 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Net: Query-Informed Few-Shot Medical Image Segmentation
Aug 24, 2022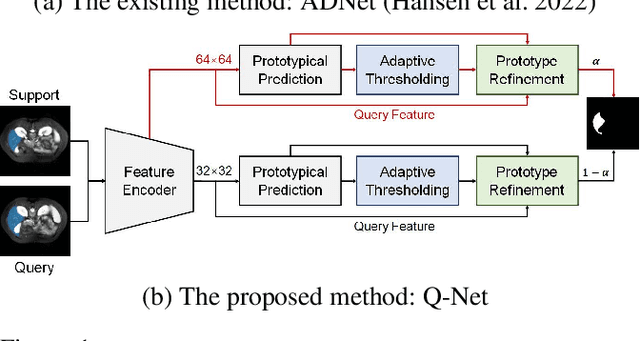
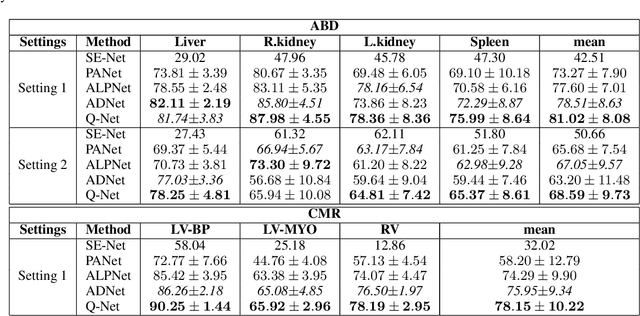
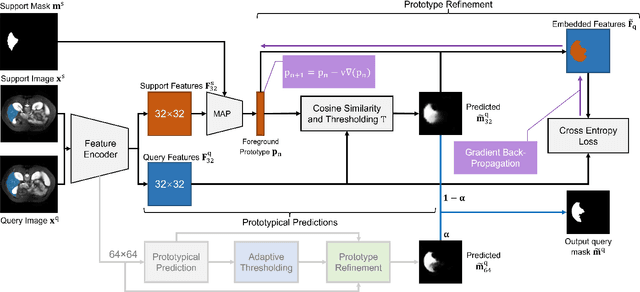
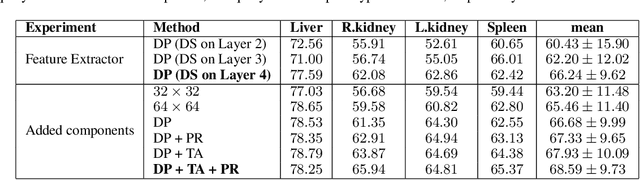
Deep learning has achieved tremendous success in computer vision, while medical image segmentation (MIS) remains a challenge, due to the scarcity of data annotations. Meta-learning techniques for few-shot segmentation (Meta-FSS) have been widely used to tackle this challenge, while they neglect possible distribution shifts between the query image and the support set. In contrast, an experienced clinician can perceive and address such shifts by borrowing information from the query image, then fine-tune or calibrate his (her) prior cognitive model accordingly. Inspired by this, we propose Q-Net, a Query-informed Meta-FSS approach, which mimics in spirit the learning mechanism of an expert clinician. We build Q-Net based on ADNet, a recently proposed anomaly detection-inspired method. Specifically, we add two query-informed computation modules into ADNet, namely a query-informed threshold adaptation module and a query-informed prototype refinement module. Combining them with a dual-path extension of the feature extraction module, Q-Net achieves state-of-the-art performance on two widely used datasets, which are composed of abdominal MR images and cardiac MR images, respectively. Our work sheds light on a novel way to improve Meta-FSS techniques by leveraging query information.
PFGE: Parsimonious Fast Geometric Ensembling of DNNs
Feb 23, 2022
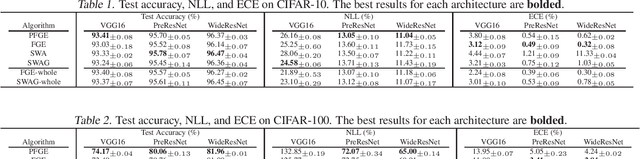
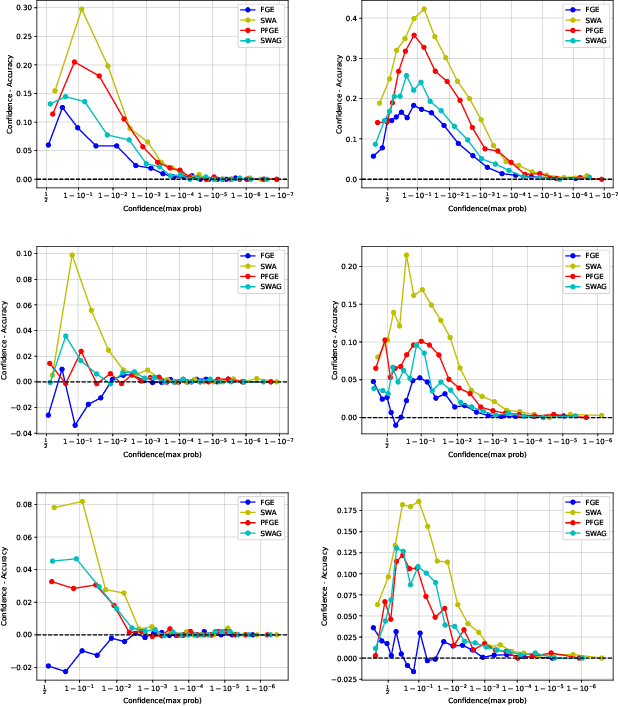

Ensemble methods have been widely used to improve the performance of machine learning methods in terms of generalization and uncertainty calibration, while they struggle to use in deep learning systems, as training an ensemble of deep neural networks (DNNs) and then deploying them for online prediction incur an extremely higher computational overhead of model training and test-time predictions. Recently, several advanced techniques, such as fast geometric ensembling (FGE) and snapshot ensemble, have been proposed. These methods can train the model ensembles in the same time as a single model, thus getting around the hurdle of training time. However, their overhead of model recording and test-time computations remains much higher than their single model based counterparts. Here we propose a parsimonious FGE (PFGE) that employs a lightweight ensemble of higher-performing DNNs generated by several successively-performed procedures of stochastic weight averaging. Experimental results across different advanced DNN architectures on different datasets, namely CIFAR-$\{$10,100$\}$ and Imagenet, demonstrate its performance. Results show that, compared with state-of-the-art methods, PFGE achieves better generalization performance and satisfactory calibration capability, while the overhead of model recording and test-time predictions is significantly reduced.
Stochastic Weight Averaging Revisited
Jan 03, 2022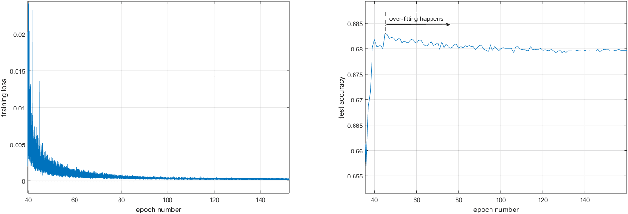

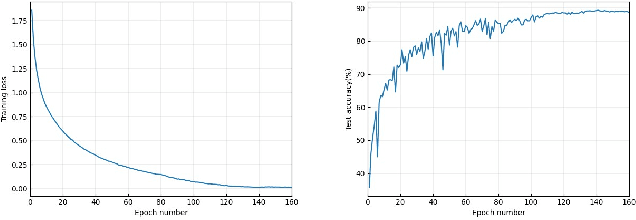
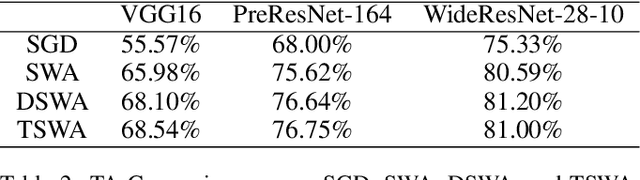
Stochastic weight averaging (SWA) is recognized as a simple while one effective approach to improve the generalization of stochastic gradient descent (SGD) for training deep neural networks (DNNs). A common insight to explain its success is that averaging weights following an SGD process equipped with cyclical or high constant learning rates can discover wider optima, which then lead to better generalization. We give a new insight that does not concur with the above one. We characterize that SWA's performance is highly dependent on to what extent the SGD process that runs before SWA converges, and the operation of weight averaging only contributes to variance reduction. This new insight suggests practical guides on better algorithm design. As an instantiation, we show that following an SGD process with insufficient convergence, running SWA more times leads to continual incremental benefits in terms of generalization. Our findings are corroborated by extensive experiments across different network architectures, including a baseline CNN, PreResNet-164, WideResNet-28-10, VGG16, ResNet-50, ResNet-152, DenseNet-161, and different datasets including CIFAR-{10,100}, and Imagenet.