 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGainAdaptor: Learning Quadrupedal Locomotion with Dual Actors for Adaptable and Energy-Efficient Walking on Various Terrains
Dec 12, 2024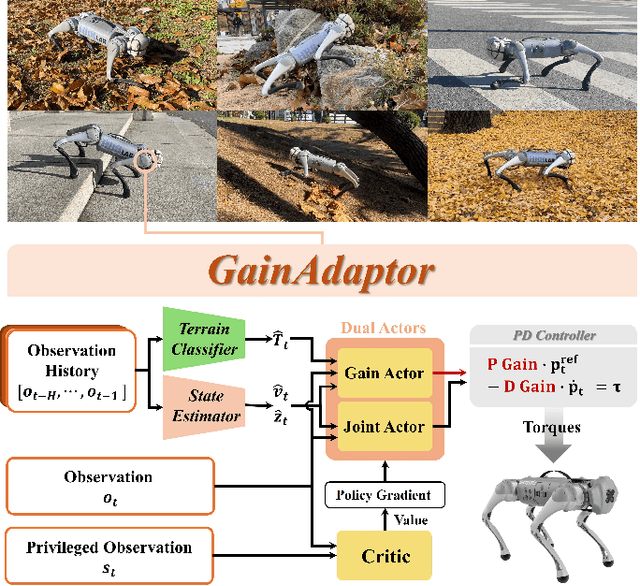


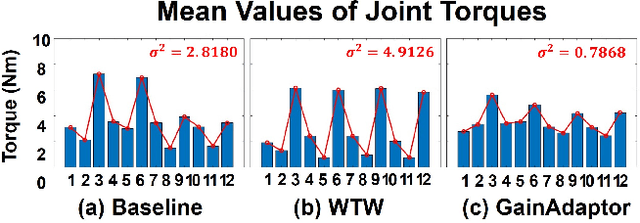
Deep reinforcement learning (DRL) has emerged as an innovative solution for controlling legged robots in challenging environments using minimalist architectures. Traditional control methods for legged robots, such as inverse dynamics, either directly manage joint torques or use proportional-derivative (PD) controllers to regulate joint positions at a higher level. In case of DRL, direct torque control presents significant challenges, leading to a preference for joint position control. However, this approach necessitates careful adjustment of joint PD gains, which can limit both adaptability and efficiency. In this paper, we propose GainAdaptor, an adaptive gain control framework that autonomously tunes joint PD gains to enhance terrain adaptability and energy efficiency. The framework employs a dual-actor algorithm to dynamically adjust the PD gains based on varying ground conditions. By utilizing a divided action space, GainAdaptor efficiently learns stable and energy-efficient locomotion. We validate the effectiveness of the proposed method through experiments conducted on a Unitree Go1 robot, demonstrating improved locomotion performance across diverse terrains.
3DPFIX: Improving Remote Novices' 3D Printing Troubleshooting through Human-AI Collaboration
Feb 02, 2024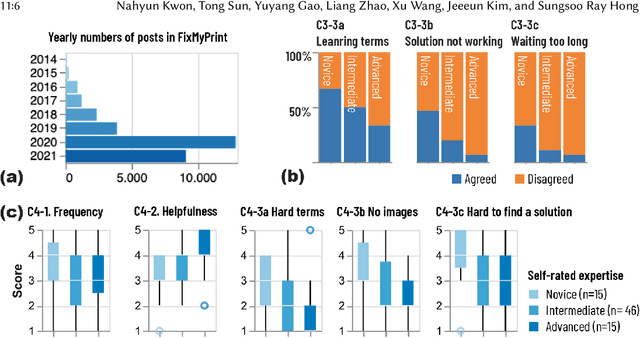
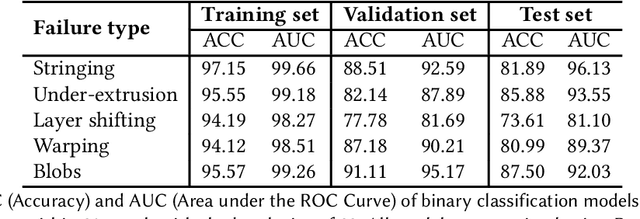
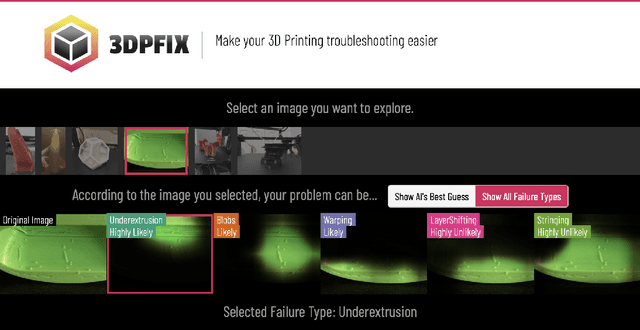

The widespread consumer-grade 3D printers and learning resources online enable novices to self-train in remote settings. While troubleshooting plays an essential part of 3D printing, the process remains challenging for many remote novices even with the help of well-developed online sources, such as online troubleshooting archives and online community help. We conducted a formative study with 76 active 3D printing users to learn how remote novices leverage online resources in troubleshooting and their challenges. We found that remote novices cannot fully utilize online resources. For example, the online archives statically provide general information, making it hard to search and relate their unique cases with existing descriptions. Online communities can potentially ease their struggles by providing more targeted suggestions, but a helper who can provide custom help is rather scarce, making it hard to obtain timely assistance. We propose 3DPFIX, an interactive 3D troubleshooting system powered by the pipeline to facilitate Human-AI Collaboration, designed to improve novices' 3D printing experiences and thus help them easily accumulate their domain knowledge. We built 3DPFIX that supports automated diagnosis and solution-seeking. 3DPFIX was built upon shared dialogues about failure cases from Q&A discourses accumulated in online communities. We leverage social annotations (i.e., comments) to build an annotated failure image dataset for AI classifiers and extract a solution pool. Our summative study revealed that using 3DPFIX helped participants spend significantly less effort in diagnosing failures and finding a more accurate solution than relying on their common practice. We also found that 3DPFIX users learn about 3D printing domain-specific knowledge. We discuss the implications of leveraging community-driven data in developing future Human-AI Collaboration designs.
AccessLens: Auto-detecting Inaccessibility of Everyday Objects
Jan 29, 2024


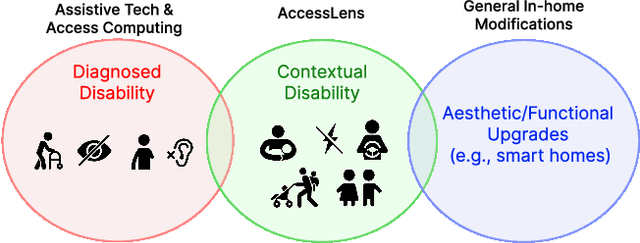
In our increasingly diverse society, everyday physical interfaces often present barriers, impacting individuals across various contexts. This oversight, from small cabinet knobs to identical wall switches that can pose different contextual challenges, highlights an imperative need for solutions. Leveraging low-cost 3D-printed augmentations such as knob magnifiers and tactile labels seems promising, yet the process of discovering unrecognized barriers remains challenging because disability is context-dependent. We introduce AccessLens, an end-to-end system designed to identify inaccessible interfaces in daily objects, and recommend 3D-printable augmentations for accessibility enhancement. Our approach involves training a detector using the novel AccessDB dataset designed to automatically recognize 21 distinct Inaccessibility Classes (e.g., bar-small and round-rotate) within 6 common object categories (e.g., handle and knob). AccessMeta serves as a robust way to build a comprehensive dictionary linking these accessibility classes to open-source 3D augmentation designs. Experiments demonstrate our detector's performance in detecting inaccessible objects.
A High-Resolution Dataset for Instance Detection with Multi-View Instance Capture
Oct 30, 2023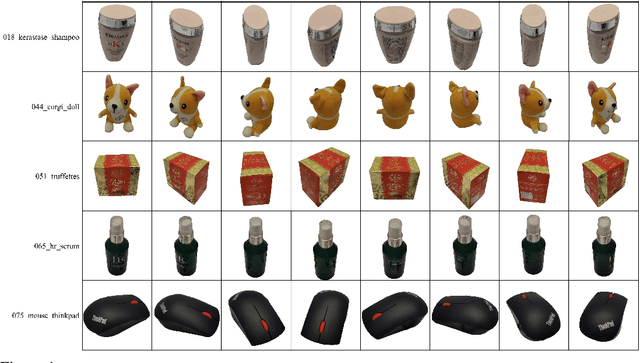
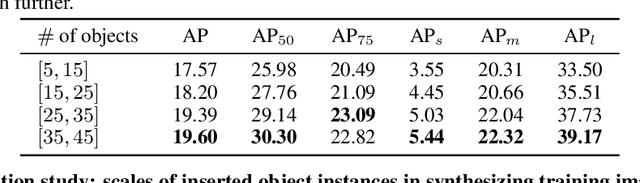
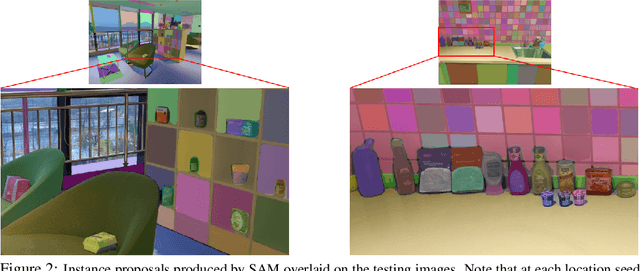
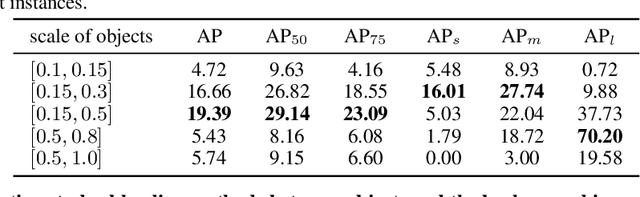
Instance detection (InsDet) is a long-lasting problem in robotics and computer vision, aiming to detect object instances (predefined by some visual examples) in a cluttered scene. Despite its practical significance, its advancement is overshadowed by Object Detection, which aims to detect objects belonging to some predefined classes. One major reason is that current InsDet datasets are too small in scale by today's standards. For example, the popular InsDet dataset GMU (published in 2016) has only 23 instances, far less than COCO (80 classes), a well-known object detection dataset published in 2014. We are motivated to introduce a new InsDet dataset and protocol. First, we define a realistic setup for InsDet: training data consists of multi-view instance captures, along with diverse scene images allowing synthesizing training images by pasting instance images on them with free box annotations. Second, we release a real-world database, which contains multi-view capture of 100 object instances, and high-resolution (6k x 8k) testing images. Third, we extensively study baseline methods for InsDet on our dataset, analyze their performance and suggest future work. Somewhat surprisingly, using the off-the-shelf class-agnostic segmentation model (Segment Anything Model, SAM) and the self-supervised feature representation DINOv2 performs the best, achieving >10 AP better than end-to-end trained InsDet models that repurpose object detectors (e.g., FasterRCNN and RetinaNet).