 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe distribution of information content in English sentences
Paper and Code
Sep 24, 2016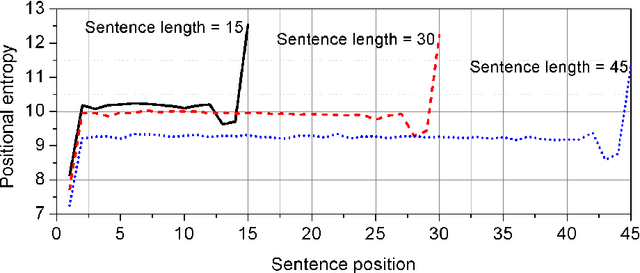
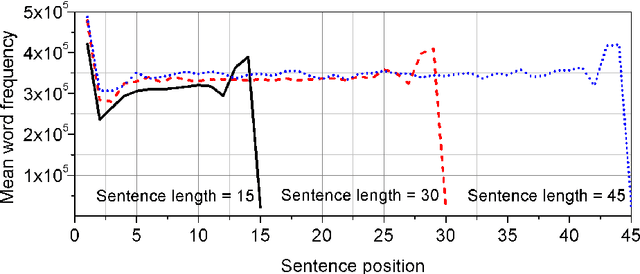
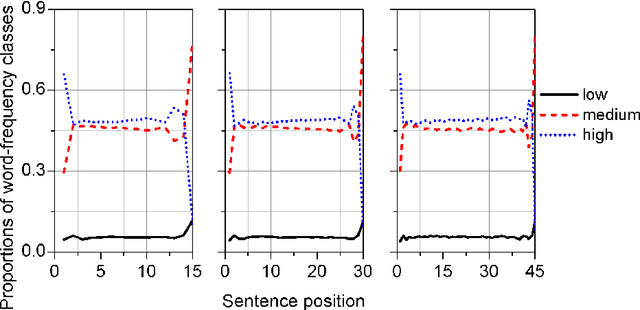
Sentence is a basic linguistic unit, however, little is known about how information content is distributed across different positions of a sentence. Based on authentic language data of English, the present study calculated the entropy and other entropy-related statistics for different sentence positions. The statistics indicate a three-step staircase-shaped distribution pattern, with entropy in the initial position lower than the medial positions (positions other than the initial and final), the medial positions lower than the final position and the medial positions showing no significant difference. The results suggest that: (1) the hypotheses of Constant Entropy Rate and Uniform Information Density do not hold for the sentence-medial positions; (2) the context of a word in a sentence should not be simply defined as all the words preceding it in the same sentence; and (3) the contextual information content in a sentence does not accumulate incrementally but follows a pattern of "the whole is greater than the sum of parts".