 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe distribution of information content in English sentences
Sep 24, 2016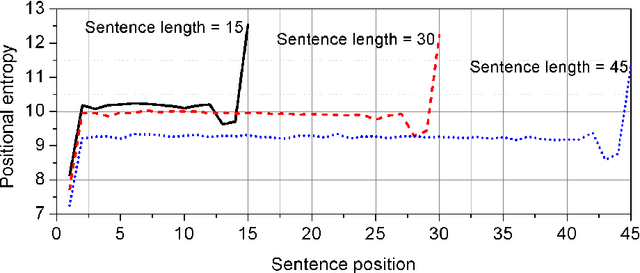
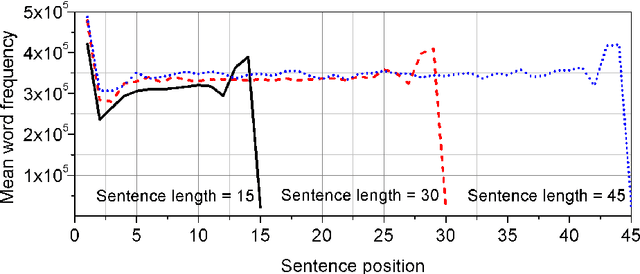
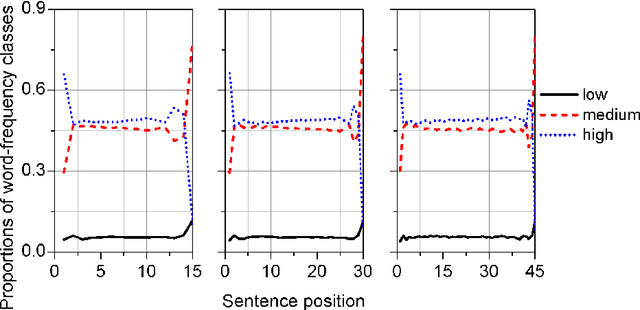
Sentence is a basic linguistic unit, however, little is known about how information content is distributed across different positions of a sentence. Based on authentic language data of English, the present study calculated the entropy and other entropy-related statistics for different sentence positions. The statistics indicate a three-step staircase-shaped distribution pattern, with entropy in the initial position lower than the medial positions (positions other than the initial and final), the medial positions lower than the final position and the medial positions showing no significant difference. The results suggest that: (1) the hypotheses of Constant Entropy Rate and Uniform Information Density do not hold for the sentence-medial positions; (2) the context of a word in a sentence should not be simply defined as all the words preceding it in the same sentence; and (3) the contextual information content in a sentence does not accumulate incrementally but follows a pattern of "the whole is greater than the sum of parts".
Existence of Hierarchies and Human's Pursuit of Top Hierarchy Lead to Power Law
Sep 24, 2016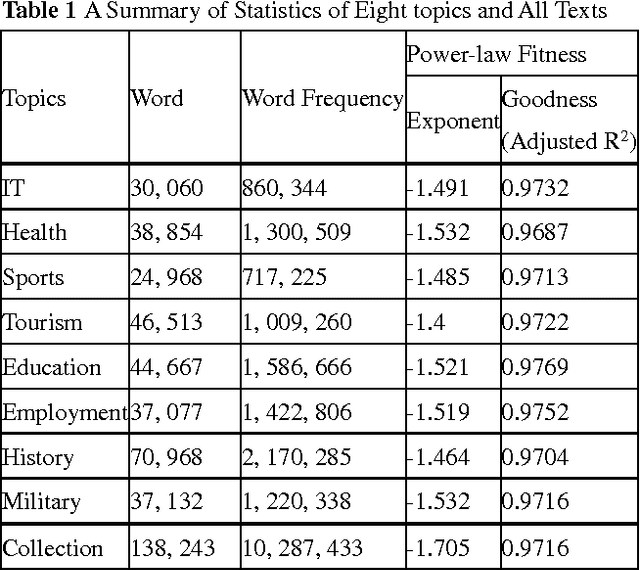
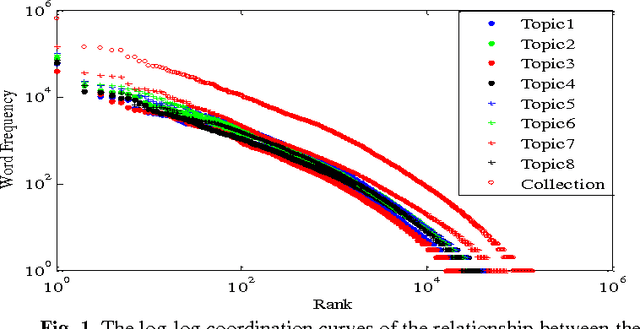
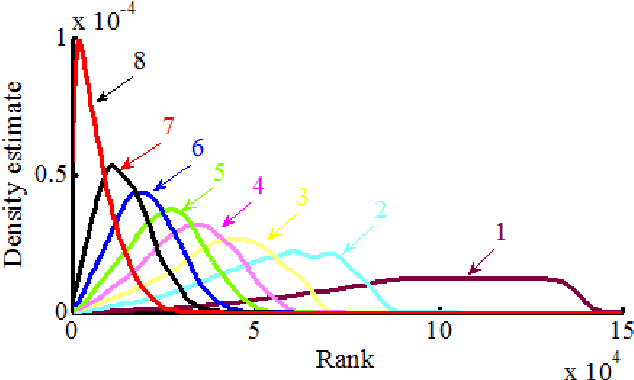

The power law is ubiquitous in natural and social phenomena, and is considered as a universal relationship between the frequency and its rank for diverse social systems. However, a general model is still lacking to interpret why these seemingly unrelated systems share great similarity. Through a detailed analysis of natural language texts and simulation experiments based on the proposed 'Hierarchical Selection Model', we found that the existence of hierarchies and human's pursuit of top hierarchy lead to the power law. Further, the power law is a statistical and emergent performance of hierarchies, and it is the universality of hierarchies that contributes to the ubiquity of the power law.
Dependency length minimization: Puzzles and Promises
Sep 15, 2015In the recent issue of PNAS, Futrell et al. claims that their study of 37 languages gives the first large scale cross-language evidence for Dependency Length Minimization, which is an overstatement that ignores similar previous researches. In addition,this study seems to pay no attention to factors like the uniformity of genres,which weakens the validity of the argument that DLM is universal. Another problem is that this study sets the baseline random language as projective, which fails to truly uncover the difference between natural language and random language, since projectivity is an important feature of many natural languages. Finally, the paper contends an "apparent relationship between head finality and dependency length" despite the lack of an explicit statistical comparison, which renders this conclusion rather hasty and improper.