 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiterature Triage on Genomic Variation Publications by Knowledge-enhanced Multi-channel CNN
Paper and Code

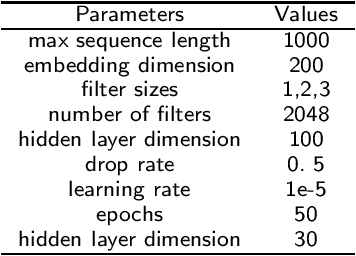

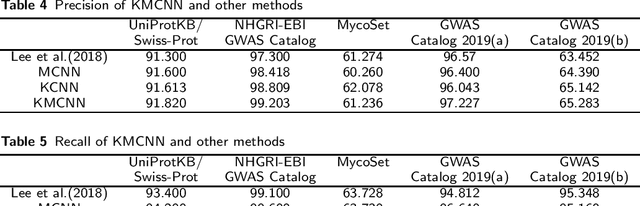
Background: To investigate the correlation between genomic variation and certain diseases or phenotypes, the fundamental task is to screen out the concerning publications from massive literature, which is called literature triage. Some knowledge bases, including UniProtKB/Swiss-Prot and NHGRI-EBI GWAS Catalog are created for collecting concerning publications. These publications are manually curated by experts, which is time-consuming. Moreover, the manual curation of information from literature is not scalable due to the rapidly increasing amount of publications. In order to cut down the cost of literature triage, machine-learning models were adopted to automatically identify biomedical publications. Methods: Comparing to previous studies utilizing machine-learning models for literature triage, we adopt a multi-channel convolutional network to utilize rich textual information and meanwhile bridge the semantic gaps from different corpora. In addition, knowledge embeddings learned from UMLS is also used to provide extra medical knowledge beyond textual features in the process of triage. Results: We demonstrate that our model outperforms the state-of-the-art models over 5 datasets with the help of knowledge embedding and multiple channels. Our model improves the accuracy of biomedical literature triage results. Conclusions: Multiple channels and knowledge embeddings enhance the performance of the CNN model in the task of biomedical literature triage. Keywords: Literature Triage; Knowledge Embedding; Multi-channel Convolutional Network