-shot learning tasks, specifically designed to exploit the textual information and language model. In more detail, we explicitly exploit the zero-shot capability of the pre-trained language model with the learnable prompt. And we just add the visual feature with the textual feature for inference directly without the intricate designed fusion modules in previous works. Additionally, we apply the self-ensemble and distillation to further enhance these components. Our extensive experiments conducted across four widely used few-shot datasets demonstrate that our simple framework achieves impressive results. Particularly noteworthy is its outstanding performance in the 1-shot learning task, surpassing state-of-the-art methods by an average of 3.0\% in classification accuracy. \footnote{We will make the source codes of the proposed framework publicly available upon acceptance. }.
LORE++: Logical Location Regression Network for Table Structure Recognition with Pre-training
Jan 03, 2024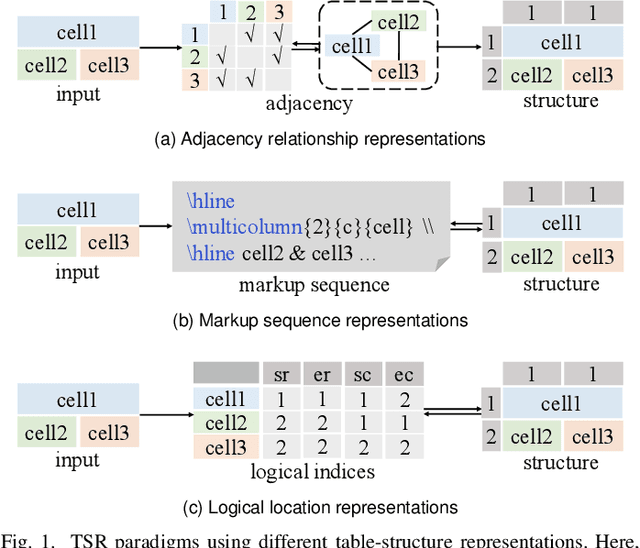

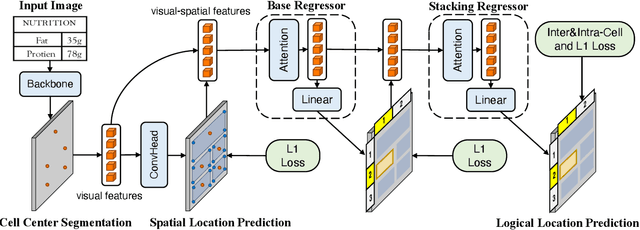
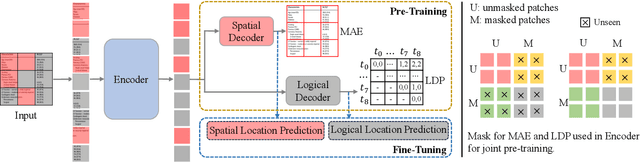
Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes or learning to directly generate the corresponding markup sequences from the table images. However, existing approaches either count on additional heuristic rules to recover the table structures, or face challenges in capturing long-range dependencies within tables, resulting in increased complexity. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time regresses logical location as well as spatial location of table cells in a unified network. Our proposed LORE is conceptually simpler, easier to train, and more accurate than other paradigms of TSR. Moreover, inspired by the persuasive success of pre-trained models on a number of computer vision and natural language processing tasks, we propose two pre-training tasks to enrich the spatial and logical representations at the feature level of LORE, resulting in an upgraded version called LORE++. The incorporation of pre-training in LORE++ has proven to enjoy significant advantages, leading to a substantial enhancement in terms of accuracy, generalization, and few-shot capability compared to its predecessor. Experiments on standard benchmarks against methods of previous paradigms demonstrate the superiority of LORE++, which highlights the potential and promising prospect of the logical location regression paradigm for TSR.