 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Distribution of Dependency Distance and Hierarchical Distance in Contemporary Written Japanese and Its Influencing Factors
Apr 30, 2025To explore the relationship between dependency distance (DD) and hierarchical distance (HD) in Japanese, we compared the probability distributions of DD and HD with and without sentence length fixed, and analyzed the changes in mean dependency distance (MDD) and mean hierarchical distance (MHD) as sentence length increases, along with their correlation coefficient based on the Balanced Corpus of Contemporary Written Japanese. It was found that the valency of the predicates is the underlying factor behind the trade-off relation between MDD and MHD in Japanese. Native speakers of Japanese regulate the linear complexity and hierarchical complexity through the valency of the predicates, and the relative sizes of MDD and MHD depend on whether the threshold of valency has been reached. Apart from the cognitive load, the valency of the predicates also affects the probability distributions of DD and HD. The effect of the valency of the predicates on the distribution of HD is greater than on that of DD, which leads to differences in their probability distributions and causes the mean of MDD to be lower than that of MHD.
Statistical patterns of word frequency suggesting the probabilistic nature of human languages
Dec 01, 2020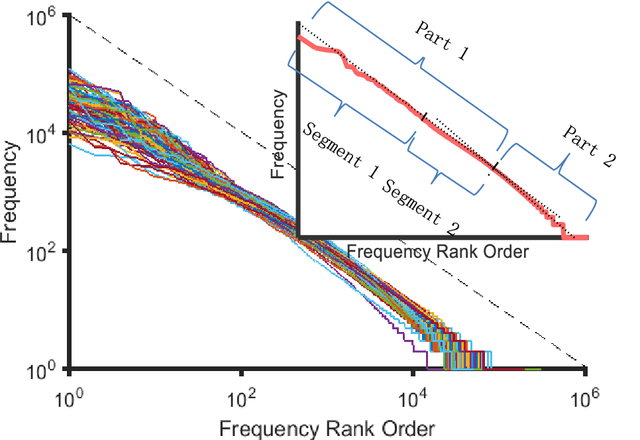
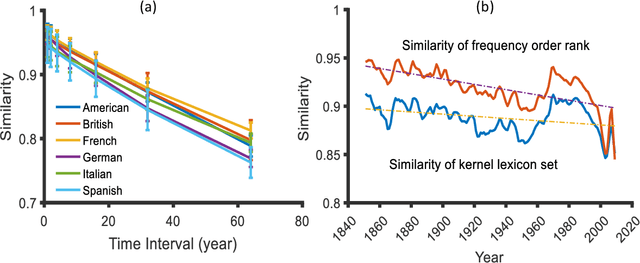
Traditional linguistic theories have largely regard language as a formal system composed of rigid rules. However, their failures in processing real language, the recent successes in statistical natural language processing, and the findings of many psychological experiments have suggested that language may be more a probabilistic system than a formal system, and thus cannot be faithfully modeled with the either/or rules of formal linguistic theory. The present study, based on authentic language data, confirmed that those important linguistic issues, such as linguistic universal, diachronic drift, and language variations can be translated into probability and frequency patterns in parole. These findings suggest that human language may well be probabilistic systems by nature, and that statistical may well make inherent properties of human languages.
Zipf's law in 50 languages: its structural pattern, linguistic interpretation, and cognitive motivation
Jul 05, 2018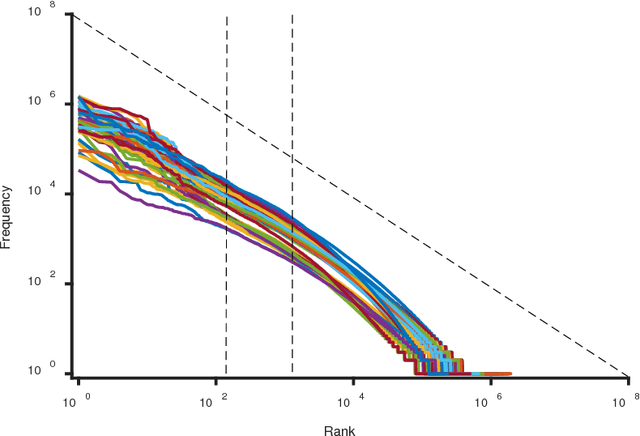
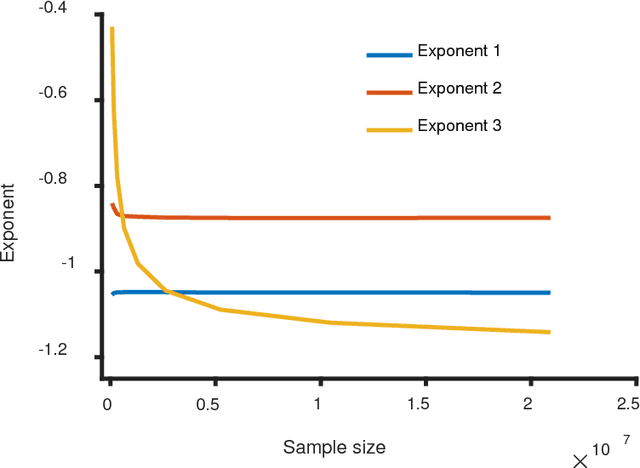
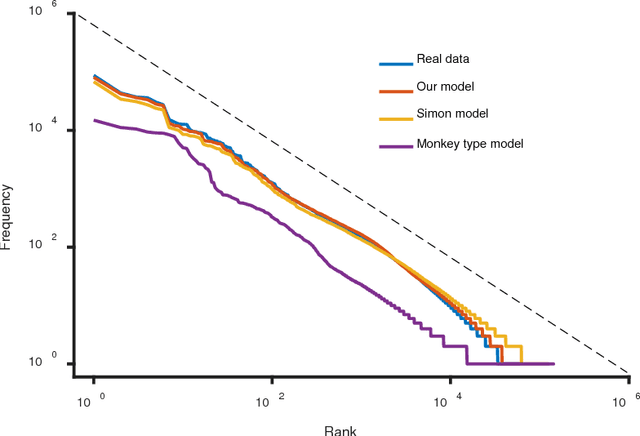
Zipf's law has been found in many human-related fields, including language, where the frequency of a word is persistently found as a power law function of its frequency rank, known as Zipf's law. However, there is much dispute whether it is a universal law or a statistical artifact, and little is known about what mechanisms may have shaped it. To answer these questions, this study conducted a large scale cross language investigation into Zipf's law. The statistical results show that Zipf's laws in 50 languages all share a 3-segment structural pattern, with each segment demonstrating distinctive linguistic properties and the lower segment invariably bending downwards to deviate from theoretical expectation. This finding indicates that this deviation is a fundamental and universal feature of word frequency distributions in natural languages, not the statistical error of low frequency words. A computer simulation based on the dual-process theory yields Zipf's law with the same structural pattern, suggesting that Zipf's law of natural languages are motivated by common cognitive mechanisms. These results show that Zipf's law in languages is motivated by cognitive mechanisms like dual-processing that govern human verbal behaviors.
The distribution of information content in English sentences
Sep 24, 2016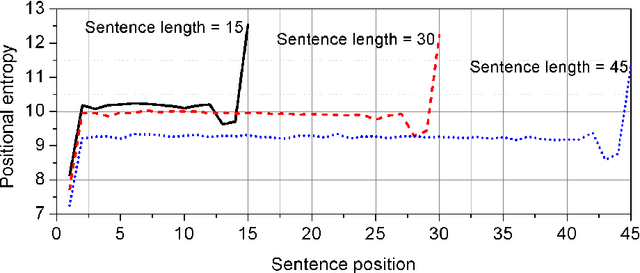
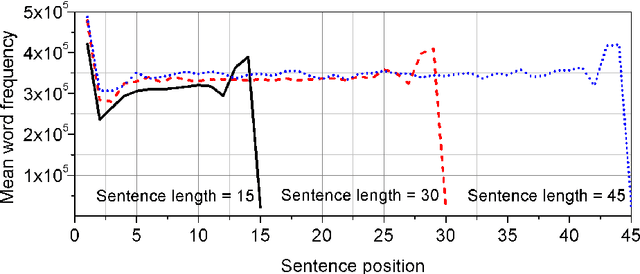
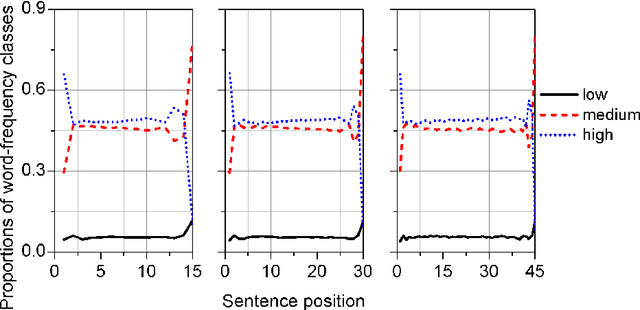
Sentence is a basic linguistic unit, however, little is known about how information content is distributed across different positions of a sentence. Based on authentic language data of English, the present study calculated the entropy and other entropy-related statistics for different sentence positions. The statistics indicate a three-step staircase-shaped distribution pattern, with entropy in the initial position lower than the medial positions (positions other than the initial and final), the medial positions lower than the final position and the medial positions showing no significant difference. The results suggest that: (1) the hypotheses of Constant Entropy Rate and Uniform Information Density do not hold for the sentence-medial positions; (2) the context of a word in a sentence should not be simply defined as all the words preceding it in the same sentence; and (3) the contextual information content in a sentence does not accumulate incrementally but follows a pattern of "the whole is greater than the sum of parts".
Existence of Hierarchies and Human's Pursuit of Top Hierarchy Lead to Power Law
Sep 24, 2016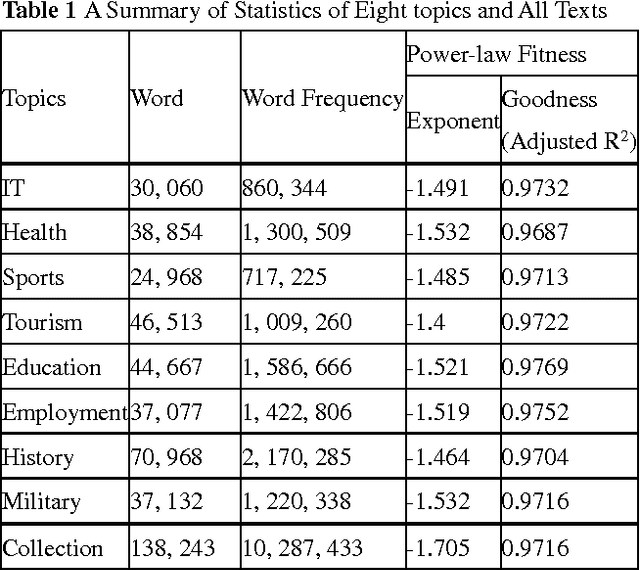
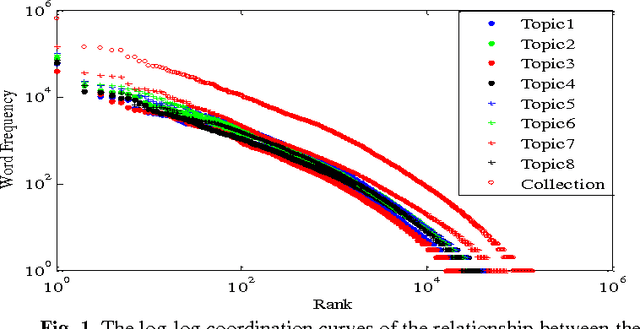
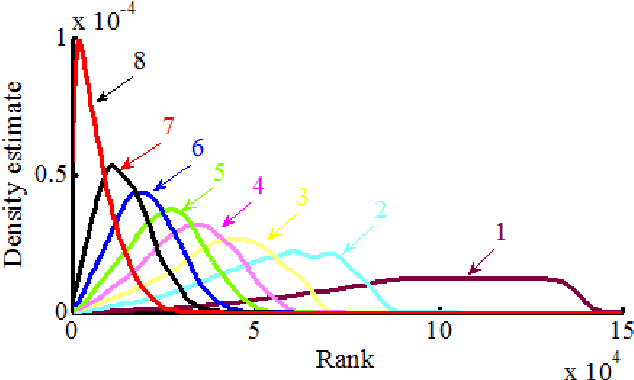

The power law is ubiquitous in natural and social phenomena, and is considered as a universal relationship between the frequency and its rank for diverse social systems. However, a general model is still lacking to interpret why these seemingly unrelated systems share great similarity. Through a detailed analysis of natural language texts and simulation experiments based on the proposed 'Hierarchical Selection Model', we found that the existence of hierarchies and human's pursuit of top hierarchy lead to the power law. Further, the power law is a statistical and emergent performance of hierarchies, and it is the universality of hierarchies that contributes to the ubiquity of the power law.