 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Bootstrapped Targeted Finding Guidance for Factual MLLM-based Medical Report Generation
Feb 28, 2026The automatic generation of medical reports utilizing Multimodal Large Language Models (MLLMs) frequently encounters challenges related to factual instability, which may manifest as the omission of findings or the incorporation of inaccurate information, thereby constraining their applicability in clinical settings. Current methodologies typically produce reports based directly on image features, which inherently lack a definitive factual basis. In response to this limitation, we introduce Fact-Flow, an innovative framework that separates the process of visual fact identification from the generation of reports. This is achieved by initially predicting clinical findings from the image, which subsequently directs the MLLM to produce a report that is factually precise. A pivotal advancement of our approach is a pipeline that leverages a Large Language Model (LLM) to autonomously create a dataset of labeled medical findings, effectively eliminating the need for expensive manual annotation. Extensive experimental evaluations conducted on two disease-focused medical datasets validate the efficacy of our method, demonstrating a significant enhancement in factual accuracy compared to state-of-the-art models, while concurrently preserving high standards of text quality.
One Head Eight Arms: Block Matrix based Low Rank Adaptation for CLIP-based Few-Shot Learning
Jan 28, 2025



Recent advancements in fine-tuning Vision-Language Foundation Models (VLMs) have garnered significant attention for their effectiveness in downstream few-shot learning tasks.While these recent approaches exhibits some performance improvements, they often suffer from excessive training parameters and high computational costs. To address these challenges, we propose a novel Block matrix-based low-rank adaptation framework, called Block-LoRA, for fine-tuning VLMs on downstream few-shot tasks. Inspired by recent work on Low-Rank Adaptation (LoRA), Block-LoRA partitions the original low-rank decomposition matrix of LoRA into a series of sub-matrices while sharing all down-projection sub-matrices. This structure not only reduces the number of training parameters, but also transforms certain complex matrix multiplication operations into simpler matrix addition, significantly lowering the computational cost of fine-tuning. Notably, Block-LoRA enables fine-tuning CLIP on the ImageNet few-shot benchmark using a single 24GB GPU. We also show that Block-LoRA has the more tighter bound of generalization error than vanilla LoRA. Without bells and whistles, extensive experiments demonstrate that Block-LoRA achieves competitive performance compared to state-of-the-art CLIP-based few-shot methods, while maintaining a low training parameters count and reduced computational overhead.
SAM-SP: Self-Prompting Makes SAM Great Again
Aug 22, 2024



The recently introduced Segment Anything Model (SAM), a Visual Foundation Model (VFM), has demonstrated impressive capabilities in zero-shot segmentation tasks across diverse natural image datasets. Despite its success, SAM encounters noticeably performance degradation when applied to specific domains, such as medical images. Current efforts to address this issue have involved fine-tuning strategies, intended to bolster the generalizability of the vanilla SAM. However, these approaches still predominantly necessitate the utilization of domain specific expert-level prompts during the evaluation phase, which severely constrains the model's practicality. To overcome this limitation, we introduce a novel self-prompting based fine-tuning approach, called SAM-SP, tailored for extending the vanilla SAM model. Specifically, SAM-SP leverages the output from the previous iteration of the model itself as prompts to guide subsequent iteration of the model. This self-prompting module endeavors to learn how to generate useful prompts autonomously and alleviates the dependence on expert prompts during the evaluation phase, significantly broadening SAM's applicability. Additionally, we integrate a self-distillation module to enhance the self-prompting process further. Extensive experiments across various domain specific datasets validate the effectiveness of the proposed SAM-SP. Our SAM-SP not only alleviates the reliance on expert prompts but also exhibits superior segmentation performance comparing to the state-of-the-art task-specific segmentation approaches, the vanilla SAM, and SAM-based approaches.
A High-Resolution Dataset for Instance Detection with Multi-View Instance Capture
Oct 30, 2023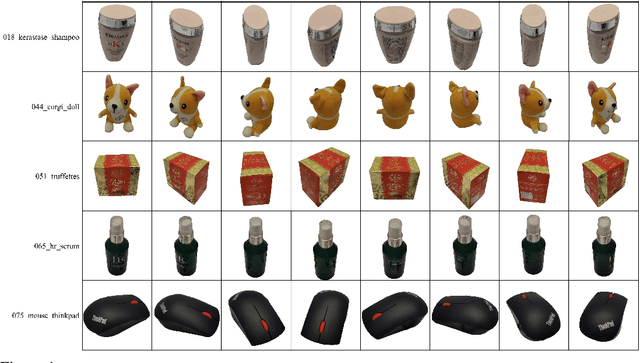
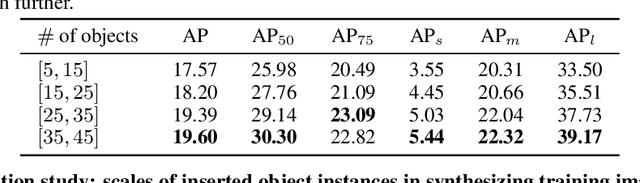
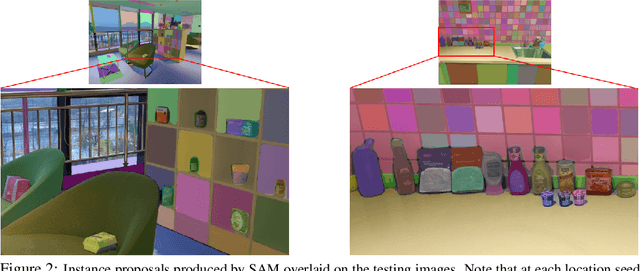
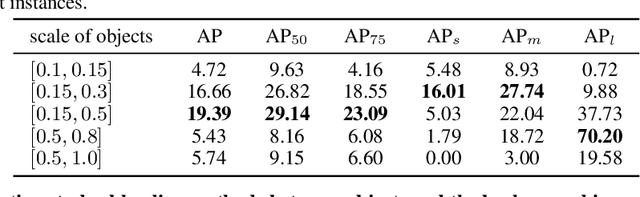
Instance detection (InsDet) is a long-lasting problem in robotics and computer vision, aiming to detect object instances (predefined by some visual examples) in a cluttered scene. Despite its practical significance, its advancement is overshadowed by Object Detection, which aims to detect objects belonging to some predefined classes. One major reason is that current InsDet datasets are too small in scale by today's standards. For example, the popular InsDet dataset GMU (published in 2016) has only 23 instances, far less than COCO (80 classes), a well-known object detection dataset published in 2014. We are motivated to introduce a new InsDet dataset and protocol. First, we define a realistic setup for InsDet: training data consists of multi-view instance captures, along with diverse scene images allowing synthesizing training images by pasting instance images on them with free box annotations. Second, we release a real-world database, which contains multi-view capture of 100 object instances, and high-resolution (6k x 8k) testing images. Third, we extensively study baseline methods for InsDet on our dataset, analyze their performance and suggest future work. Somewhat surprisingly, using the off-the-shelf class-agnostic segmentation model (Segment Anything Model, SAM) and the self-supervised feature representation DINOv2 performs the best, achieving >10 AP better than end-to-end trained InsDet models that repurpose object detectors (e.g., FasterRCNN and RetinaNet).
Q-Net: Query-Informed Few-Shot Medical Image Segmentation
Aug 24, 2022
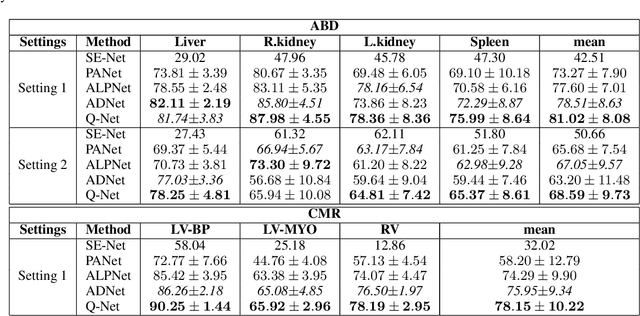
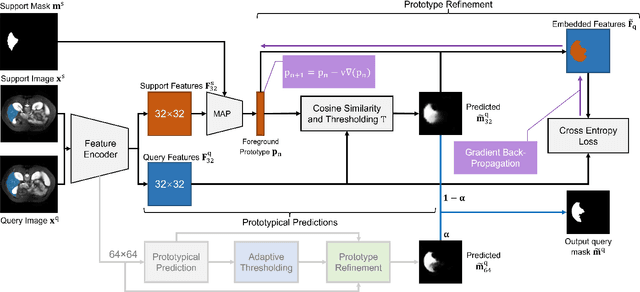
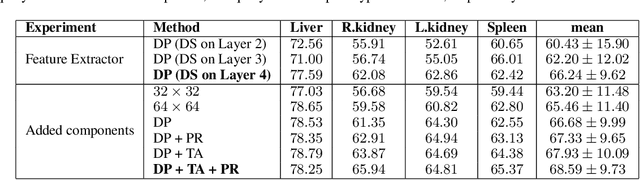
Deep learning has achieved tremendous success in computer vision, while medical image segmentation (MIS) remains a challenge, due to the scarcity of data annotations. Meta-learning techniques for few-shot segmentation (Meta-FSS) have been widely used to tackle this challenge, while they neglect possible distribution shifts between the query image and the support set. In contrast, an experienced clinician can perceive and address such shifts by borrowing information from the query image, then fine-tune or calibrate his (her) prior cognitive model accordingly. Inspired by this, we propose Q-Net, a Query-informed Meta-FSS approach, which mimics in spirit the learning mechanism of an expert clinician. We build Q-Net based on ADNet, a recently proposed anomaly detection-inspired method. Specifically, we add two query-informed computation modules into ADNet, namely a query-informed threshold adaptation module and a query-informed prototype refinement module. Combining them with a dual-path extension of the feature extraction module, Q-Net achieves state-of-the-art performance on two widely used datasets, which are composed of abdominal MR images and cardiac MR images, respectively. Our work sheds light on a novel way to improve Meta-FSS techniques by leveraging query information.