 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical patterns of word frequency suggesting the probabilistic nature of human languages
Dec 01, 2020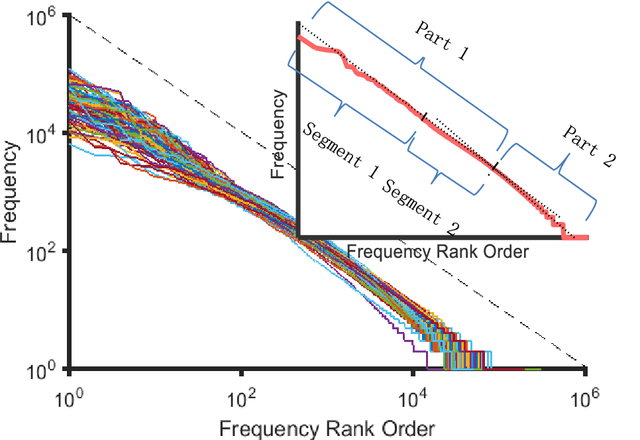
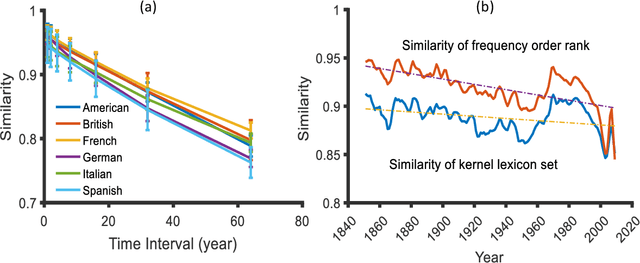
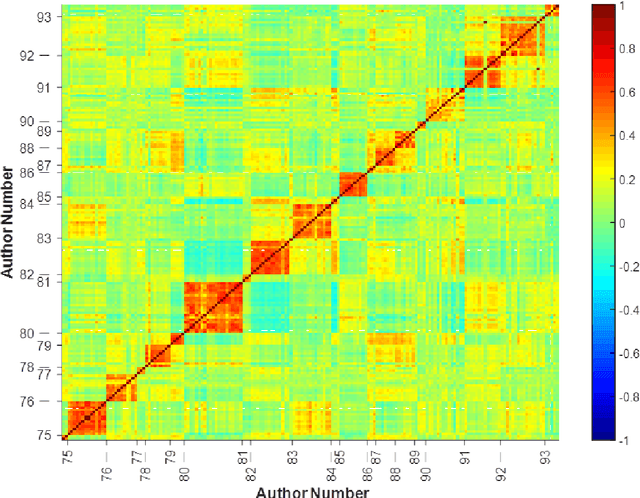
Traditional linguistic theories have largely regard language as a formal system composed of rigid rules. However, their failures in processing real language, the recent successes in statistical natural language processing, and the findings of many psychological experiments have suggested that language may be more a probabilistic system than a formal system, and thus cannot be faithfully modeled with the either/or rules of formal linguistic theory. The present study, based on authentic language data, confirmed that those important linguistic issues, such as linguistic universal, diachronic drift, and language variations can be translated into probability and frequency patterns in parole. These findings suggest that human language may well be probabilistic systems by nature, and that statistical may well make inherent properties of human languages.
Zipf's law in 50 languages: its structural pattern, linguistic interpretation, and cognitive motivation
Jul 05, 2018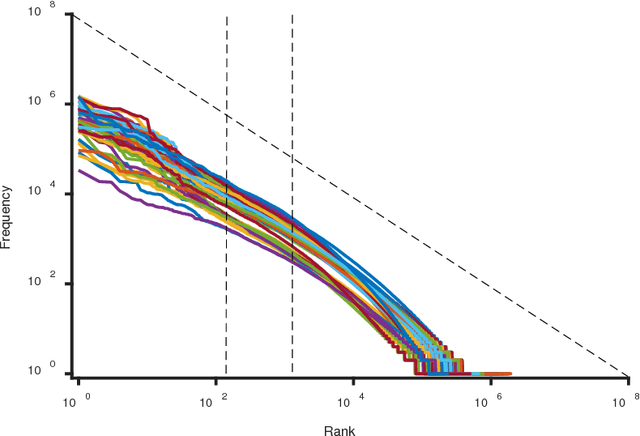
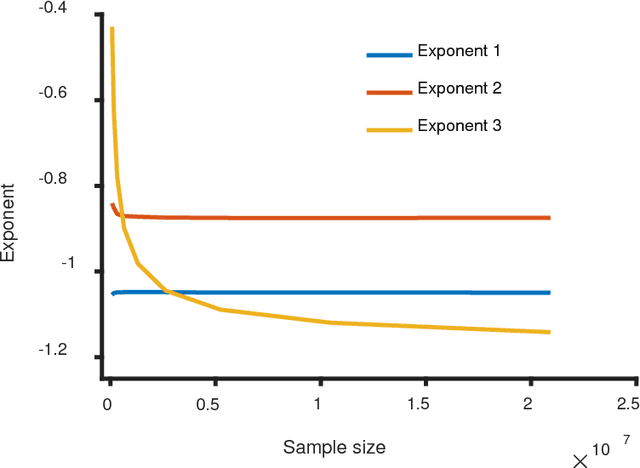
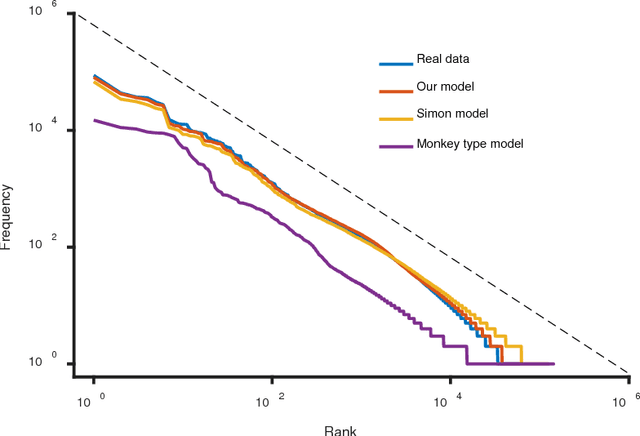
Zipf's law has been found in many human-related fields, including language, where the frequency of a word is persistently found as a power law function of its frequency rank, known as Zipf's law. However, there is much dispute whether it is a universal law or a statistical artifact, and little is known about what mechanisms may have shaped it. To answer these questions, this study conducted a large scale cross language investigation into Zipf's law. The statistical results show that Zipf's laws in 50 languages all share a 3-segment structural pattern, with each segment demonstrating distinctive linguistic properties and the lower segment invariably bending downwards to deviate from theoretical expectation. This finding indicates that this deviation is a fundamental and universal feature of word frequency distributions in natural languages, not the statistical error of low frequency words. A computer simulation based on the dual-process theory yields Zipf's law with the same structural pattern, suggesting that Zipf's law of natural languages are motivated by common cognitive mechanisms. These results show that Zipf's law in languages is motivated by cognitive mechanisms like dual-processing that govern human verbal behaviors.
Dependency length minimization: Puzzles and Promises
Sep 15, 2015In the recent issue of PNAS, Futrell et al. claims that their study of 37 languages gives the first large scale cross-language evidence for Dependency Length Minimization, which is an overstatement that ignores similar previous researches. In addition,this study seems to pay no attention to factors like the uniformity of genres,which weakens the validity of the argument that DLM is universal. Another problem is that this study sets the baseline random language as projective, which fails to truly uncover the difference between natural language and random language, since projectivity is an important feature of many natural languages. Finally, the paper contends an "apparent relationship between head finality and dependency length" despite the lack of an explicit statistical comparison, which renders this conclusion rather hasty and improper.
The influence of Chunking on Dependency Crossing and Distance
Sep 03, 2015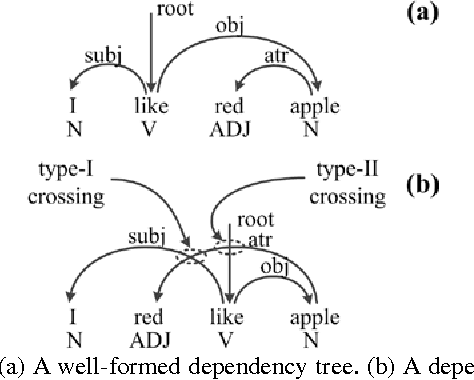
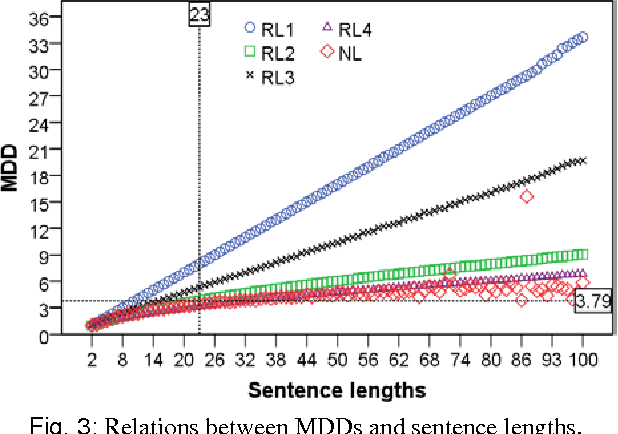
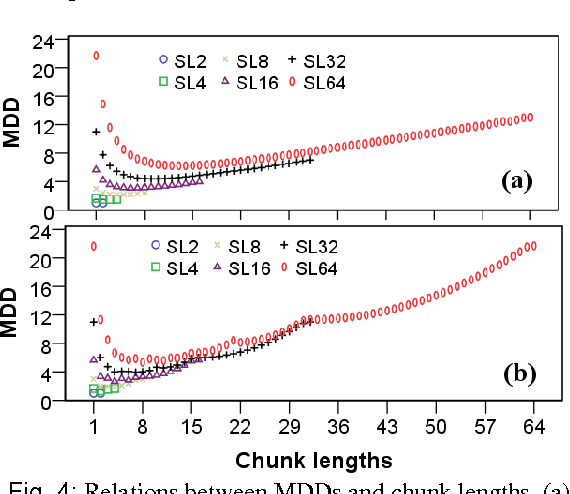

This paper hypothesizes that chunking plays important role in reducing dependency distance and dependency crossings. Computer simulations, when compared with natural languages,show that chunking reduces mean dependency distance (MDD) of a linear sequence of nodes (constrained by continuity or projectivity) to that of natural languages. More interestingly, chunking alone brings about less dependency crossings as well, though having failed to reduce them, to such rarity as found in human languages. These results suggest that chunking may play a vital role in the minimization of dependency distance, and a somewhat contributing role in the rarity of dependency crossing. In addition, the results point to a possibility that the rarity of dependency crossings is not a mere side-effect of minimization of dependency distance, but a linguistic phenomenon with its own motivations.