 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccessLens: Auto-detecting Inaccessibility of Everyday Objects
Jan 29, 2024


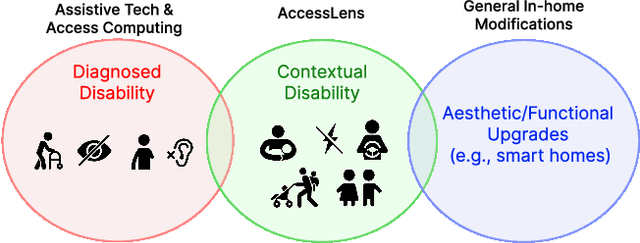
In our increasingly diverse society, everyday physical interfaces often present barriers, impacting individuals across various contexts. This oversight, from small cabinet knobs to identical wall switches that can pose different contextual challenges, highlights an imperative need for solutions. Leveraging low-cost 3D-printed augmentations such as knob magnifiers and tactile labels seems promising, yet the process of discovering unrecognized barriers remains challenging because disability is context-dependent. We introduce AccessLens, an end-to-end system designed to identify inaccessible interfaces in daily objects, and recommend 3D-printable augmentations for accessibility enhancement. Our approach involves training a detector using the novel AccessDB dataset designed to automatically recognize 21 distinct Inaccessibility Classes (e.g., bar-small and round-rotate) within 6 common object categories (e.g., handle and knob). AccessMeta serves as a robust way to build a comprehensive dictionary linking these accessibility classes to open-source 3D augmentation designs. Experiments demonstrate our detector's performance in detecting inaccessible objects.
Literature Triage on Genomic Variation Publications by Knowledge-enhanced Multi-channel CNN
May 08, 2020
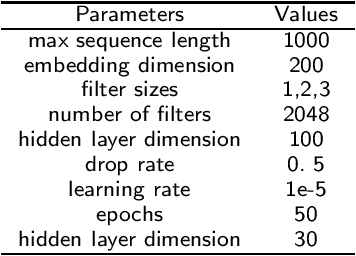

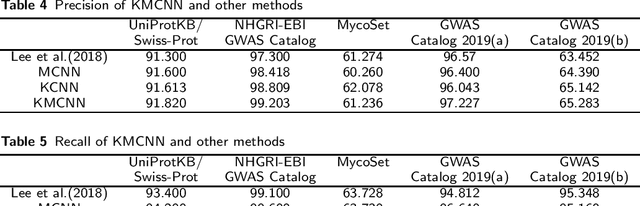
Background: To investigate the correlation between genomic variation and certain diseases or phenotypes, the fundamental task is to screen out the concerning publications from massive literature, which is called literature triage. Some knowledge bases, including UniProtKB/Swiss-Prot and NHGRI-EBI GWAS Catalog are created for collecting concerning publications. These publications are manually curated by experts, which is time-consuming. Moreover, the manual curation of information from literature is not scalable due to the rapidly increasing amount of publications. In order to cut down the cost of literature triage, machine-learning models were adopted to automatically identify biomedical publications. Methods: Comparing to previous studies utilizing machine-learning models for literature triage, we adopt a multi-channel convolutional network to utilize rich textual information and meanwhile bridge the semantic gaps from different corpora. In addition, knowledge embeddings learned from UMLS is also used to provide extra medical knowledge beyond textual features in the process of triage. Results: We demonstrate that our model outperforms the state-of-the-art models over 5 datasets with the help of knowledge embedding and multiple channels. Our model improves the accuracy of biomedical literature triage results. Conclusions: Multiple channels and knowledge embeddings enhance the performance of the CNN model in the task of biomedical literature triage. Keywords: Literature Triage; Knowledge Embedding; Multi-channel Convolutional Network
The influence of Chunking on Dependency Crossing and Distance
Sep 03, 2015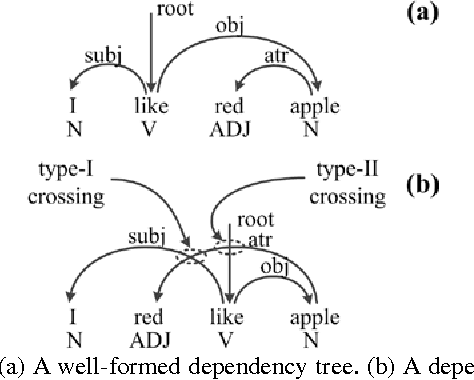
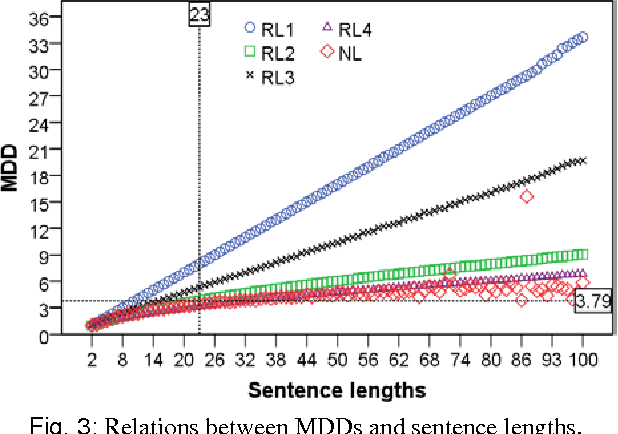
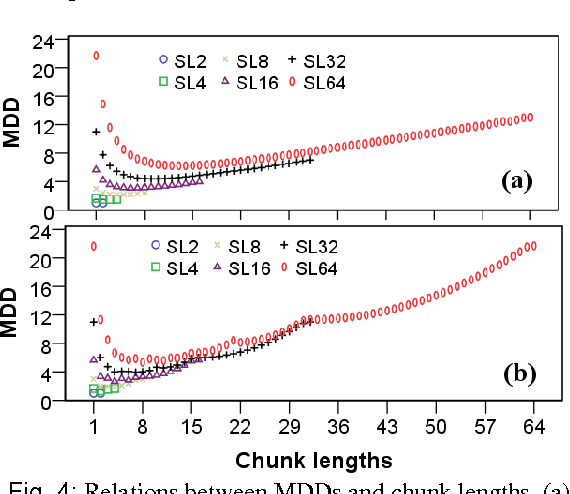

This paper hypothesizes that chunking plays important role in reducing dependency distance and dependency crossings. Computer simulations, when compared with natural languages,show that chunking reduces mean dependency distance (MDD) of a linear sequence of nodes (constrained by continuity or projectivity) to that of natural languages. More interestingly, chunking alone brings about less dependency crossings as well, though having failed to reduce them, to such rarity as found in human languages. These results suggest that chunking may play a vital role in the minimization of dependency distance, and a somewhat contributing role in the rarity of dependency crossing. In addition, the results point to a possibility that the rarity of dependency crossings is not a mere side-effect of minimization of dependency distance, but a linguistic phenomenon with its own motivations.